







 本文详细介绍了Linux系统中的进程创建,重点讨论了fork函数的使用和工作原理。fork函数用于创建子进程,子进程继承父进程的大部分资源,但通过pid可以区分父子进程。文章还提到了进程的继承机制,包括读时共享和写时复制的优化策略,避免了不必要的资源拷贝。同时,探讨了vfork和exec函数在进程初始化中的作用。
本文详细介绍了Linux系统中的进程创建,重点讨论了fork函数的使用和工作原理。fork函数用于创建子进程,子进程继承父进程的大部分资源,但通过pid可以区分父子进程。文章还提到了进程的继承机制,包括读时共享和写时复制的优化策略,避免了不必要的资源拷贝。同时,探讨了vfork和exec函数在进程初始化中的作用。
系统内置的、关于进程开发相关的api函数接口、进程创建、进程回收、进程重载等内容。
fork函数
叉子,联想进程之间的关系。
父子进程关系,Linux操作系统的进程间关系是强亲缘的,所有进程都要父进程。
大多数情况下,子进程都是通过父进程创建出来的,通过fork函数创建出来的。
并不是fork函数创建出父与子,这不就俩进程了。
而是:父进程调用fork函数,创建出子进程。
fork函数一次创建一个子进程。
fork的调用者为父进程。
亲缘关系不单单是创建的关系。
Linux系统的1号进程,是没有父进程的,开机启动的第一个进程,是所有进程的根源。
设备启动后,系统首个进程为init 1号进程,所有进程根源,它没有父进程。
ps aux查看进程。
fork函数:没参数,直接调用,返回值类型:pid_t
pid_t pid; 进程id类型,就是进程编号。
因此,调用fork函数,会将进程号返回回来。
直接pid=fork();
默认情况下,子进程会继承父进程的很多东西。
其中包括工作内容。父进程干啥子进程就干啥。
pid小的就是父进程。
unistd.h可以理解为Linux系统头文件。类似于Windows.h
父子进程继承概念
不是拷贝,但是类似。
当父进程创建子进程是,会将自身的资源数据“拷贝”给子进程,子进程可以继承到绝大多数父进程的资源、数据以及代码。
并不是真正的拷贝。
进程形态:0-3-4G,父进程创建子进程之后,其中的用户层,全部继承给子进程。有很多很多。
包括堆、栈、库、代码段、文件描述符等。
子进程既然继承了父进程,那为什么不走fork函数呢?
挑着走!
父进程,从起始到末尾,子进程:从fork之后开始,走到末尾。
这就是子进程不执行fork的原因。如果能调用那就套娃了。
父进程执行代码段内容,从起始位置执行到末尾,子进程从fork之后开始执行到末尾
避免进程创建。
如何区分父子
很多时候不希望子进程与父进程做一样的工作。
通过代码,让父进程和子进程走不同的位置。
可以通过if-else
通过fork返回值pid来实现。
Linux shift+k,跳转函数使用手册。
pid在父进程中,看到的是子进程id,但是在子进程中,id是0
可以通过pid,就能看出父子关系。
即,pid>0和pid==0这两种情况。
getpid();函数,可以获取进程id号。
perror("string"),是错误处理。

