







目录
1.分治递归
1. 至少有K个重复字符的最长子串
找到给定字符串(由小写字符组成)中的最长子串 T , 要求 T 中的每一字符出现次数都不少于 k 。输出 T 的长度。
示例 1:
输入:
s = "aaabb", k = 3
输出:
3
最长子串为 "aaa" ,其中 'a' 重复了 3 次。
示例 2:
输入:
s = "ababbc", k = 2
输出:
5
最长子串为 "ababb" ,其中 'a' 重复了 2 次, 'b' 重复了 3 次。
作者:力扣 (LeetCode)
链接:https://leetcode-cn.com/leetbook/read/top-interview-questions/xafdmc/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
题解:哈希表+分治递归
解题思路
先用hash表统计s中每个字符出现的次数,显然如果字符c出现的次数小于k,c必然不在最长子串里面,根据这个特性可以将原始s分割成多个子串递归地求解问题,我们用一个split数组依次来存放每个分割点的索引,对每个分割区间同样求解该问题(多路的分治问题),并取结果的最大值保存在变量ans中,此处有一个小trick(如果当前求解的子串长度比已存在的ans还要小,则没有必要求解该区间,这样可以减少不必要的计算),最后递归的结束点就是当前求解的字符串s符合最长子串的要求。
class Solution {
public:
int longestSubstring(string s, int k) {
if(k==0)return 0;
if(k==1)return s.size();
unordered_map<char,int> hashmap;
vector<int> split;
for(auto i:s)hashmap[i]++;
//restore the split node
for(int i=0;i<s.size();++i)
{
if(hashmap[s[i]]<k)split.push_back(i);
}
if(split.size()==0)return s.size();
split.push_back(s.size());//anchor tail
//temp var to restore left index
int left = 0,ans = 0;
for(int i =0;i<split.size();++i)
{
int len = split[i]-left;
if(len>ans)ans = max(ans,longestSubstring(s.substr(left,split[i]-1),k));
left = split[i]+1;
}
return ans;
}
};复杂度
时间复杂度:O(N),构造前缀和数组需要 O(N),分治算法划分区间不会出现重复计算,只需要O(N),因此总的时间复杂度为 O(N)。
空间复杂度:O(N),对于每个起点都要申请 26 字符大小哈希表(比 hash 表快)。
2. 最长连续序列
给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
进阶:你可以设计并实现时间复杂度为 O(n) 的解决方案吗?
示例 1:
输入:nums = [100,4,200,1,3,2]
输出:4
解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
示例 2:
输入:nums = [0,3,7,2,5,8,4,6,0,1]
输出:9
提示:
0 <= nums.length <= 104
-109 <= nums[i] <= 109
作者:力扣 (LeetCode)
链接:https://leetcode-cn.com/leetbook/read/top-interview-questions/x2xmre/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
题解1:分治迭代
利用分治迭代的原理将原始数组排序后,根据其是否连续将其分为n个子段,检测每个子段的长度得到最长连续序列。
#include <algorithm>
using namespace std;
//sort()头文件引用
class Solution {
public:
int longestConsecutive(vector<int>& nums) {
int len =nums.size();
if(len<=0)return 0;
if(len==1)return 1;
sort(nums.begin(),nums.end());
int first=0, ans =0;
int red = 0;//计数重复的数字
int pre = nums[0];
nums.push_back(INT_MAX);//推入一个最大值使得分段完整
for(int i=1; i<nums.size();++i)
{
if(nums[i]==pre)
{red++;}
else if((nums[i]-pre)!=1)
{
int temp = i -first-red;
if(temp>ans) ans = temp;
first = i;
red = 0;
}
pre = nums[i];
}
return ans;
}
};复杂度:
时间复杂度:O(nlogn+n)=O(nlogn),排序算法时间复杂度最低为O(nlogn),最后遍历一次O(n)。
空间复杂度:O(1),不需要额外空间。
题解2:哈希表时间优化:
我们考虑枚举数组中的每个数 x,考虑以其为起点,不断尝试匹配 x+1,x+2,⋯ 是否存在,假设最长匹配到了 x+y,那么以 x 为起点的最长连续序列即为 x,x+1,x+2,⋯,x+y,其长度为 y+1,我们不断枚举并更新答案即可。
对于匹配的过程,暴力的方法是 O(n) 遍历数组去看是否存在这个数,但其实更高效的方法是用一个哈希表存储数组中的数,这样查看一个数是否存在即能优化至 O(1) 的时间复杂度。
