




 本文详细介绍了Odoo中模型的构建,包括Controller部分的路由映射、请求处理、响应生成,数据加载的XML定义和模型的创建,以及安全性设置和静态文件的组织结构。同时讲解了视图展示的四种类型,如菜单、表单、列表和搜索视图。
本文详细介绍了Odoo中模型的构建,包括Controller部分的路由映射、请求处理、响应生成,数据加载的XML定义和模型的创建,以及安全性设置和静态文件的组织结构。同时讲解了视图展示的四种类型,如菜单、表单、列表和搜索视图。
odoo 模型:
一:Controller
一般通过继承的形式来创建controller类,继承自odoo.http.Controller。
以route装饰器来装饰定义的方法,提供url路由访问路径:
class MyController(odoo.http.Controller)://继承controller定义控制器
@route('/some_url', auth='public')//装饰器路由访问方法,并指明访问方式:公开还是需要用户登陆
def handler(self):
return stuff()
路由映射相关
odoo.http.route(route=None, **kw) 装饰器可以将对应方法装饰为处理对应的http请求。
装饰器参数有:
1)route
字符串或数组,决定哪些http请求可以匹配所装饰的方法,可以是单个字符串、或多个字符串的数组。
2)type
请求的类型,可以是http或json。
3)auth
认证方法的类型,可以是以下几种:
user - 必须是已通过登录认证的用户,才能访问该请求。如果未经过登录直接访问,则会拦截并跳转回odoo登录页面。
public - 使用公用的认证,可以不经过登录验证直接访问。
none - 相应的方法总是可用,一般用于框架和认证模块,对应请求没有办法访问数据库或指向数据库的设置。
4)methods
这个请求所应用的一系列http方法【PATCH, POST, PUT, 或者DELETE】,如果没指定则是所有方法。
methods=['POST', 'GET']
5)cors
跨域资源cors参数。
6)csrf(boolean)
是否开启CSRF跨域保护,默认True。
a)如果表单是用python代码生成的,可通过request.csrf_token() 获取csrf
b)如果表单是用javascript生成的,CSRF token会自动被添加到QWEB环境变量中,通过require('web.core').csrf_token获取
c)如果终端可从其他地方以api或webhook形式调用,需要将对应的csrf禁用,此时最好用其他方式进行验证
请求相关
请求对象在收到请求时自动设置到odoo.http.request,可以通过该对象提前request中携带的 参数、cookie、session对象等。
跟请求相关的类和函数有以下几种:
1:class odoo.http.WebRequest(httprequest)
所有odoo WEB请求的父类,一般用于进行请求对象的初始化,其构建函数的参数有:
1)httprequest
原始的werkzeug.wrappers.Request对象
2)params
请求参数的映射
3)cr
当前方法调用的初始游标,当使用none的认证方式时读取游标会报错
4)context
当前请求的上下文键值映射
5)env
绑定到当前请求的环境
6)session
储存当前请求session数据的OpenERPSession
7)debug
指定当前请求是否是debug模式
8)db
当前请求所关联的数据库,当使用none认证时为None
9)csrf_token(time_limit=3600)
为该请求生成并返回一个token(参数以秒计算,默认1小时,如果传None表示与当前用户session时间相同)
2:class odoo.http.HttpRequest(*args)
用于处理http类型请求的函数,匹配 路由参数、查询参数、表格参数,如果有指定文件也会传给该方法。为防止重名,路由参数优先级最高。
该函数的返回值有三种:
-
- 无效值,HTTP响应会返回一个204(没有内容)
- 一个werkzeug 响应对象
- 一个字符串或unicode,会被响应对象包装并使用HTML解析
3:make_response(data, headers=None, cookies=None)
用于生成没有HTML的响应 或 自定义响应头、cookie的html响应。
由于处理函数只以字符串形式返回html标记内容,需要组成一个完整的响应对象,这样客户端才能解析
参数有:
1)data (basestring)
响应主体。
2)headers ([(name, value)])
http响应头。
3)cookies (collections.Mapping)
发送给客户端的cookie。
4:not_found(description=None)
给出404 NOT FOUND响应。
5:render(template, qcontext=None, lazy=True, **kw)
渲染qweb模板,在调度完成后会对给定的模板进行渲染并返回给客户端。
参数有:
1)template (basestring)
用于渲染的模板完整ID:模块.模版
2)qcontext (dict)
用于渲染的上下文环境。
3)lazy (bool)
渲染动作是否应该拖延到最后执行。
4)kw
转发到werkzeug响应对象。
6:class odoo.http.JsonRequest(*args)
处理通过http发来的json rpc请求。
参数:params -- 是一个json格式对象
返回值:一个json-rpc格式的,以JSON-RPC Response对象的组装。