On success, the PID of the child process is returned int the parent, and 0 is returned in the child.
就是说,正常的父进程,他的pid得到的是子进程的id,那么子进程存在,pid就有数,然后进入if条件,用getpid获取父进程自己的pid号。
然后子进程进入fork函数之后,由于自己是子进程pid就是0,进入else if,然后就返回的是子进程自己的pid号。
进程函数
pid_t fork(void);创建子进程,返回子进程编号。
pid_t getpid(void);成功返回调用进程的pid
pid_t getppid(void);成功返回调用进程父进程的pid。
继承
继承类似拷贝,但是不是共享。两人用一个才是共享。
子进程修改继承的资源与父进程无关。
如果定义一个变量a,然后在子进程中修改这个a,然后结果就是:互不影响。
一个父进程可能有十几个子进程,那么就会调用很多fork函数,然后进行校验。
多进程模型创建
肯定是循环
如果是单纯的for5循环fork的话,并不是创建了5个fork
要考虑到,这个代码,子进程里也有。
因此,千万不能让子进程走循环!
让系统判断出来,我当前的进程是子进程,然后就退出循环,因此,父进程还是一如既往的创建了5个子进程,但是子进程不会再创建了。
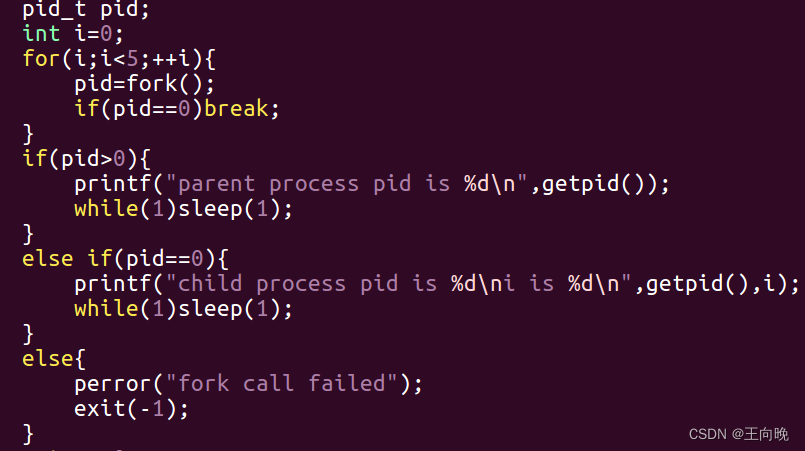
一父五子。
输出顺序有可能不对,有可能数据到缓冲区速度变慢,但是无伤大雅,我们创建出进程即可。
fork函数问题
4fork(),父进程一共创建了多少个进程?
父进程创建4个,1子创建3个,2子创建2个,3子创建1个。
11子创建2个,12子创建1个,21子创建1个,111子创建1个。
最终创建了15个进程。
fork();
fork()&&fork()||fork();
fork();父子进程的工作区划分
父进程工作区,main函数中,除了else if子进程代码段除外,其余都是父进程工作区。
子进程工作区,只有else if 里面的一段。不允许子进程踏出工作区的。
如果子进程执行完毕可以通过exit,结束子进程。
只要不是else if里的所有代码段,都是父进程工作区。
while(1)就是为了避免子进程踏出工作区。
如果不避免,则挑出else if,就会进入父进程工作区了,有冲突。
父子进程fork执行
子进程执行fork函数,但是不创建。
因此pid接收到0。
fork函数里面有两个主要方法,一个叫create,一个叫clone
create,子进程创建,是一个新生态进程,并没有初始化,无法调用。此时并没有返回值。
clone,子进程初始化。内容填充。子进程可以调用执行了,变成了就绪态。就绪态了就有返回值了,返回一个子进程pid。虽然没法执行,但是pid存在。
fork成功,返回一个0,也就是fork函数结尾返回一个0。
因此!可以了解到,如果是创建子进程的create再clone,直接从return pid走了,得到的就是子进程pid号。
而子进程,进入fork函数之后,不执行create和clone,直接拿到返回值0而已,因此子进程中的pid是0。
fork可以让两个进程执行同一个函数,做两件事。创建走前两步,执行走最后一步。
新版fork的继承机制以及fork函数的版本变更
在父进程的用户态中,当父进程创建子进程成功,会将所有的数据拷贝给子进程。
因此,子进程继承了:堆栈库、文件描述符等用户层内容。
但是有隐患,如果子进程不用这个拷贝,浪费了资源。
直接拷贝不是最好的方案,不知道子进程是否需要我们的资源。
第一版fork采用直接拷贝形式,但是如果子进程不需要使用继承数据,那么这个拷贝没有任何意义,反正是一种毫无意义的拷贝开销。
第二版:vfork函数2.0fork,这种的子进程,没有用户层内容,空的。
需要开发者自行设置初始化。
因此,想继承就fork,不想就vfork
exec函数,帮助进程初始化一个0-3G用户空间,重载用户空间。
vfork要和exec函数一起使用。vfork已经被废弃了,不用了我们。
2.0并没有解决1.0的问题
3.0解决了拷不拷贝的问题。
加入机制:读时共享,写时复制
首先fork之后,子进程将父进程的内核层拷贝,但是,这并不是完全拷贝,因为父子不可能完全一样,这就得再pcb中体现,内核层拷贝是必要的。
内核层部分拷贝,另一部分独立生成。
然后考虑用户层,就用了机制:读时共享,写时复制
用户层:读映射。
子进程可以对父进程用户层进行读访问。
对父进程的用户层进行0x10进行读映射,产生一块新的映射内存,然后子进程用户层进行对映射内存的访问。访问映射内存(读)。即:
读时共享,一行数据也不需要拷贝,可以让子进程访问父进程内容。
如果某一时刻,子进程要修改数据,就触发写时复制。
映射是不允许修改的,写访问触发,就是写时复制。你要写,就给你复制一份儿。
写时复制,子进程要修改父进程数据内容,父进程将数据拷贝给子进程一份。
而此时的复制,才是有意义的复制。
子进程刚被创建时,通过映射共享读取父进程数据,检测到子进程要修改共享数据,触发复制机制,将父进程的内容拷贝一份给子进程,通过这种策略避免无意义拷贝开销。
如果父进程创建之后修改了值,也会触发写时复制,也就是说,不管是父还是子,只要修改了就会触发写时复制。

















 939
939

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