仅仅是这样我们的算法时间复杂度最坏情况下还是会达到 O(n^2)(即外层需要枚举 O(n)个数,内层需要暴力匹配 O(n) 次),无法满足题目的要求。但仔细分析这个过程,我们会发现其中执行了很多不必要的枚举,如果已知有一个 x,x+1,x+2,⋯,x+y 的连续序列,而我们却重新从 x+1,x+2或者是 x+y处开始尝试匹配,那么得到的结果肯定不会优于枚举 x 为起点的答案,因此我们在外层循环的时候碰到这种情况跳过即可。
那么怎么判断是否跳过呢?由于我们要枚举的数 x 一定是在数组中不存在前驱数x−1 的,不然按照上面的分析我们会从 x−1 开始尝试匹配,因此我们每次在哈希表中检查是否存在x−1 即能判断是否需要跳过了。
class Solution {
public:
int longestConsecutive(vector<int>& nums) {
unordered_set<int> hashset;
for(const int& i:nums)
{
hashset.insert(i);
}
int ans =0;
for(const int& i:hashset)
{
if(!hashset.count(i-1))//检测节点i是否为连续数开头,即i-1不存在于哈希表中
{
int temp =0,start = i;
while(hashset.count(start++))
{
temp++;
}
ans = max(temp,ans);
}
}
return ans;
}
};复杂度:
时间复杂度:O(n),其中 n 为数组的长度。具体分析已在上面正文中给出。
空间复杂度:O(n)。哈希表存储数组中所有的数需要 O(n) 的空间。
3. 二叉树中的最大路径和
解题思路:分治递归
分治递归的关键是子结构和决策(量) ,找到最优子结构OSP(小型二叉树)和决策量(最大路径长LPL),自顶向下递归得到结果。
二叉树 abc,a 是根结点(递归中的 root),bc 是左右子结点(LPL(b)代表其递归后的最优解)。
最大的路径子结构,可能的路径情况:
a
/ \
b c
- b + a + c。
- b + a + a 的父结点。
- a + c + a 的父结点。
其中情况 1,表示如果不联络父结点的情况,或本身是根结点的情况。
这种情况是没法递归的,但是结果有可能是全局最大路径和。
情况 2 和 3,递归时计算 a+b 和 a+c,选择一个更优的方案返回,也就是上面说的递归后的最优解啦。
另外结点有可能是负值,最大和肯定就要想办法舍弃负值(max(0, x))(max(0,x))。
但是上面 3 种情况,无论哪种,a 作为联络点,都不能够舍弃。
代码中使用 val 来记录全局最大路径和。
最优子结构OSP
LPL(root) = max(LPL(root),root->val+max(LPL(root->left),LPL(Root->right)))
所要做的就是递归,递归时记录好全局最大和,返回联络最大和。
代码:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int maxPathSum(TreeNode* root) {
if(root==nullptr)return 0;
//Trick 用一个值存储最大值能够避免递归内的逻辑处理
int val = INT_MIN;
pathGain(root,val);
return val;
}
int pathGain(TreeNode* root,int& val)
{
if(root==nullptr)return 0;
// 递归计算左右子节点的最大贡献值 情况 2,3
// 只有在最大贡献值大于 0 时,才会选取对应子节点
int lv =max(pathGain(root->left,val),0);
int rv = max(pathGain(root->right,val),0);
// 节点的最大路径和取决于该节点的值与该节点的左右子节点的最大贡献值
// 更新答案 情况 1
val = max(val,root->val+rv+lv);
return root->val+max(lv,rv);
}
};复杂度:
时间复杂度:O(H),H为树高。
空间复杂度:O(1),只需要常量复杂度。
2. 动态规划
1. 打家劫舍【典型动态规划问题】
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你 不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
示例 1:
输入:[1,2,3,1]
输出:4
解释:偷窃 1 号房屋 (金额 = 1) ,然后偷窃 3 号房屋 (金额 = 3)。
偷窃到的最高金额 = 1 + 3 = 4 。
示例 2:输入:[2,7,9,3,1]
输出:12
解释:偷窃 1 号房屋 (金额 = 2), 偷窃 3 号房屋 (金额 = 9),接着偷窃 5 号房屋 (金额 = 1)。
偷窃到的最高金额 = 2 + 9 + 1 = 12 。
提示:
0 <= nums.length <= 100
0 <= nums[i] <= 400
作者:力扣 (LeetCode)
链接:https://leetcode-cn.com/leetbook/read/top-interview-questions/x25oeg/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
题解:动态规划
动态规划的的四个解题步骤是:
- 定义子问题
- 写出子问题的递推关系
- 确定 DP 数组的计算顺序
- 空间优化(可选)
步骤一:定义子问题
动态规划实际上就是通过求这一堆子问题的解,来求出原问题的解。这要求子问题需要具备两个性质:
- 原问题要能由子问题表示。
- 一个子问题的解要能通过其他子问题的解求出。
子问题是可以参数化的, 例如这道小偷问题中,f(k)可以由 f(k-1)和 f(k-2)求出.
步骤二:写出子问题的递推关系(即最优子结构)
这一步是求解动态规划问题最关键的一步。然而,这一步也是最无法在代码中体现出来的一步。在做题的时候,最好把这一步的思路用注释的形式写下来。做动态规划题目不要求快,而要确保无误。否则,写代码五分钟,找 bug 半小时,岂不美哉?