响应相关
1:class odoo.http.Response(args, *kw)
响应对象通过控制器的路由传递,在werkzeug.wrappers.Response之外,该类的构造方法会添加以下参数到qweb的渲染中:
1)template (basestring)
用于渲染的模板。
2)qcontext (dict)
用在渲染中的上下文环境。
3)uid (int)
用于调用ir.ui.view渲染的用户id,None时使用当前请求的id。
上面的参数在实际渲染之前可以随时作为Response对象的属性进行修改。
response对象可以调用以下方法:
-
- render() - 渲染响应对象的模板,并返回内容。
- flatten() - 强制渲染响应对象的模板,将结果设置为响应主体,并将模板复原。
二、data (odoo 基础数据加载)
XML数据定义格式
<record id="building_type0" model="building.document.folder">
<field name="name">局集团党委文件</field>
</record>
<record id="activity_type1" model="building.document.folder">
<field name="name">总支部文件</field>
</record>
<record id="building_type2" model="building.document.folder">
<field name="name">支部文件</field>
</record>
-
model里填 modelclass 的 _name 值
-
id里填外部标识(external-identifier),是odoo中用来标注某条数据库记录的唯一标示符
-
注意:可以在web设置里查看所有的外部标识。
内部field就是定义具体记录的列名和值,可以有多个列,如下:
<record id="documents_hr_documents_facet" model="documents.facet">
<field name="name">Documents</field>
<field name="sequence">6</field>
<field name="folder_id" ref="documents_hr_folder"/>
</record>
<record id="documents_internal_template_facet" model="documents.facet">
<field name="name">Templates</field>
<field name="sequence">6</field>
<field name="folder_id" ref="documents_internal_folder"/>
</record>
数据文件需在__manifest__.py data或demo字段里列出,才能在模块安装更新后正确的加载
'data': [
'security/security.xml',
'security/ir.model.access.csv',
'assets.xml',
'views/views.xml',
'views/templates.xml',
'data/building_data.xml',
],
#
'demo': [
'demo/demo.xml',
],
- demo数据只在勾选演示数据后才会加载(only loaded in demonstration mode)
- data数据在系统启动后会自动进行加载(always loaded)
三、models
models里面是模型,ORM对象关系映射,面向对象访问数据库,不写sql。
model属性详解:
_name:模型唯一标识,类非继承父类时必须指定。_rec_name:数据显示名称,如设置则返回其指定的字段值,不设置默认显示字段为name的字段值,如无name字段则显示"模块名,id";详见BaseModel.name_get方法。_log_access:是否自动增加日志字段(create_uid,create_date,write_uid,write_date)。默认为True。_auto:是否创建数据库对象。默认为True,详见BaseModel._auto_init方法。_table:数据库对象名称。缺省时数据库对象名称与_name指定值相同(.替换为下划线)。_sequence:数据库id字段的序列。默认自动创建序列。_order:数据显示排序。所指定值为模型字段,按指定字段和方式排序结果集。例:_order = "create_date desc":根据创建时间降序排列。可指定多个字段。
不指定desc默认升序排列;不指定_order默认id升序排列。
_constraints:自定义约束条件。模型创建/编辑数据时触发,约束未通过弹出错误提示,拒绝创建/编辑。格式:
_constraints = [(method, 'error message', [field1, ...]), ...]method:检查方法。返回True|Falseerror message:不符合检查条件时(method返回False)弹出的错误信息[field1, ...]:字段名列表,这些字段的值会出现在error message中。
_sql_constraints:数据库约束。例:
_sql_constraints = [ ('number_uniq', 'unique(number, code)', 'error message') ]
会在数据库添加约束:CONSTRAINT number_uniq UNIQUE(number, code)
