




 本文通过分析Kaggle上的泰坦尼克号数据集,介绍了一个经典机器学习项目,包括数据认知、特征工程、模型构建等步骤。通过对乘客等级、性别、年龄等特征的分析,揭示了生存率的关联,并展示了如何处理数据、创建新特征以提高模型性能。
本文通过分析Kaggle上的泰坦尼克号数据集,介绍了一个经典机器学习项目,包括数据认知、特征工程、模型构建等步骤。通过对乘客等级、性别、年龄等特征的分析,揭示了生存率的关联,并展示了如何处理数据、创建新特征以提高模型性能。

今天小编带领大家完整的走完一个简单机器学习小的实战项目,这个项目是Kaggle上的经典项目《泰坦尼克号之灾》,也是面试经常考的项目。大家对于泰坦尼克号一定不会陌生,但是不知道大家想过没有,泰坦尼克号上生还的都是哪些人,他们都有什么样的特征呢?
今天小编将从以下的几个点进行分析:
对于数据的认知
特征工程
进行模型的构建
1
对于数据认知
首先为什么要讲数据的认知,只有对数据进行充分的了解,你才能从大量的冰冷的数据中发现潜在的规律;只有对数据进行充分的认识,你才能从数据中提取有价值的信息。没有对于数据的了解,其他的都是空谈。那么我们首先来看一下,我们所要处理的数据吧。
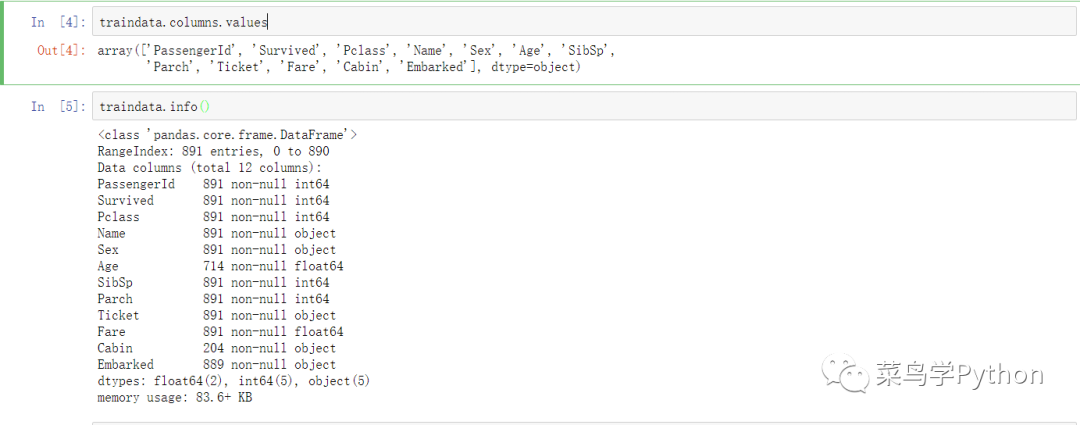
数据一共有12个维度,也就是12个特征,分别对应如下:
PassengerId => 乘客的ID
Survived=> 乘客是否存活
Pclass => 乘客的等级(1/2/3等舱位)
Name => 乘客姓名
Sex => 性别
Age => 年龄
SibSp => 堂兄弟/妹个数
Parch => 父母与小孩个数
Ticket => 船票信息
Fare => 船票的价格
Cabin => 船舱号
Embarked => 登船港口
其中Survived变量是我们需要求的变量。数据中像是Sex、Embarked属于类目型数据,数值类型的数据有:Age,Fare,SibSphe Parch。
2
从数据分布中获取信息
从数据的分布信息中,我们可以得到一些统计信息,帮助我们更快的对数据集有一个整体的理解。
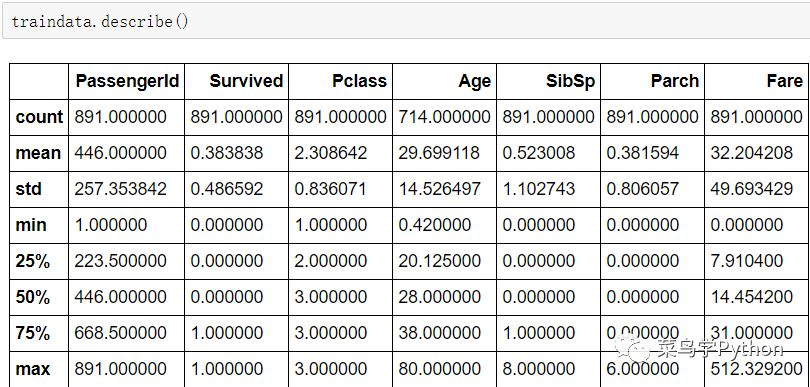
从上面的表格中,我们可以知道训练样本集中包含样本891例,891例中最终幸存的概率是38.4%左右;,二等舱和三等舱的人要多于一等舱的人;乘客的平均年龄为29.7岁左右;有超过75%的人没有与父母或者是子女一起登上泰坦尼克号。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2538
2538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









