






鹏哥曾说:“学过了不等于学会了”
实不相瞒,我是一位比特学员,或许是失了心气,我曾半途而废,如今也是重拾旧课、步履前行。
环境为×64环境,即64位,故部分结果会与32位有所不同,尤其是地址相关部分。
使用visual studio 2022。
sizeof与strlen的对比
两个函数
sizeof
sizeof 是操作符,计算变量所占空间的大小,单位为字节。
-被操作数可以是变量、类型、计算式,但计算式不会被计算,也不会保留计算式的结果。
int a;
int arr[3] = {0,1,2};
printf("%zd、", sizeof(a));
printf("%zd、", sizeof(arr));
printf("%zd、", sizeof(a+1));
printf("%zd\n", sizeof(int));
打印:4、12、4、4

strlen
!使用该函数需要引用头文件<string.h>
函数原型size_t strlen (const char * str);
- 这里的const是防止函数内部对输入的str做出修改。当我们自己写函数时,也可以这样。
strlen的作用就是求字符串长度。
-字符串由字符数组(char数组)、指向字符的指针构成,结束标识为‘\0‘。
-结束标识不会被计入长度。
char arr1[] = "abcde";
printf("%zd \n", strlen(arr1));

数组、指针与sizeof和strlen
一维数组
数组名是数组首元素的的地址。
-特殊:sizeof(数组名)。仅单独放置数组名时,数组名表示整个数组,即计算整个数组的大小,单位为字节。
-特殊:&数组名。取出数组的地址,其值与数组首元素相同,但意义不同,为整个数组起始的地址。
下为例子:
int arr[3] = {0,1,2};
printf("%zd\n", sizeof(arr));
printf("%p\n", arr);
printf("%p\n", &arr);
printf("%p\n", arr+1);
printf("%p\n", &arr + 1);
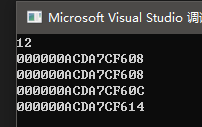
大小为12字节的数组arr,四行打印地址的代码,实际运行中不太可能与我截图一摸一样,但他们之间差值是有迹可循的。
我们取地址的最后两位进行分析:08、08、0C、14。首先要说明地是,这是十六进制,C为12。然后可见arr与&arr的值相同,但进行同样的+1操作后,前者为12、后者为20,也就是说arr往后一步走了4个字节,正好是一个int类型数据的字节数;&arr往后一步走了12个字节,正好是数组arr大小的字节数。这也正是arr与&arr之间区别的体现。
更进一步研究,arr与&arr的类型是什么呢?arr的类型是int *,一个int类型的指针;而&arr的类型是int(*)[3],即指向整个数组的指针,这个数组有三个int类型的数据。
sizeof与一维数组
int arr[3] = {0,1,2};
printf("%zd\n", sizeof(arr));
printf("%zd\n", sizeof(arr+1));
printf("%zd\n", sizeof(*arr));
printf("%zd\n", sizeof(&arr));
printf("%zd\n", sizeof(*&arr));
