



 文章详细介绍了HTTP协议的基础知识,包括HTTP请求的GET和POST方法、报文格式、请求头如Host、Content-Type、User-Agent等,以及HTTP响应的状态码和Content-Type。此外,还提到了抓包工具Fiddler的使用,代理的概念以及正向代理和反向代理的区别。文章强调了HTTP在浏览器与服务器交互中的作用,并探讨了GET和POST方法的典型区别。
文章详细介绍了HTTP协议的基础知识,包括HTTP请求的GET和POST方法、报文格式、请求头如Host、Content-Type、User-Agent等,以及HTTP响应的状态码和Content-Type。此外,还提到了抓包工具Fiddler的使用,代理的概念以及正向代理和反向代理的区别。文章强调了HTTP在浏览器与服务器交互中的作用,并探讨了GET和POST方法的典型区别。

日升时奋斗,日落时自省
目录
HTTP是什么???
HTTP是全程超文本传输协议(HyperText Transfer Protocol),应用层协议
HTTP属于是应用层最广泛使用的协议之一
浏览器获取到网页,就是基于http,HTTP就是浏览器和服务器之间的交互桥梁
此处HTTP以1.1版本为基础
HTTP请求本质上就是给tcp socket里写了个符号http格式(类似于tcp udp报文格式)的字符串从浏览器发送给了服务器
事例: sougou.com 这就是一个网址 俗称:URL
浏览器就会根据这个URL构造出一个HTTP请求,发给服务器 ,服务器就会返回一个HTTP响应(包含了html,css,js,图片等等)
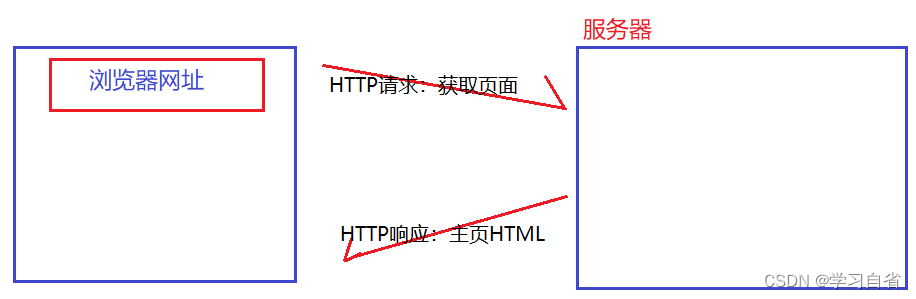
浏览器再把得到的html等数据进行显示出来(渲染)
HTTP协议交互详细过程,可以借助第三方的工具来看到的,称为“抓包”工具(有很多)
抓包工具 : fiddler (免费),wireshark 还有很多其他的
针对HTTP的抓包工具 fiddler 使用起来更加简单方便,wireshark也能抓包HTTP的包,同时也能抓ip,tcp,udp,功能更多,使用门槛也更高
1、fiddler抓包
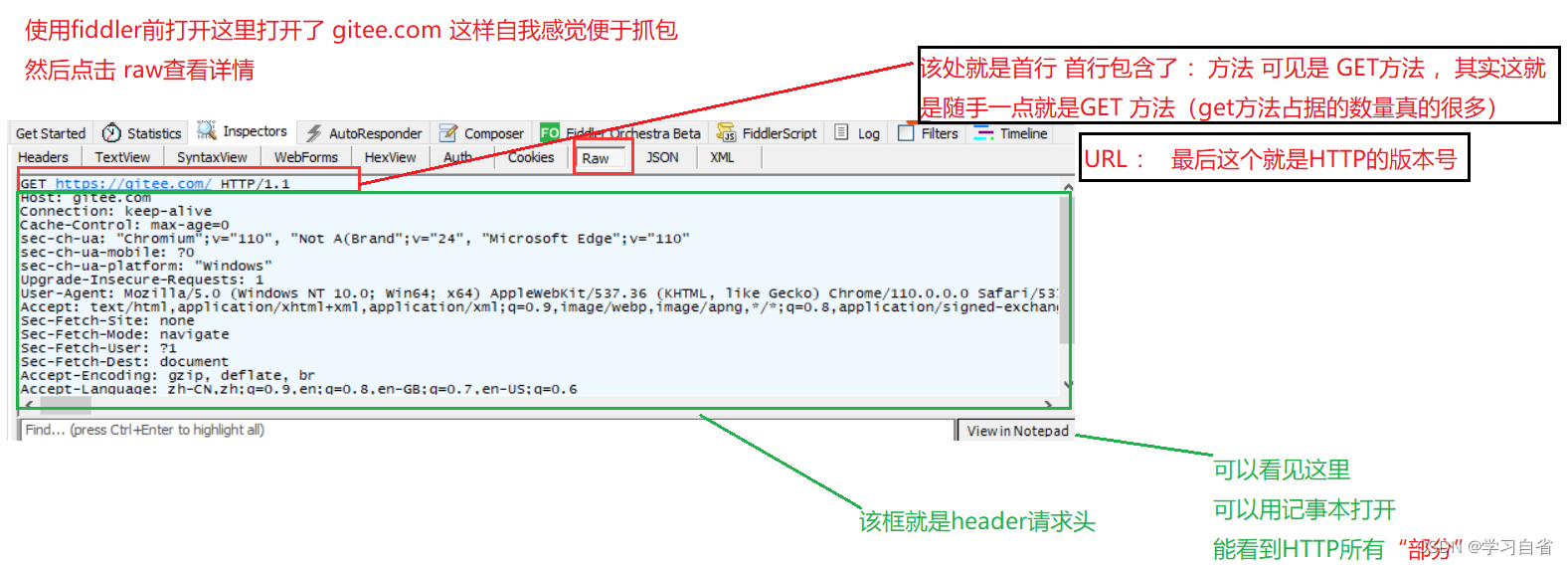
下载安装好以后会的界面:(左侧会显示出当前电脑上某个程序使用HTTP和服务器交互的过程)
fiddler 本质是一个代理程序,使用的时候有两个注意事项
<1>可能和别的代理程序冲突,使用的时候要关闭其他的代理程序(包括一些浏览器插件)
<2>要想正确抓包,还需要开启https功能
https是基于http得来的升级版(安全性能高)
当下互联网上绝大部分的服务器都是https的,fiddler默认不能抓https,需要我们手动气筒一些https并且安装证书