_inherit:单一继承。值为所继承父类_name标识。如子类不定义_name属性,则在父类中增加该子类下的字段或方法,不创建新对象;如子类定义_name属性,则创建新对象,新对象拥有父类所有的字段或方法,父类不受影响。格式:
_inherit = '父类 _name'
_inherits:多重继承。子类通过关联字段与父类关联,子类不拥有父类的字段或方法,但是可以直接操作父类的字段或方法。格式:
_inherits = {'父类 _name': '关联字段'}注意:
在models类中若使用_inherit继承表结构时,继承类中_name写与不写的作用不同:
在继承类中写_name时:继承表结构,不继承表数据,不在原表中修改
在继承类中不写_name时:继承表结构,继承表数据,在原表中修改
说明:
- 一个类就是一张表
- 继承,models.Model
类变量:
表名“classroom_teacher”,规则,前面是这个模块名,后面是自定义 _name = "classroom.teacher"
常用字段,需要引入 from odoo import fields
定义对象类型
基础类型:char, text, boolean, integer, float, date, time, datetime, binary;
复杂类型:selection
关系类型:Many2many,Many2one,One2many。
基础型
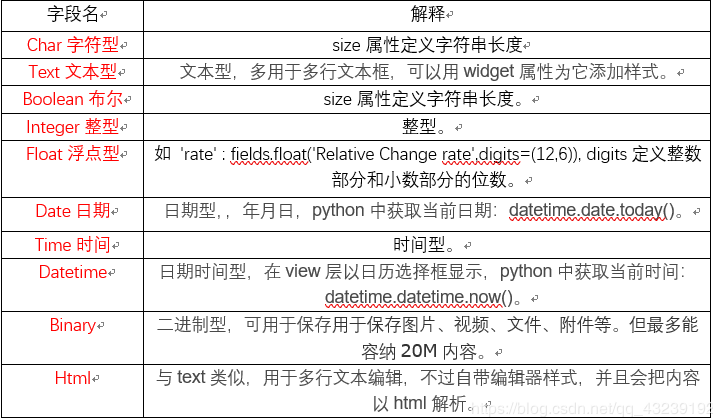
复杂型
selelction下拉框:
hobby = fields.selection([('0','火影'),('1','海贼'),('2','钢炼')],default=‘0’,string='爱好')
关系型
many2many 多对多

One2many 一对多

Many2one 多对一

name = fields.Char() required=True 必填 string 界面label的值 字段标签 help 界面tooltip index 是否创建数据库索引 简单字段类型Boolean, Integer,Float,Monetary, Char,Text,Html,Date,Datetime,Binary,Selection,Reference 不可再分 保存单一数据 保留字段 id, create_date, create_uid, write_date, write_uid 会随模型一起在表中建立(请勿重复定义)
四、security (权限安全)
security/模型名_security.xml
security/ir.model.access.csv
(1)建立安全组(security/activity_security.xml)
| 字段类型 | 说明 |
|---|---|
| name | 用户组组名 |
| category_id | 关联应用,这是一个关联字段,因此使用了 ref 属性来通过 XML ID 连接已创建的分类 |
| implied_ids | 这是一个one-to-many关联字段,包含一系列组来对组内用户生效 |
| model_id | 模块id,对应ir.model.access.csv文件中定义的model_id |
| domain_forc | 域表达式。[(字段名,操作符,值), (字段名,操作符,值)] |
| groups | 用户组id。base.group_user,是系统内置的员工组的外部id |
<?xml version="1.0" encoding="utf-8"?>
<odoo>
<data noupdate="0">
<record model="ir.module.category" id="module_category_activity">
<field name="name"> 活动管理 </field>
</record>
#普通用户
<record model="res.groups" id="group_activity_user">
<field name="name"> 用户 </field>
<field name="category_id" ref="module_category_activity"/>
</record>
#管理员
<record model="res.groups" id="group_activity_manager">
<field name="name"> 管理 </field>
<field name="implied_ids" eval="[(4, ref('group_activity_user'))]"/>
<field name="category_id" ref="module_category_activity"/>
</record>
</data>
</odoo>
(2)定义组的权限(security/ir.model.access.csv)
| 字段类型 | 说明 |
|---|---|
| id | 权限的ID,自定义,不能重复 |
| name | 权限名称,自定义 |
| model_id:id | model_模型名称。(注意把“.”全部换成“_”,否则会报错) |
| perm_read,perm_write,perm_create,perm_unlink | 读、写、增加、删除权限,1是有权限,0是无权限,具体根据需要来设置权限 |
id,name,model_id:id,group_id:id,perm_read,perm_write,perm_create,perm_unlink
access_activity_user,access_activity_user,model_activity_event,group_activity_user,1,0,0,0