printf("%zd\n", sizeof(*(arr + 1)));
printf("%zd\n", sizeof(arr[0]));
printf("%zd\n", sizeof(&arr[0]));
printf("%zd\n", sizeof(&arr[0]+1));
按顺序解读:
arr单独放是计算整个数组的大小,3个int类型的数据就是12字节;
arr+1不是单独放arr,那么arr就是数组首元素地址,再+1就是第二个元素的地址,地址大小在32位环境中为4字节、64位中8字节,故计算结果为8字节;
*arr就是数组首元素地址解引用,即*(arr+0),也即arr[0],是一个int类型数据,4字节;
&arr取整个数组的地址,那么还是地址,8字节;
*&arr,取整个数组的地址后解引用,那就是计算整个数组的大小,也可以说 * 与 & 两者相互抵消,12字节;
*(arr+1),即arr[1],数组中第二个元素的大小,4字节;
arr[0],首元素的大小,4字节;
&arr[0],对首元素取地址,8字节;
&arr[0]+1,对首元素取地址后往后一步,这一步多长与&arr[0]相关,&arr[0]是地址,这一步就是8字节,走完这一步依然是地址,8字节。
打印结果
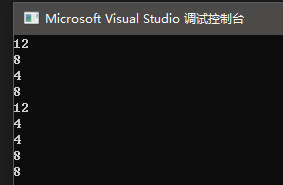
因为是x64环境,所以地址占用大小为8字节,如果是x86环境,则为4字节。
字符数组
sizeof与字符数组
char arr[] = { 'a', 'b', 'c', 'd', 'e', 'f'};
printf("%zd \n", sizeof(arr));
printf("%zd \n", sizeof(arr+0));
printf("%zd \n", sizeof(*arr));
printf("%zd \n", sizeof(arr[1]));
printf("%zd \n", sizeof(&arr));
printf("%zd \n", sizeof(&arr+1));
printf("%zd \n", sizeof(&arr[0]+1));
按顺序解读:
arr单独放表示整个数组,计算整个数组的大小,一共6个char类型数据,共6字节;
arr+0,数组名不是单独放,表示数组首元素地址,8字节;
*arr,对数组首元素地址解引用,那就得到数组首元素,是一个char类型的数据,1字节;
arr[1],数组中第二个数据,1字节;
&arr,取整个数组的地址,类型为arr(*)[6],是地址,8字节;
&arr+1,取整个数组的地址,再往后一步,还是地址,8字节;
&arr[0]+1,取首元素地址,往后一步是第二个元素的地址,还是地址,8字节;
—————————————————
char arr[] = "abcdef";
printf("%zd\n", sizeof(arr));
printf("%zd\n", sizeof(arr + 0));
printf("%zd\n", sizeof(*arr));
printf("%zd\n", sizeof(arr[1]));
printf("%zd\n", sizeof(&arr));
printf("%zd\n", sizeof(&arr + 1));
printf("%zd\n", sizeof(&arr[0] + 1));
按顺序分析:
arr,单独放,表示整个数组,因为录入的是字符串,自带一个‘\0’,7字节;