1.1、代理
要点:代理是个啥,就是帮你找你一个做中间管理,你给他说事情的原委,他给你找合适的路子
代理分为两种:正向代理 ,反向代理
正向代理:代表客户端的代理
反向代理:代表服务器的代理
举个例子:厂长他想买一些生活用品,告诉他儿子去超市买,现在他儿子就是客户端代理(正向代理);厂长他儿子就去超市告诉他的超市的好朋友(超市老板的儿子),想要买生活用品,超市老板的儿子代表服务器的代理商(逆向代理商)给他老板说:有人买东西了。
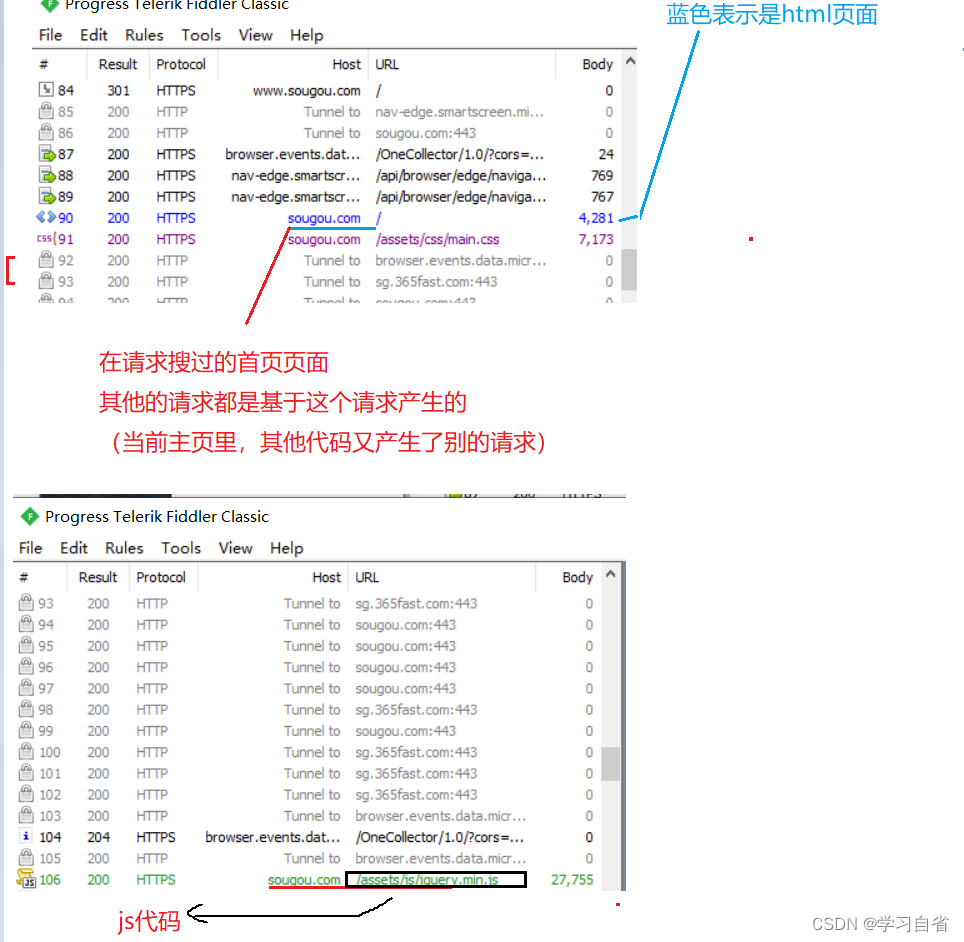
浏览器在访问搜狗主页的时候,产生的http请求,浏览器打开一个页面,对应的http请求可能是一个,也可能是多个(这些请求都是浏览器发送的)
发送多少个请求??? 浏览器在解析执行html和js的时候,遇到一个就发一个
扩展问: 找代理不就会走更多路子,需要中转,中转是为了往好的方向转;
例如:游戏加速器就是代理的话,怎么加速的,平常访问服务器就是随便访问一个就行了,能访问到,能跑就行,游戏加速器会把你访问的服务器尽力调节到更快的服务器上(厂商拉一些专线),所以有的游戏加速器更快(就需要收费了)
查看左侧请求列表中的选项,查看到请求的详细情况
2、HTTP报文格式
![]()
2.1、首行
包含三个部分 之间使用空格来区分 (GET 、URL、还有版本号)
GET: 是HTTP的方法(method)
2.1.1、URL
![]()
上方截图就是URL 俗称“网址”
URL 是唯一资源定位符 标识互联网上的唯一资源的位置(资源在哪个服务器的那个目录下的具体文件)互联网上的具体地址
提到URL就会有相近的URI 唯一资源标识符, 身份标识,为了和别的资源区分开,实际上,URL也课可以起到身份标识的效果,URL也可以视为一个URI
URL
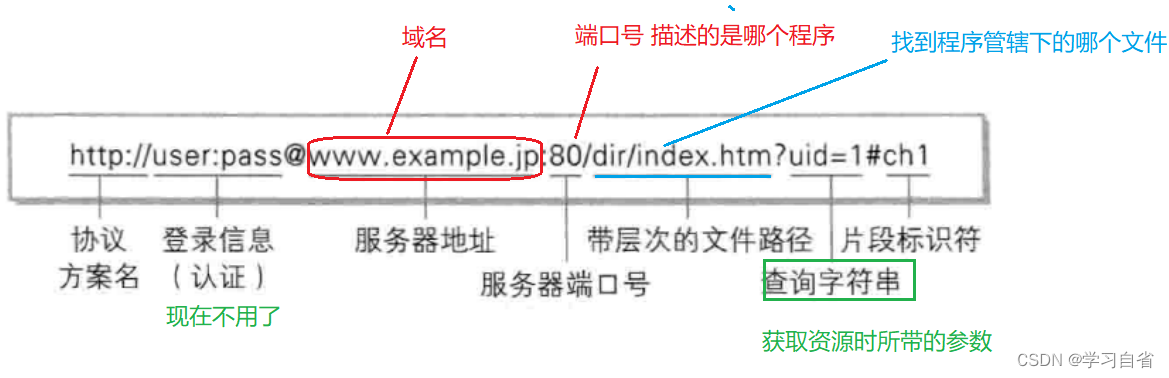
URL:最关键的四个部分 :域名/IP 、端口号、带层次的路径、查询字符串