我们来分析一下这道小偷问题的递推关系
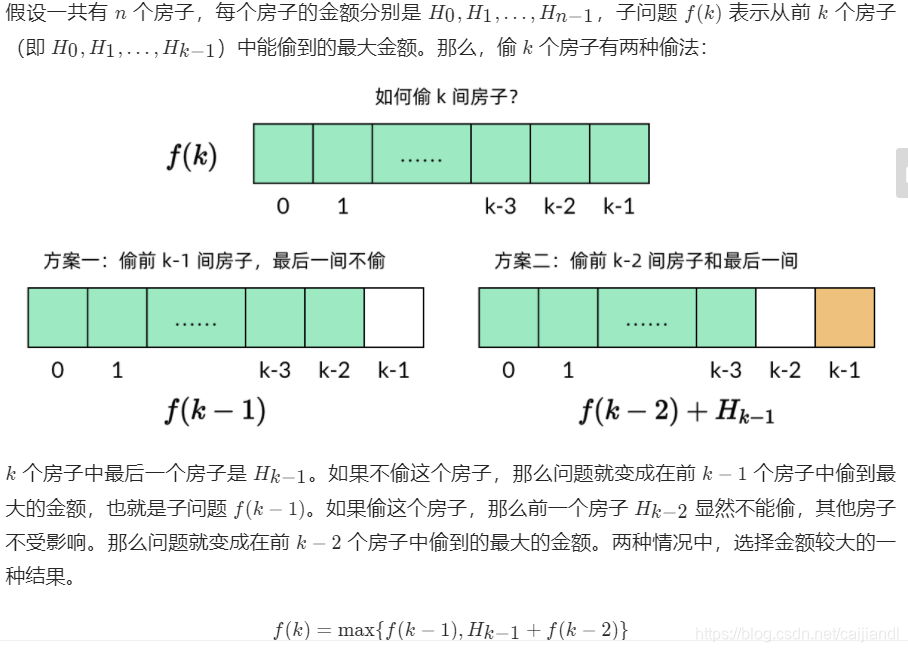
转移公式:f(k)=max{f(k−1),nums(k−1)+f(k−2)}
在写递推关系的时候,要注意写上 k=0k=0 和 k=1k=1 的基本情况:
当 k=0 时,没有房子,所以 f(0) = 0。
当 k=1 时,只有一个房子,偷这个房子即可,所以 f(1) = nums(0)。
这样才能构成完整的递推关系,后面写代码也不容易在边界条件上出错。
步骤三:确定 DP 数组的计算顺序
在确定了子问题的递推关系之后,下一步就是依次计算出这些子问题了。在很多教程中都会写,动态规划有两种计算顺序,
一种是自顶向下的、使用备忘录的递归方法,
一种是自底向上的、使用 dp 数组的循环方法。
不过在普通的动态规划题目中,99% 的情况我们都不需要用到备忘录方法,所以我们最好坚持用自底向上的 dp 数组。
DP 数组也可以叫”子问题数组”,因为 DP 数组中的每一个元素都对应一个子问题。如下图所示,dp[k] 对应子问题 f(k),即偷前 k 间房子的最大金额。
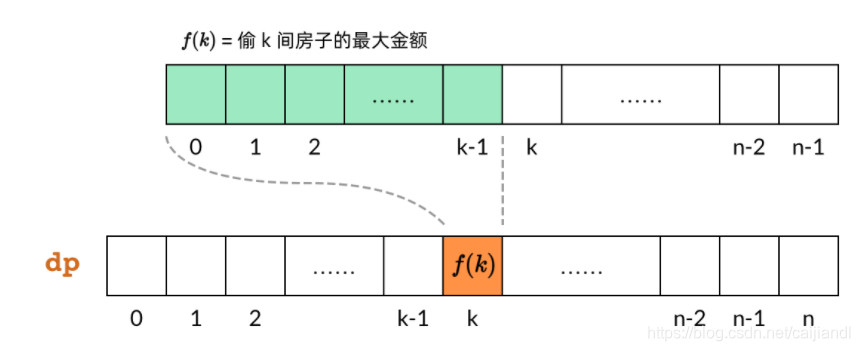
那么,只要搞清楚了子问题的计算顺序,就可以确定 DP 数组的计算顺序。
对于小偷问题,我们分析子问题的依赖关系,发现每个 f(k) 依赖 f(k-1) 和 f(k-2)。也就是说,dp[k] 依赖 dp[k-1] 和 dp[k-2]。
那么,既然 DP 数组中的依赖关系都是向右指的,DP 数组的计算顺序就是从左向右。这样我们可以保证,计算一个子问题的时候,它所依赖的那些子问题已经计算出来了。
确定了 DP 数组的计算顺序之后,我们就可以写出题解代码了:
class Solution {
public:
int rob(vector<int>& nums) {
int len = nums.size();
if(len==0)return 0;
vector<int> dp(len+1,0);
dp[0] = 0;
dp[1] = nums[0];
for(int i =2;i<=len;++i)
{
dp[i] = max(dp[i-1],dp[i-2]+nums[i-1]);
}
return dp[len];
}
};步骤四:空间优化
空间优化是动态规划问题的进阶内容了。动态规划 + 滚动数组可以完成此题优化解。
空间优化的基本原理是,很多时候我们并不需要始终持有全部的 DP 数组。对于小偷问题,我们发现,最后一步计算 f(n)的时候,实际上只用到了 f(n−1) 和 f(n−2) 的结果。n−3 之前的子问题,实际上早就已经用不到了。那么,我们可以只用两个变量保存两个子问题的结果,就可以依次计算出所有的子问题。
这样一来,空间复杂度也从 O(n) 降到了 O(1)。优化后的代码如下所示:
class Solution {
public:
int rob(vector<int>& nums) {
int len = nums.size();
if(len==0)return 0;
int first, second;
first = 0;
second = nums[0];
for(int i =2;i<=len;++i)
{
int temp = second;
second = max(second,first+nums[i-1]);
first = temp;
}
return second;
}
};复杂度:
时间复杂度:O(n),n为数组大小。
空间复杂度:O(1),只需要常量复杂度。
2. 完全平方数
给定正整数 n,找到若干个完全平方数(比如 1, 4, 9, 16, ...)使得它们的和等于 n。你需要让组成和的完全平方数的个数最少。
给你一个整数 n ,返回和为 n 的完全平方数的 最少数量 。
完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而 3 和 11 不是。