arr+0,数组首元素地址,8字节;
*arr,对数组首元素地址解引用,就是‘a’,1字节;
arr[1],第二个元素,即’b’,1字节;
&arr,取整个数组的地址,类型为char(*)[7],8字节;
&arr+1,取整个数组的地址,再往后一步,还是地址,8字节;
&arr[0]+1,取首元素地址,再往后一步,还是地址,8字节。
———————————————
const char* p = "abcdef";
printf("%zd\n", sizeof(p));
printf("%zd\n", sizeof(p + 1));
printf("%zd\n", sizeof(*p));
printf("%zd\n", sizeof(p[0]));
printf("%zd\n", sizeof(&p));
printf("%zd\n", sizeof(&p + 1));
printf("%zd\n", sizeof(&p[0] + 1));
按顺序分析:
p为指针,指向该字符串的起始位置,值为地址,8字节;
p+1,p往后一步,跳过一个const char类型数据的字节,即1字节,那就是‘b’的地址,8字节;
*p,p的类型为const char*,那解引用就是char类型,1字节;
p[0],理解为*(p+0),也是char类型,1字节;
&p,取p的地址,还是地址,8字节;
&p+1,取p的地址,往后一步,这一步的长度与p的类型占据的字节数有关,为8字节,这一步后依然为地址,8字节;
&p[0]+1,即&*抵消后为p+1,8字节。
strlen与字符数组
要记得写#include<stdio.h>
char arr[] = { 'a','b','c','d','e','f' };
printf("%zd\n", strlen(arr));
printf("%zd\n", strlen(arr + 0));
printf("%zd\n", strlen(*arr));
printf("%zd\n", strlen(arr[1]));
printf("%zd\n", strlen(&arr));
printf("%zd\n", strlen(&arr + 1));
printf("%zd\n", strlen(&arr[0] + 1));
按顺序分析:
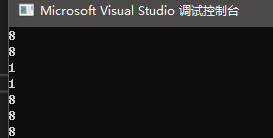
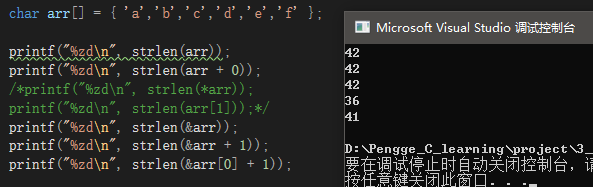
arr,指向字符数组的起始位置,即首元素的地址,由于该字符数组没有明确的‘\0’结束标识,所以结果未知;
arr+0,同上,结果未知;
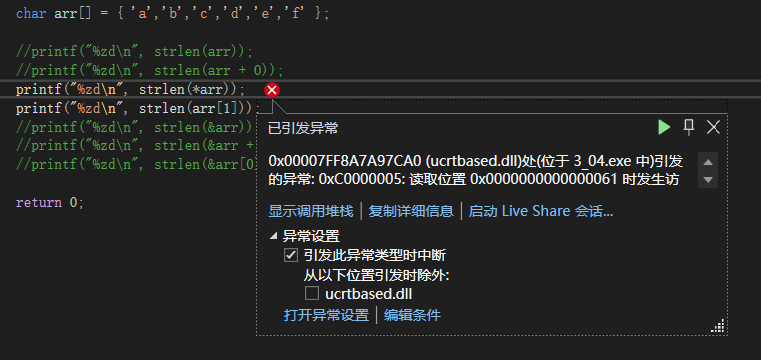
*arr,对首元素地址解引用,得‘a’,其ASCII码为97,将97传入strlen,因为地址97不允许访问,如0地址等特殊地址都是不允许访问的,所以strlen得到的是野指针,会报错;
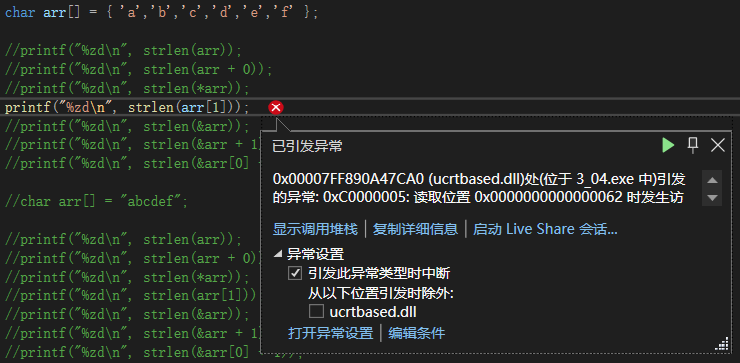
arr[1],传98,同上,报错;
&arr,取整个数组的地址,其类型为char(*)[6],值为首元素地址,由strlen函数原型接收的参数类型const char* str可知,这里strlen函数只会接受值,而不会管这个值原本的类型,所以结果同arr,即结果未知;