access_activity_manager,access_activity_manager,model_activity_event,group_activity_manager,1,1,1,1
五、static (静态文件)
文件层级:
static/src/js/XXXXX.js 编写js文件
static/src/img/XXXXX.png 放置图片
static/src/description/XXXXX.png 一般用来放置模型封面图片
static/src/scss/XXXX.scss 编写scss文件
static/src/xml/XXXX.xml 编写模板文件
例:
六、views (视图【页面】展示)
主要有四个视图:
菜单视图:把 数据模型——菜单——视图(tree、form) 连接起来
<act_window id="动作id"
name="XX"
res_model="模型名称(表名)"
view_mode="tree,form"/>
<menuitem id="菜单id" name="XX" action="菜单绑定动作id" parent="父级菜单"/>
表单视图:创建、编辑数据模型所用视图。
<record id="视图id" model="ir.ui.view">
<field name="name">详情</field>
<field name="model">模型名称(表名)</field>
<field name="arch" type="xml">
<form>
<header>
<button type="object" name="issue" string="确认"/>
</header>
<sheet>
<group>
<group>
<field name="materialName"/>
<field name="rackNumber"/>
<field name="responsibilityWorkshop"/>
<field name="timeAllocation"/>
<field name="allocationTime"/>
</group>
<group>
<field name="unit"/>
</group>
<group>
<field name="completionDate"/>
<field name="materialCode"/>
<field name="amount"/>
<field name="remarks"/>
</group>
<group>
<field name="process_picture"/>
</group>
</group>
</sheet>
</form>
</field>
</record>
列表视图:展示数据模型(显示数据)时使用。
<record id="视图id" model="ir.ui.view">
<field name="name">列表</field>
<field name="model">模型名称(表名)</field>
<field name="arch" type="xml">
<tree>
<field name="materialName"/>
<field name="format"/>
<field name="materialCode"/>
<field name="completionDate"/>
<field name="unit"/>
<field name="amount"/>
<field name="rackNumber"/>
<field name="responsibilityWorkshop"/>
<field name="remarks" optional="hidden"/>
</tree>
</field>
</record>
搜索视图:制定odoo右上角对于当前数据模型的可搜索字段以及可用过滤器。
<record id="视图id" model="ir.ui.view">
<field name="name">搜索视图</field>
<field name="model">模型名称(表名)</field>
<field name="arch" type="xml">
<search>
<!-- 搜索筛选字段 -->
<filter string="字段展示名称" name="字段" domain="[('筛选条件','=/in/!=', 值)]"/>
<!-- 搜索默认分组字段 -->
<field name="字段"/>
<group expand="0" string="Group By">
<filter string="名称" name="group_by_字段"
context="{'group_by': '字段'}"/>
</group>
</search>
</field>
</record>
_manifest__.py
{
'name': '模型名称',
'summary': """
模型介绍""",
'description': """
模型介绍
""",
'author': "创建者",
'website': "todo",
'category': '模型类别',
'version': '版本',
'depends': [依赖区],
'data': [
权限及视图加载区
],
'qweb': [qweb模板加载区],
'application': True, 是否是应用
'installable': True, 是否可网页安装
}

















 1177
1177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