示例 1:
输入:n = 12
输出:3
解释:12 = 4 + 4 + 4
示例 2:输入:n = 13
输出:2
解释:13 = 4 + 9
提示:1 <= n <= 104
作者:力扣 (LeetCode)
链接:https://leetcode-cn.com/leetbook/read/top-interview-questions/x2959v/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
题解:解法1:动态规划
1. 定义子问题 2. 写出子问题的递推关系(关键)
整数n一定由f(n)个平方数组成,则f(n)=min(f(n-k) + 1) ∀k∈square numbers
3. 确定 DP 数组的计算顺序
使用DP数组自底向上完成递归,我们从数字 1 循环到 n,计算每个数字 i 的解(即 numSquares(i))。每次迭代中,我们将 numSquares(i) 的结果保存在 dp[i] 中。
4. 空间优化(可选)
显而易见,在向上递归时计算并存储了许多不必要的中间量
class Solution {
public:
int numSquares(int n) {
vector<int> sqts;
for(int i =1;(i*i)<=n;++i)
{
sqts.push_back(i*i);
}
vector<int> dp(n+1,INT_MAX);
dp[0] = 0;
dp[1] = 1;
for(int i = 2;i<=n;++i)
{
for(const int& sqt:sqts)
{
if(i-sqt<0)break;
dp[i] = min(dp[i],dp[i-sqt]+1);//任意k 属于n的平方和数组
}
}
return dp[n];
}
};复杂度:
时间复杂度:O(sqrt{n}*n),在主步骤中,我们有一个嵌套循环,其中外部循环是 n 次迭代,而内部循环最多需要 sqrt{n} 迭代。
空间复杂度:O(n),使用了一个一维数组 dp。
题解:解法2:贪心枚举
递归解决方法为我们理解问题提供了简洁直观的方法。我们仍然可以用递归解决这个问题。为了改进暴力枚举解决方案,
我们可以在递归中加入贪心,即寻找子结构的局部最优解。我们可以将枚举重新格式化如下:
从一个数字到多个数字的组合开始,一旦我们找到一个可以组合成给定数字 n 的组合,那么我们可以说我们找到了最小的组合,为此我们贪心的从小到大的枚举组合。
为了更好的解释,我们首先定义一个名为 is_divided_by(n, count) 的函数,该函数返回一个布尔值,表示数字 n 是否可以被一个 count个平方数 组合,而不是像动态规划函数 numSquares(n) 返回组合的确切大小。
与递归函数 numSquare(n) 不同,is_divided_by(n, count) 的递归过程可以归结为底部情况(即 count==1)更快。
class Solution {
public:
bool isdivided_by(int n, int count)
{
if(count<=1)
{
for(int i=1;i*i<=n;++i)
{
if(i*i==n)return true;
}
return false;
}
else{
for(int i=1;i*i<=n;++i)
{
if(isdivided_by(n-i*i,count-1)) return true;
}
return false;
}
}
int numSquares(int n) {
for(int i=1;i<=n;++i)
{
if(isdivided_by(n,i))
return i;
}
return 0;
}
};复杂度:
时间复杂度:![]() ,其中 h 是可能发生的最大递归次数。你可能会注意到,上面的公式实际上类似于计算完整 N 元数种结点数的公式。事实上,算法种的递归调用轨迹形成一个 N 元树,其中 N 是 square_nums 种的完全平方数个数。即,在最坏的情况下,我们可能要遍历整棵树才能找到最终解。