&arr+1,取整个数组的地址,往后走一步,也就是跳过6个字节,虽然结果未知,但是可以知道比strlen(&arr)少6;
&arr[0]+1,取第一个元素的地址,往后一步,就是第二个元素的地址,结果比strlen(&arr)少1。
预期报错结果:
其余可执行结果:
—————————————————————————————————————
char arr[] = "abcdef";
printf("%zd\n", strlen(arr));
printf("%zd\n", strlen(arr + 0));
printf("%zd\n", strlen(*arr));
printf("%zd\n", strlen(arr[1]));
printf("%zd\n", strlen(&arr));
printf("%zd\n", strlen(&arr + 1));
printf("%zd\n", strlen(&arr[0] + 1));
按顺序分析:
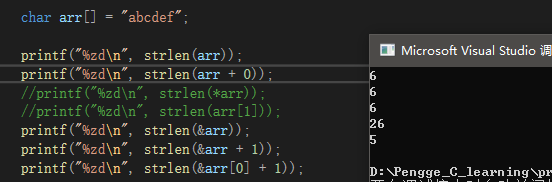
arr,字符串起始位置的指针,strlen不计算’\0’,那么结果为6;
arr+0,同上,结果为6;
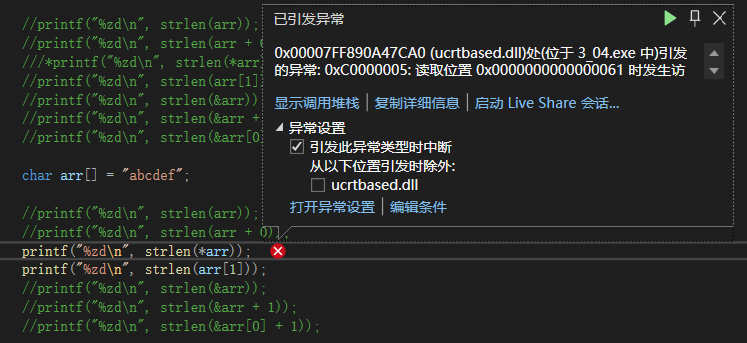
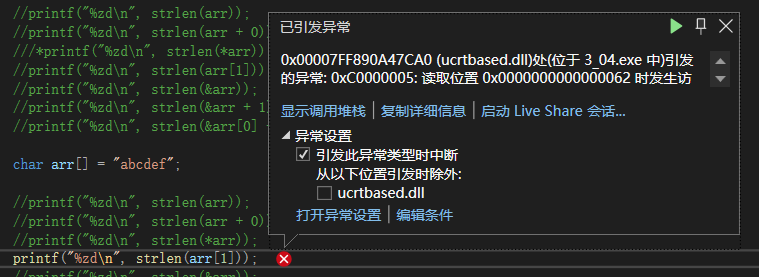
*arr,传’a‘,报错;
arr[1],传‘b’,报错;
&arr,取整个字符串的指针,也就是起始位置指针,结果为6;
&arr+1,取指针后往后一步,&arr类型为char(*)[7],向后走7个字节,往后的’\0‘位置位置,故结果未知;
&arr[0]+1,取首元素地址后往后一步,即到第二个元素的地址,结果为5、
预期报错结果:
其余可执行结果:
———————————————————————————————————
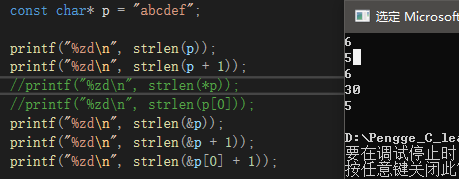
const char* p = "abcdef";
printf("%zd\n", strlen(p));
printf("%zd\n", strlen(p + 1));
printf("%zd\n", strlen(*p));
printf("%zd\n", strlen(p[0]));
printf("%zd\n", strlen(&p));
printf("%zd\n", strlen(&p + 1));
printf("%zd\n", strlen(&p[0] + 1));
按顺序分析:
p,指向字符串的起始位置,结果为6;
p+1,p的类型是char*,所以只跳过1个字节,结果为5;
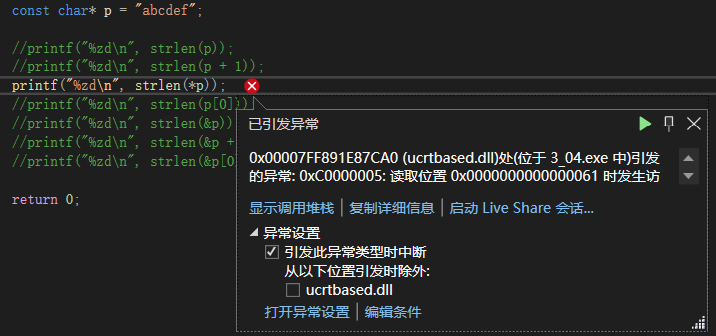
*p,p为字符串起始地址,对p解引用得到’a’,报错;
p[0],等同*(p+0),同上,报错;
&p,取p的地址,p后’\0‘位置未知,故结果未知;
&p+1,p的类型是char*,x64环境中占用8个字节,往后一步,就是跳过8个字节,如果这8个字节都没有’\0’,那么结果比strlen(&p)小8,否则结果未知;
&p[0]+1,首元素地址往后一步,就是第二个元素的地址,结果为5。
预期报错结果:
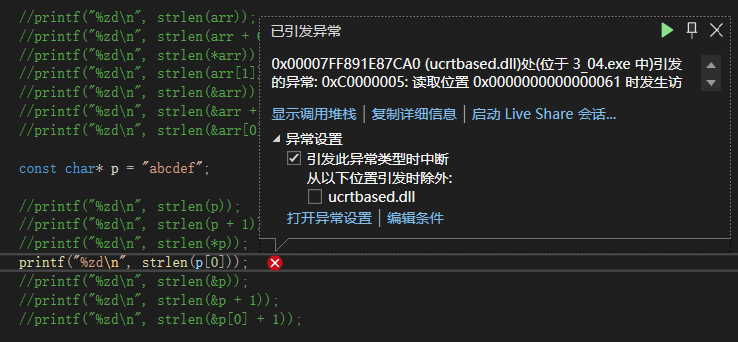
其余可执行结果:
二维数组
假设现在有一个长9宽1的矩形,我能否将它切割、拼接为正方形呢?

