




 本文探讨了使用大数据组件处理航空数据,特别是csv文件的存储和使用。通过对不同组件的优缺点分析,提出了多个组件搭配方案,包括分布式文件系统、Spark、Hadoop、Hive和HBase等。在面对数据存储、读取和分析需求时,建议使用关系数据库、HDFS、HBase、Solr/Elasticsearch和Spark Core等组件的组合。
本文探讨了使用大数据组件处理航空数据,特别是csv文件的存储和使用。通过对不同组件的优缺点分析,提出了多个组件搭配方案,包括分布式文件系统、Spark、Hadoop、Hive和HBase等。在面对数据存储、读取和分析需求时,建议使用关系数据库、HDFS、HBase、Solr/Elasticsearch和Spark Core等组件的组合。
大数据技术对处理大批量数据和在分布式计算上,较传统技术优势明显。那么,借大数据技术在处理航空数据上是否有用武之地?本文接下来讨论使用大数据组件来处理航空数据。
航空数据有的数据以csv文件格式存储,统计分析航空数据有很多潜在价值,尽管有可观的分析价值,但这里仍跟大数据技术扯不上关系。所以,笔者准备从案例的角度,来尝试讨论下自己的观点。
案例一
假设一个航空公司的某业务一天生成100个csv,一个月生成3000个csv,在使用csv文件数据时,遇到一个问题:
这些csv怎么存?怎么用?
(1)问题分析
这个问题比较宽泛,我们可以拆解为,怎么存,可以解析为怎么存?和好不好存?怎么用,可以解析为能不能用?和好不好用。其实还可以继续拆解:
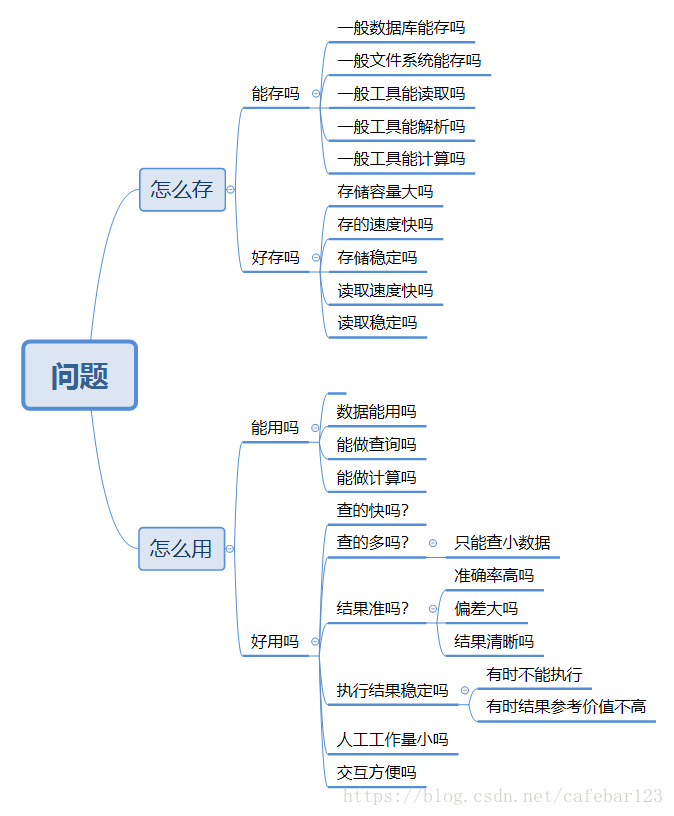
从图中看,如果“一般文件系统”不能胜任,可以使用hadoop hdfs文件系统,或者其它分布式文件系统,这类分布式文件系统首先能解决容量的问题。既是文件系统,文件系统该有的功能也都具备,所以使用hadoop hdfs是个不错的选择。
如果不使用文件系统存储,数据库,no sql数据库也是一个选择。mysql,oracle存csv并不常见,no sql 存csv也不常见,不确定后果,不是一个好的选择。如此一来,可能也会排除hive,hbase等no sql数据库。但另一方面,不常见的原因是,数据库存储的数据单元更小而已,如能把csv拆分,也能存csv。那么,这里的问题是,如此一来,处理csv的方式出现了分水岭:

选择哪一边,是很困难的。基于改动越小越好的原则,选择“文件系统”更好。基于拓展性越多越好的原则,第二种更好。
那么,在使用文件读取工具上,怎么选择大数据组件?如果“一般工具”能胜任,就使用一般工具好了。这里的“一般工具”可以是csv读写工具,也可以是csv计算工具。实际上,不光读写功能,这里显然是做了过度简化。据笔者个人的了解,目前市面上这一类工具很多,也很优秀。如果我们强制区分“一般性工具”和“大数据组件”,大数据组件可选的有:
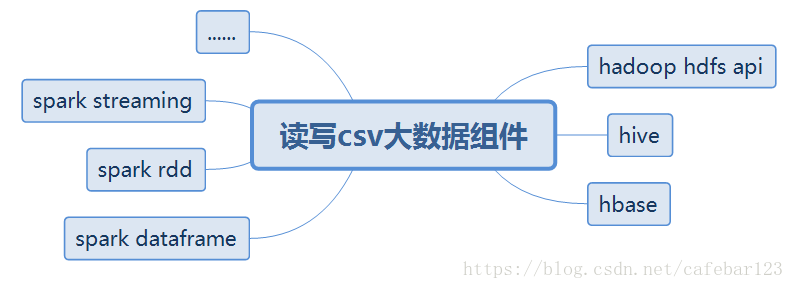
相比较,大数据组件在处理csv上,也不是很差,优点也很多,只是用起来,需要环境等前提。
那么,性能,效率怎么样?它们都是开源产品,在不断完善,在往好的方向上。那么选哪一种大数据组件呢?
首先是比较了。市面上也有比较分析结果。总之,比较结果的共识是:

这里谈点个人理解。需要注意的是,“需求点”的成本和收益。比如“百度搜索”,它其实是查询功能,这个需求点,是查询。这个点价值巨大,所以值得整个公司为它投入巨大,各种高科技都往上堆。
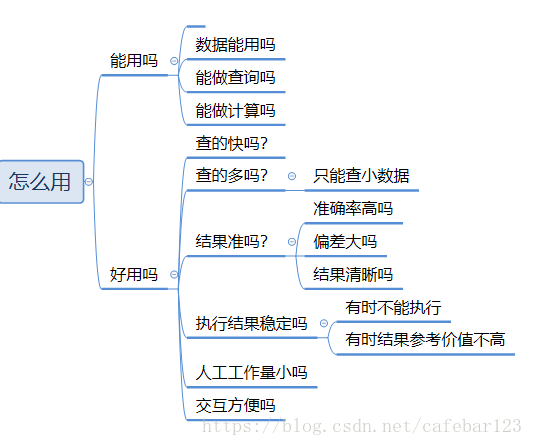
既然前面说到使用“大数据组件”有前提,这就牵扯到好不好用上面了。实际上,这个问题是这样的:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 803
803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