,其中 h 是可能发生的最大递归次数。你可能会注意到,上面的公式实际上类似于计算完整 N 元数种结点数的公式。事实上,算法种的递归调用轨迹形成一个 N 元树,其中 N 是 square_nums 种的完全平方数个数。即,在最坏的情况下,我们可能要遍历整棵树才能找到最终解。
空间复杂度:O(sqrt(n)),我们存储了一个列表 square_nums,我们还需要额外的空间用于递归调用堆栈。但正如我们所了解的那样,调用轨迹的大小不会超过 4。
解法四:贪心 + BFS(广度优先搜索)
正如上述贪心算法的复杂性分析种提到的,调用堆栈的轨迹形成一颗 N 元树,其中每个结点代表 is_divided_by(n, count) 函数的调用。基于上述想法,我们可以把原来的问题重新表述如下:
给定一个 N 元树,其中每个节点表示数字 n 的余数减去一个完全平方数的组合,我们的任务是在树中找到一个节点,该节点满足两个条件:
(1) 节点的值(即余数)也是一个完全平方数。
(2) 在满足条件(1)的所有节点中,节点和根之间的距离应该最小。
下面是这棵树的样子。
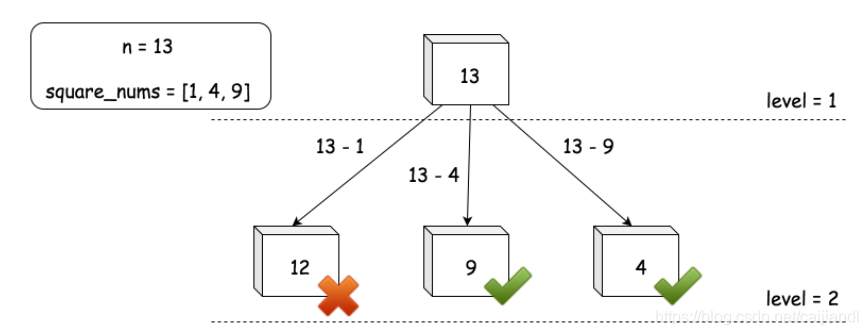
在前面的方法3中,由于我们执行调用的贪心策略,我们实际上是从上到下逐层构造 N 元树。我们以 BFS(广度优先搜索)的方式遍历它。在 N 元树的每一级,我们都在枚举相同大小的组合。
遍历的顺序是 BFS,而不是 DFS(深度优先搜索),这是因为在用尽固定数量的完全平方数分解数字 n 的所有可能性之前,我们不会探索任何需要更多元素的潜在组合。
class Solution {
public:
int numSquares(int n) {
if(n==0)return 0;
queue<int> queue;// store all nodes which are waiting to be processed
unordered_set<int> visited;
int height = 0;
queue.push(n);
//BFS Search the shortest path
while(!queue.empty())
{
height++;
int len = queue.size();//搜索下一列
for(int i=0;i<len;i++)
{
int temp = queue.front();
queue.pop();
for(int j=1;j<sqrt(temp)+1;++j)
{
int next = temp-j*j;
if(next==0) return height;
if(next>0&&!visited.count(next))
{
queue.push(next);
visited.insert(next);
}
}
}
}
return 0;
}
};
3. 最长上升子序列
给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。
子序列是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7] 是数组 [0,3,1,6,2,2,7] 的子序列。
示例 1:输入:nums = [10,9,2,5,3,7,101,18]
输出:4
解释:最长递增子序列是 [2,3,7,101],因此长度为 4 。
示例 2:输入:nums = [0,1,0,3,2,3]
输出:4
示例 3:输入:nums = [7,7,7,7,7,7,7]
输出:1
提示:
1 <= nums.length <= 2500
-104 <= nums[i] <= 104
进阶:
你可以设计时间复杂度为 O(n2) 的解决方案吗?
你能将算法的时间复杂度降低到 O(n log(n)) 吗?
