







【本文关键词:大模型训练、LLM、数据服务市场、高质量数据集、期刊文献数据集、付费数据集、维普期刊文献数据集、垂直大模型、行业大模型】
大模型训练的挑战
在当今科技飞速发展的时代,大模型训练正面临着前所未有的挑战。算力的提升、能耗的控制、数据的获取与处理、资金的投入、技术的创新以及专业人才的培养等多方面的问题交织在一起,构成了一道复杂的难题。其中,数据获取的难度和数据的消耗速度尤为突出,成为了制约大模型训练发展的瓶颈。
随着大模型训练的不断深入,对数据的需求量也在急剧增加。然而,高质量的数据并不是随处可见的。在许多情况下,获取这些数据需要付出巨大的努力和成本。例如,医疗领域的专业数据集往往受到严格的隐私保护和法律限制,使得获取和使用这些数据变得更加困难。同样,教育、农业和科技等行业的数据也面临着类似的问题。这些行业的数据不仅难以获取,而且往往具有较高的专业性和复杂性,需要专业的团队进行采集和整理。
数据市场的现状与问题
数据市场目前正处于快速发展的阶段,其背后是各行各业对高质量数据集的强烈需求。高质量的数据不仅能提升现有模型的性能,还能推动新模型的开发,从而为行业带来革命性的进步。然而,尽管数据市场蓬勃发展,但其面临的问题同样不容忽视。数据的合法性是一个主要挑战。随着数据交易的增加,确保所有数据来源合法并符合隐私保护法规变得尤为重要。此外,数据的质量保障也是一个关键问题。高质量的数据集对训练准确的模型至关重要,但验证数据的真实性和可靠性并非易事。付费数据在这一背景下成为了一种可行的解决方案。付费数据通常经过严格的审核和认证,能够提供高质量、可靠的数据集,帮助解决合法性和质量保障等问题。
高质量数据集的重要性
在机器学习领域,“垃圾进,垃圾出”这一古老的格言尤为贴切。输入大型模型的数据质量直接影响其学习的准确性和预测能力。高质量的数据集干净、具有代表性且没有错误或偏见,对于训练强大可靠的模型至关重要。这些数据集有助于减少过拟合情况,即模型在训练数据上表现良好但在未见数据上表现不佳,这可能是由于噪音或不相关特征造成的。此外,高质量数据集还有助于提高模型的泛化能力,使其能够在各种场景下有效运作。
高质量数据集在机器学习中的作用不可忽视。它们不仅帮助减少过拟合,还能显著提升模型的泛化能力,使模型在多种不同情况下均能保持良好的性能。因此,构建和维护高质量的数据集是机器学习成功的关键之一。
公开数据集有限,导致数据枯竭的情况日益严重。据Epoch AI研究团队通过模型拟合发现,随着近年来打模型训练的快速发展,全球公开资源正在被快速消耗。据模型预测,按照现在的模型训练消耗量,人类公开文本数据将在2026年-2030年左右消耗殆尽,如果需求加剧,数据将会提前耗尽。当然公开的高质量数据将更快被消耗,据模型预测,预计会在2025年左右耗尽。
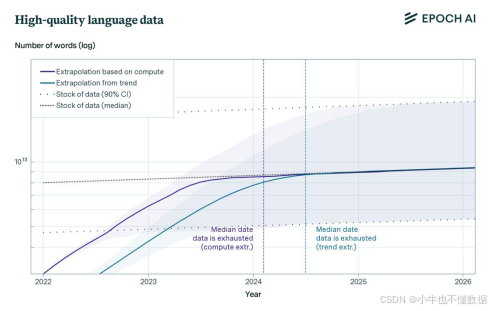
因此,想要获取更加优质的文本资源,就要付费购买。付费资源不仅能提供高质量的数据,还能确保数据来源的合法性和可靠性。如果是特殊行业的模型训练,对数据要求会更哪家严苛,如医疗行业,需要大量的诊断病例、期刊文献等;教育行业则需要更能多的学科数据、教育期刊资源数据;生物科技、农业领域均需要大量的前沿期刊数据作为基础进行训练,才能更好的满足未来的使用场景。因此,期刊等付费资源在未来可能是及其重要的文本资源。但这类资源恰巧是付费资源,公共渠道获取的资源量极为有限。
国内目前主流的期刊资源数据库商就是知网、万方、维普。仅公开页面检索发现,维普智图(维普资讯旗下子公司)近期发布了用于大模型训练的期刊文献数据集,包括期刊文献元数据及原文数据集,维普智图提供镜像部署及API获取服务。这也表明,维普开始布局大模型训练数据服务市场。相信不就的将来,除维普外的其他期刊服务商也将会推出不同形式的大模型期刊文献数据集。
结论
总的来说,大模型训练面临着诸多挑战,但同时也存在着巨大的机遇。在当前的技术环境下,数据资源成为了制约大模型发展的关键因素。随着计算能力的不断提升和算法的不断优化,大模型对于数据的需求量也在急剧增加。然而,公开数据集的有限性以及高质量数据的稀缺性,导致了数据获取的难度与日俱增。为了应对这一挑战,付费数据市场逐渐兴起,成为解决数据瓶颈的一种可能方式。
付费数据由于其较高的可靠性和质量保障,正在成为许多企业和研究机构的首选。通过引入付费数据,可以有效缓解公开数据集不足的问题,从而加快大模型的训练速度并提高模型的精度。尽管成熟的算法能够在一定程度上弥补数据质量的不足,但高质量数据集仍然是推动模型性能提升的重要因素。
通识大模型市场竞争日益激烈,行业大模型或垂直大模型或成为新的竞争高地。行业或垂直领域的大模型训练除了基本百科知识外,更需要大量的专业数据支持。专业数据主要来源于行业自身语料积累或期刊文献资源,行业自身语料积累有较高的隐蔽性,涉及用户隐私及数据安全问题。而期刊文献资源为公开发表文章,且具有行业内权威认证,是非常好的训练语料。由于期刊公开数据集的限制,期刊版权基本集中在期刊数据库商手中,因此,付费必不可免。如能抢先获取高质量的期刊文献数据集,用于大语言模型训练,或能在模型训练中抢得先机。
引用:
- Villalobos,,Pablo等.Position: Will we run out of data? Limits of LLM scaling based on human-generated data[],2024.
- 维普智图数据商城官网数据:数据商城
- 艾瑞咨询,《人工智能行业:2024年中国AI基础数据服务研究报告》
【网络公开数据整理,侵删】

















 852
852

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