答案是可以的,我能得到一个边长为3的正方形,即便我不能实际的去切割,也不能妨碍我用想象力看待长方形为正方形:

二维数组也是类似的道理,二维数组的元素在内存中的位置是连续的,某种角度上来看,只是一个一维数组通过下标分出了多个一维数组,其它多维数组也是类似的:int arr[行][列];
-对于已创建的二维数组,arr[行] 即为各对应行的数组名,同样表示对应数组首元素地址,同样单独放在sizeof里表示整个数组。
-那么arr单独是表示什么呢?arr表示二维数组的首元素地址arr[0],二维数组的元素是什么?是一行、二行、三行,arr表示的是第一行的地址,其类型为int[列],也可以说是数组指针int(*)[列],这里不多解释数组指针,我们这里的讨论强调arr[0]是一个“包含列数个元素的数组”,即其作为数组的类型,下文描述其类型取int[列]。多维数组以此类推。
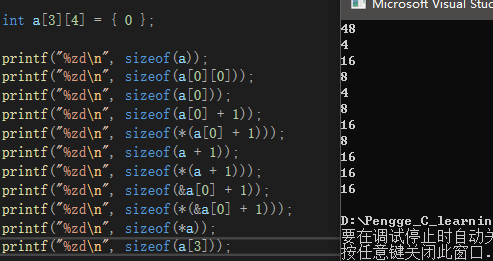
int a[3][4] = { 0 };
printf("%zd\n", sizeof(a));
printf("%zd\n", sizeof(a[0][0]));
printf("%zd\n", sizeof(a[0]));
printf("%zd\n", sizeof(a[0] + 1));
printf("%zd\n", sizeof(*(a[0] + 1)));
printf("%zd\n", sizeof(a + 1));
printf("%zd\n", sizeof(*(a + 1)));
printf("%zd\n", sizeof(&a[0] + 1));
printf("%zd\n", sizeof(*(&a[0] + 1)));
printf("%zd\n", sizeof(*a));
printf("%zd\n", sizeof(a[3]));
按顺序解析:
a,单独放为整个数组,3行4列的int类型二维数组,3×4×4=48字节;
a[0][0],第一行第一个元素,4字节;
a[0],是第一行的数组名,单独放表示整个第一行,16字节;
a[0]+1,第一行的首元素地址,其类型为int*,往后一步就是到第一行第二个元素的地址,8字节;
*(a[0]+1),对第一行第二个元素地址解引用,得到第一行第二个元素,其为int类型,4字节;
a+1,a表示二维数组的首元素地址,也就是第一行的地址,其类型为int[4],往后一步跳过4个int类型的数据,也就到了第二行的地址,就是8字节;
*(a + 1),就是整个第二行,4个int类型的数据,那就是16字节;
&a[0] + 1,取出第一行的地址,那这就是int[4]类型的,往后一步就是跳过4个int类型的数据,也就是第二行的地址,8字节;
*(&a[0] + 1),解引用后为整个第二行,16字节;
*a,a表示二维数组的首元素地址,也就是第一行的地址,解引用后为整个第一行,16字节;
a[3],是二维数组的第四行,单独放在sizeof里就是整个第四行,但是a这个二维数组没有第四行,按理来说会越界访问,但是因为sizeof并不会真的去访问,也没必要去访问这个不存在的第四组的元素,sizeof只是根据填入的内容得出这东西占用的字节数,所以sizeof会判断出这个a[3]的类型是int[4],结果为16字节,鹏哥说得好:“总不能说我站在银行面前就是想抢劫吧?我只是想想里面有多少钱。”。
预期结果:
习题
1、求输出结果
int a[5] = { 1, 2, 3, 4, 5 };
int *ptr = (int *)(&a + 1);
printf( "%d,%d", *(a + 1), *(ptr - 1));
&a+1,就是取整个数组的地址,再往后一步跳过int[5]的字节,即跳过5×4=20个字节;
*(a+1),就是数组的第二个元素,也就是2;
*(ptr-1),ptr的类型是int*,往前一步就是往前4个字节,也就是从数组起始处往后16个字节,走到了第五个数据处,也就是5。
打印结果就是2,5。

———————————————————————————————
2、在X86环境下假设结构体的⼤⼩是20个字节,程序输出的结果是啥?