作者:力扣 (LeetCode)
链接:https://leetcode-cn.com/leetbook/read/top-interview-questions/x29fxj/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
解法1:动态规划
1. 定义子问题
定义 dp[i]为考虑前 i 个元素,以第 i个数字结尾的最长上升子序列的长度,注意nums[i] 必须被选取。
2. 写出子问题的递推关系(关键)
我们从小到大计算 dp[i]数组的值,在计算 dp[i] 之前,我们已经计算出 dp[0…i−1] 的值,则状态转移方程为:
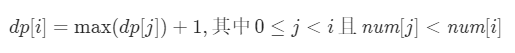
3. 确定 DP 数组的计算顺序
即考虑往 dp[0…i−1] 中最长的上升子序列后面再加一个 nums[i]。由于 dp[j] 代表nums[0…j] 中以nums[j] 结尾的最长上升子序列,所以如果能从 dp[j] 这个状态转移过来,那么nums[i] 必然要大于nums[j],才能将 nums[i] 放在nums[j] 后面以形成更长的上升子序列。
最后,整个数组的最长上升子序列即所有 dp[i] 中的最大值。
LIS length =max(dp[i]),其中0≤i<n
4. 空间优化(可选)
显而易见,在向上递归时计算并存储了许多不必要的中间量
class Solution {
public:
int lengthOfLIS(vector<int>& nums) {
if(nums.size()==1)return 1;
//init 所以子段最短为1
vector<int> dp(nums.size()+1,1);
dp[0] = 0;
dp[1] = 1;
for(int i=2;i<=nums.size();++i)
{
for(int j=1;j<i;++j)
{
if(nums[i-1]>nums[j-1])
{
dp[i] = max(dp[i],dp[j]+1);
}
}
}
// get the max of LIS
int ans = 0;
for(auto i:dp)
{
if(i>ans)ans = i;
}
return ans;
}
};
复杂度:

解法二:二分贪心
考虑一个简单的贪心,如果我们要使上升子序列尽可能的长,则我们需要让序列上升得尽可能慢,因此我们希望每次在上升子序列最后加上的那个数尽可能的小。
基于上面的贪心思路,我们维护一个数组 d[i],表示长度为 i 的最长上升子序列的末尾元素的最小值,用len 记录目前最长上升子序列的长度,起始时len 为 11,d[1]=nums[0]。
同时我们可以注意到 d[i] 是关于 i 单调递增的。因为如果 d[j]≥d[i] 且 j < i,我们考虑从长度为 i 的最长上升子序列的末尾删除i−j 个元素,那么这个序列长度变为 j ,且第 j 个元素 x(末尾元素)必然小于 d[i],也就小于 d[j]。那么我们就找到了一个长度为 j 的最长上升子序列,并且末尾元素比 d[j] 小,从而产生了矛盾。因此数组d[] 的单调性得证。
我们依次遍历数组nums[] 中的每个元素,并更新数组 d[] 和 len 的值。如果 nums[i]>d[len] 则更新 len = len + 1,否则在 d[1…len]中找满足 d[i−1]<nums[j]<d[i] 的下标 i,并更新 d[i]=nums[j].
根据 dd 数组的单调性,我们可以使用二分查找寻找下标 ii,优化时间复杂度。
最后整个算法流程为:
设当前已求出的最长上升子序列的长度为len(初始时为 11),从前往后遍历数组 nums,在遍历到 nums[i] 时:
如果nums[i]>d[len] ,则直接加入到 d 数组末尾,并更新 len=len+1;
否则,在 d 数组中二分查找,找到第一个比 nums[i] 小的数 d[k] ,并更新d[k+1]=nums[i]。
class Solution {
public:
int lengthOfLIS(vector<int>& nums) {
if(nums.size()==1)return 1;
vector<int> LIS;
for(const int& i:nums)
{
if(LIS.size()==0)LIS.push_back(i);
if(i>LIS.back())LIS.push_back(i);
else if(i==LIS.back())
{
continue;
}else
{
int left=0,right =LIS.size()-1;
//二分法搜索
while(left<right)
{
int mid = (left+right)/2;
if(LIS[mid]<i)
{
left = mid+1;
}else
{
right = mid;
}
}
LIS[left] = i;
}
}
return LIS.size();
}
};复杂度:
时间复杂度:O(nlogn)。数组nums 的长度为 nn,我们依次用数组中的元素去更新 LIS数组,而更新 LIS数组时需要进行 O(logn) 的二分搜索,所以总时间复杂度为 O(nlogn)。
空间复杂度:O(n),需要额外使用长度为 n 的 LIS 数组。
4. 零钱兑换
给定不同面额的硬币 coins 和一个总金额 amount。编写一个函数来计算可以凑成总金额所需的最少的硬币个数。如果没有任何一种硬币组合能组成总金额,返回 -1。
你可以认为每种硬币的数量是无限的。
示例 1:
输入:coins = [1, 2, 5], amount = 11
输出:3
解释:11 = 5 + 5 + 1
示例 2:输入:coins = [2], amount = 3
输出:-1
示例 3:输入:coins = [1], amount = 0
输出:0
示例 4:输入:coins = [1], amount = 1
输出:1
示例 5:输入:coins = [1], amount = 2
输出:2
提示:
1 <= coins.length <= 12
1 <= coins[i] <= 231 - 1
0 <= amount <= 104
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/coin-change
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
题解1:动态规划
1. 定义子问题
首先,我们定义:
dp[n]:组成金额 n 所需的最少硬币数量
[val0…valn−1] :可选的 n 枚硬币面额值
2. 写出子问题的递推关系(关键)

3. 确定 DP 数组的计算顺序
通过使用dp数组存储中间值,我们可以自下而上地计算得到dp[amount]的值,即为最终结果。
4. 空间优化(可选)
无
class Solution {
public:
int coinChange(vector<int>& coins, int amount) {
if(amount==0)return 0;
vector<int> dp(amount+1,-1);
dp[0] = 0;//边界条件
for(int i=1;i<=amount;++i)
{
int temp = INT_MAX;
for(auto val:coins)
{
if(i-val>=0&&dp[i-val]!=-1)
{
temp = dp[i-val]+1<temp?dp[i-val]+1:temp;
dp[i] = temp;
}
}
}
return dp[amount];
}
};复杂度:

5. 矩阵中的最长递增路径
给定一个 m x n 整数矩阵 matrix ,找出其中 最长递增路径 的长度。
对于每个单元格,你可以往上,下,左,右四个方向移动。 你 不能 在 对角线 方向上移动或移动到 边界外(即不允许环绕)。
示例 1:
输入:matrix = [[9,9,4],[6,6,8],[2,1,1]]
输出:4
解释:最长递增路径为 [1, 2, 6, 9]。
示例 2:
输入:matrix = [[3,4,5],[3,2,6],[2,2,1]]
输出:4
解释:最长递增路径是 [3, 4, 5, 6]。注意不允许在对角线方向上移动。
示例 3:输入:matrix = [[1]]
输出:1
提示:
m == matrix.length
n == matrix[i].length
1 <= m, n <= 200
0 <= matrix[i][j] <= 231 - 1
作者:力扣 (LeetCode)
链接:https://leetcode-cn.com/leetbook/read/top-interview-questions/x2osfr/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
题解1:记忆化深度优先搜索DFS
问题转化成在有向图中寻找最长路径。
将矩阵看成一个有向图,每个单元格对应图中的一个节点,如果相邻的两个单元格的值不相等,则在相邻的两个单元格之间存在一条从较小值指向较大值的有向边。
深度优先搜索是非常直观的方法。从一个单元格开始进行深度优先搜索,即可找到从该单元格开始的最长递增路径。对每个单元格分别进行深度优先搜索之后,即可得到矩阵中的最长递增路径的长度。
但是如果使用朴素深度优先搜索,时间复杂度是指数级,会超出时间限制,因此必须加以优化。
朴素深度优先搜索的时间复杂度过高的原因是进行了大量的重复计算,同一个单元格会被访问多次,每次访问都要重新计算。由于同一个单元格对应的最长递增路径的长度是固定不变的,因此可以使用记忆化的方法进行优化。用矩阵 memo 作为缓存矩阵,已经计算过的单元格的结果存储到缓存矩阵中。
使用记忆化深度优先搜索,当访问到一个单元格 (i,j) 时,如果memo[i][j] !=0,说明该单元格的结果已经计算过,则直接从缓存中读取结果,如果 memo[i][j]=0,说明该单元格的结果尚未被计算过,则进行DFS搜索,并将计算得到的结果存入缓存中。
遍历完矩阵中的所有单元格之后,即可得到矩阵中的最长递增路径的长度。
class Solution {
private:
vector<vector<int>> dir = {{1,0},{-1,0},{0,1},{0,-1}};
int row,column=0;
int DFS(vector<vector<int>>& matrix,vector<vector<int>>& memo,int r,int c)
{
//if visisted
if(memo[r][c]!=0)
{
return memo[r][c];
}
//not visisted
memo[r][c]++;
for(int i=0;i<dir.size();++i)
{
int newrow = r+dir[i][0];
int newcolumn = c+dir[i][1];
if(newrow>=0&&newrow<row
&&newcolumn>=0&&newcolumn<column
&&matrix[newrow][newcolumn]>matrix[r][c])
{
memo[r][c] =max(DFS(matrix,memo,newrow,newcolumn)+1,memo[r][c]);
}
}
return memo[r][c];
}
public:
int longestIncreasingPath(vector<vector<int>>& matrix) {
row = matrix.size();
column = matrix[0].size();
if(row==0&&column==0)return 0;
if(row==1&&column==1)return 1;
vector<vector<int>> memo(row,vector<int>(column,0));
int ans =INT_MIN;
for(int i =0;i<row;++i)
{
for(int j=0;j<column;++j)
{
ans = max(DFS(matrix,memo,i,j),ans);
}
}
return ans;
}
};复杂度:

解法二:动态规划
1. 定义子问题
首先,我们定义:
dp[i][j]:矩阵中以点p(i,j)为终点的上升递增路径。
2. 写出子问题的递推关系(关键)
dp[i][j] = max(dp[i'][j']+1) (i',j')为点p邻接节点且其值低于点p(matrix[i][j]>matrix[i'][j'])
3. 确定 DP 数组的计算顺序(关键)
通过使用dp数组存储中间值,但此时我们很难自下而上地计算中间值,因为无法找到初始的边界条件。
因此,我们可以根据矩阵中每个点的值排序得到一个递增的点数组 vector<point> vp,此时,数组第一个元素必定为初始边界,因为其邻接节点的值都大于该点。
以该排序点数组,我们可以自下而上地计算中间值,遍历整个矩阵得到最长边界。
4. 空间优化(可选)
无
class Solution {
public:
private:
class point
{
public:
int row;
int column;
int value;
point(int r,int c,int v):row(r),column(c),value(v){};
};
vector<vector<int>> dir = {{1,0},{-1,0},{0,1},{0,-1}};
public:
int longestIncreasingPath(vector<vector<int>>& matrix) {
const int row = matrix.size();
const int column = matrix[0].size();
if(row==0&&column==0)return 0;
if(row==1&&column==1)return 1;
vector<vector<int>> dp(row,vector<int>(column,1));
vector<point> vp;
vp.reserve(row*column);
for(int i=0;i<row;++i)
{
for(int j=0;j<column;++j)
{
vp.push_back(point(i,j,matrix[i][j]));
}
}
//排序获得边界条件
sort(vp.begin(),vp.end(),[](const point& left,const point& right){
return left.value<right.value;
});
int ret =1;
for(const point& p:vp)
{
for(int i=0;i<4;++i)
{
int newrow = p.row+dir[i][0];
int newcolumn = p.column+dir[i][1];
if(newrow>=0&&newrow<row
&&newcolumn>=0&&newcolumn<column
&&matrix[newrow][newcolumn]<p.value)
{
dp[p.row][p.column] = max(dp[p.row][p.column],dp[newrow][newcolumn]+1);
}
}
ret = max(ret,dp[p.row][p.column]);
}
return ret;
}
};复杂度:
时间复杂度 O(mn+log(mn)) 第一步的时间复杂度是 O(log(mn)),第二步的时间复杂度是 O(mn)
空间复杂度 O(m*n) 使用了二维数组dp[m][n] 和一维数组 vp[m*n]存储中间值
解法三:拓扑排序+BFS广度优先搜索
拓扑排序实质上是对有向图的顶点排成一个线性序列。
对于拓扑排序,如何用代码实现呢?
首先要考虑存储。对于此题我们很显然用二维数组存储矩阵。
我们具体的代码思想为:
- 新建point类,包含节点数值和它的指向
- 一个数组包含point(这里默认编号较集中)。初始化,遍历每个节点指向的时候同时被指的节点入度+1!(A—>C)那么C的入度+1;
- 扫描一遍所有point。将所有入度为0的点加入一个
栈(队列)。 - 当栈(队列)不空的时候,抛出其中任意一个point(栈就是尾,队就是头,顺序无所谓,上面分析了只要同时入度为零可以随便选择顺序)。将point输出,并更新point即其
指向的所有元素入度减一。如果某个点的入度被减为0,那么就将它加入栈(队列)。 - 重复上述操作,直到栈为空。
这里主要是利用栈或者队列储存入度只为0的节点,只需要初次扫描表将入度为0的放入栈(队列)中。
- 因为节点之间是有相关性的,一个节点若想入度为零,那么它的父节点(指向节点)肯定在它为0前入度为0,拆除关联箭头。从父节点角度,它的这次拆除联系,可能导致被指向的入读为0,也可能不为0(还有其他节点指向儿子)
对于此处有向图的遍历,因为我们需要求最长上升子序列,所以通过BFS广度优先遍历我们能够一层一层递增得到子序列的最大长度。
class Solution {
private:
class point
{
public:
int row;
int column;
int value;
point(int r,int c,int v):row(r),column(c),value(v){};
};
vector<vector<int>> dir = {{1,0},{-1,0},{0,1},{0,-1}};
public:
int longestIncreasingPath(vector<vector<int>>& matrix) {
const int row = matrix.size();
const int column = matrix[0].size();
if(row==0&&column==0)return 0;
if(row==1&&column==1)return 1;
vector<vector<int>> in_degree(row,vector<int>(column,0));
queue<point> point_queue;
//计算有向图中所有点的入度
for(int i=0;i<row;++i)
{
for(int j=0;j<column;++j)
{
for(int k=0;k<4;++k)
{
int newrow = i+dir[k][0];
int newcolumn = j+dir[k][1];
if(newrow>=0&&newrow<row
&&newcolumn>=0&&newcolumn<column
&&matrix[newrow][newcolumn]>matrix[i][j])
{
in_degree[newrow][newcolumn]++;
}
}
}
}
//所有入度为0 的点入队列
for(int i=0;i<row;++i)
{
for(int j=0;j<column;++j)
{
if(in_degree[i][j]==0)
{
point_queue.push(point(i,j,matrix[i][j]));
}
}
}
int height =0;
while(!point_queue.empty())
{
int len = point_queue.size();
for(int i=0;i<len;++i)
{
point p =point_queue.front();
point_queue.pop();
for(int k=0;k<4;++k)
{
int newrow = p.row+dir[k][0];
int newcolumn = p.column+dir[k][1];
if(newrow>=0&&newrow<row
&&newcolumn>=0&&newcolumn<column
&&matrix[newrow][newcolumn]>p.value)
{
in_degree[newrow][newcolumn]--;
if(in_degree[newrow][newcolumn]==0)
{
point_queue.push(point(newrow,newcolumn,matrix[newrow][newcolumn]));
}
}
}
}
height++;
}
return height;
}
};复杂度
时间复杂度 O(mn) 第一步,第二步的时间复杂度都是 O(mn)
空间复杂度 O(m*n) 使用了二维数组in——degree[m][n] 和一维数组 point_quque[m*n]存储节点入度以及BFS遍历队列
3. 洗牌算法
参见3种洗牌算法

















 596
596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