struct Test
{
int Num;
char* pcName;
short sDate;
char cha[2];
short sBa[4];
}*p = (struct Test*)0x100000;
int main()
{
printf("%p\n", p + 0x1);
printf("%p\n", (unsigned long)p + 0x1);
printf("%p\n", (unsigned int*)p + 0x1);
return 0;
}
“0x”表示16进制,前面的结构体在声明的同时创建了一个相应的结构体指针变量p,其值为0x100000;
x86环境下,int、char*、shor、char[2]、short[4]分别占4、4、2、1×2、2×4字节,共20字节;
p+0x1,相当于p+1,就是往后一步,一步20字节,0x100014;
(unsigned long)p+0x1,强制类型转换为unsigned long后,p不再是指针,而是无符号的整型,也就是说只是单纯的加1,0x100001;
(unsigned int*)p+0x1,强制类型转换为unsigned int*后,p往后一步就是unsigned int的长度,也即是4字节,0x100004。
实际打印中,x会被0替换:

—————————————————————————————————
3、求输出结果
int a[3][2] = { (0, 1), (2, 3), (4, 5) };
int* p;
p = a[0];
printf("%d", p[0]);
注意到创建二维数组a时,使用了三个逗号表达式,逗号表达式计算后只取最后一个值,故二维数组的内容为:1、3、5、0、0、0。调试==>监视窗口中可见:
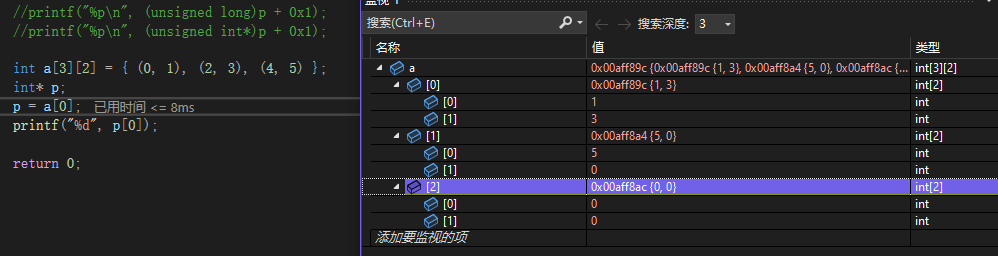
p是指向a数组第一行地址的int*指针,故p[0]即*p只会取出一个int数据,即第一行第一个元素,1。
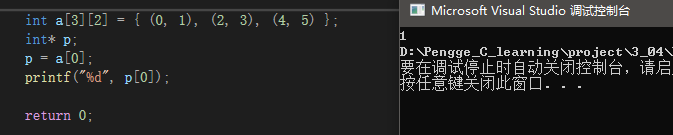
——————————————————————————————————————————
4、假设环境是x86环境,程序输出的结果是啥?
int a[5][5];
int(*p)[4];
p = a;
printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
p=a,p与a数组的起始位置相同;
&p[4][2],&*(*(p+4))+2),p的类型是int*[4],那么p+4就是往后4×4×4=64个字节,*(p+4)就是得到int[4],然后再往后两步,就是往后4×2=8字节,再解引用得到int类型的数据,此时再取其地址,那么这个地址相比p的起始位置已经往后移动了64+8=72个字节;
&a[4][2],a数组第五行第三个元素,取其地址,其地址相对于a数组的起始位置,往后移动了4×5×4+2×4=88字节;
故&p[4][2] - &a[4][2] = -16,但是这个是字节差,在C语言中,指针加减得出的是索引差,也就是以指针指向的元素类型作为单位计算的差值,这里两个指针最后都是int*类型,所以以int来计算,也即是-16 ÷ 4 = -4,则表达式的最终结果为-4,这个结果的类型是ptrdiff_t,一种有符号整数类型,足够存储两指针之间的差值。
%p输出:-4,x86环境下以十六进制输出为FFFFFFFC;
%d输出:-4。
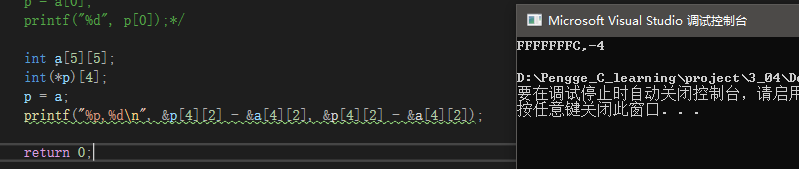
——————————————————————————————————————————————————
4、求输出
int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int* ptr1 = (int*)(&aa + 1);
int* ptr2 = (int*)(*(aa + 1));
printf("%d,%d", *(ptr1 - 1), *(ptr2 - 1));
&aa取出整个数组的地址,再+1就是跳过整个aa数组,到达不存在的aa数组第三行第一个元素,强制转化为int*,往后的移动就是以一个int类型元素的字节数为单位了;
*(aa+1),aa就是aa数组首元素的地址,也就是第一行的地址,再+1就是第二行的地址,强制转化为int*,此时对应的就是第二行第一个元素的地址。
第一个%d:ptr1-1就是第二行第五个元素,也就是10;
第二个%d:ptr2-1就是第一行第五个元素,也就是5。

——————————————————————————————————————
char* a[] = { "work","at","alibaba" };
char** pa = a;
pa++;
printf("%s\n", *pa);
a数组是一个指针数组,是元素为char类型的指针的数组,其内容为三个字符串对应的三个指针;
pa=a,将a数组首元素的地址赋予pa,a数组首元素是指针,指针的地址赋予pa,那pa就是指针的指针;
pa++,就是pa往前一步,走过一个char类型的字节,也就指向了第二个元素,即aa数组第二个字符串对应的指针。
输出结果为at。

——————————————————————————————————
char* c[] = { "ENTER","NEW","POINT","FIRST" };
char** cp[] = { c + 3,c + 2,c + 1,c };
char*** cpp = cp;
printf("%s\n", **++cpp);
printf("%s\n", *-- * ++cpp + 3);
printf("%s\n", *cpp[-2] + 3);
printf("%s\n", cpp[-1][-1] + 1);
c数组是指针数组,存放了四个指向同字符串的指针;
cp是二重指针数组,c+3 指向c数组的第四个元素,c+2 指向c数组第三个元素,后面以此类推;
cpp是三重指针,cp数组首元素,也就是c+3;
简单理解就是cpp解引用得到cp,也就是cp数组首元素c+3,c+3解引用得到c数组第四个元素,c是字符串"FIRST"的地址;
++cpp,也就是cpp先+1再使用,cpp往前一步就是指向c+2,解引用就是c+2,c+2再解引用就是指向字符串"POINT",以%s打印出来,结果就是 POINT;
C语言中,自增、自减、取地址、解引用为优先级别2且从右往左计算,加减运算符为优先级别3且从左往右计算,所以cpp前面已经自增1,这里再自增1后解引用为c+1,再自减1为c,再解引用就是"ENTER",再+3就跳过了’E’、‘N’、‘T’,到’E’,以%s输出就是 ER;
*cpp[-2],可以理解为*(*(cpp-2)),那就是cpp往前走两步,因为之前已经自增过两次了,所以cpp-2后又指向了cp数组首元素,解引用就是c+3,解引用就是“FIRST”的地址,再+3就是 ST;
cpp[-1][-1] + 1,*(*(cpp-1)-1),cpp的自增2还在,cpp-1就是指向c+2,解引用后c+2-1就是c+1,再解引用就是"NEW",再+1以%s输出就是 EW。
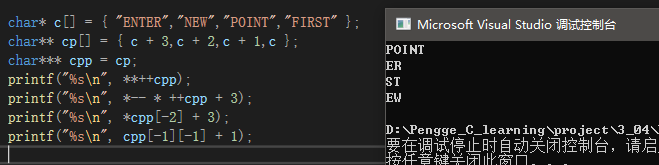
此外,在这段代码中的自减操作,其实把c+1变成了c,逐语句调试,运行过第二个printf后,通过调试-监视窗口可知:

这几道题都不算难,重要的是不缺乏对应的知识内容。
如有错漏还请指正。

















 1064
1064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