tcp , ip ,udp 协议格式都是RFC规定的,URL不是HTTP专属的,其他协议也会用到
不用硬性的去理解
举例理解:假如你去恒隆广场吃饭,那总的有个路子的吧(此处的恒隆广场就是例子,因为很多地方都有)
恒隆广场:4楼/半天妖(吃鱼的店名)?味道=中辣&忌口=不要葱&香菜=要
恒隆广场:就是协议名称;
4楼 :就是端口号
半天妖:就是带层次的路径
剩下的部分就是:查询字符串(键值对的形式)
一个URL中可以省略的部分,省略了端口,省略端口的时候,浏览器会提供默认端口,对于http来说默认端口就是80,https默认端口就是443
注:URL :协议名称://IP:端口号/路径?查询字符串
像刚刚提到的www.sogou.com/ 后面就什么也没有了,不是没有了路径;最后一个/代表是的“根目录” 是HTTP服务器的根目录 ,HTTP服务器是系统上的一个进程委托这个服务器管理系统上的一个特定的目录,这个目录里的资源都可以让外面进行访问
管理的根目录,可以是系统上的任意一个目录(http服务器具体的配置)
HTTP协议和HTTP服务器之间怎么处理的,其实就是客户端和服务器是一个道理

一个HTTP服务器提供的资源是很多的,不同路径,拿到的是不同的资源

两者表示的都是不同的界面
此处搜索一个百度搜索,后面会有这么一长串

这里的%e6 怎么表示 % 和 十六进制 数字来进行转义
2.2、方法
方法描述了这次请求的语义

我们常看见就是get和post,其他并不常见,但还是需要作为了解,不带表之后不会使用,get相较于post使用的更多
此处怎么验证 get多的很,可以在fiddler中进行抓包,随时点去看一下(以下解释如何看)
2.2.1、GET请求
(使用位置简述)
<1>在浏览器地址栏里直接输入URL
<2>html里的link,script,img,a等等发送请求都是使用GET
<2>通过JS来构造get
2.2.2、 POST请求
如何看的到POST 一般可以在登录系统上看见,登录会涉及到了跳转POST,或者另一个文件上传
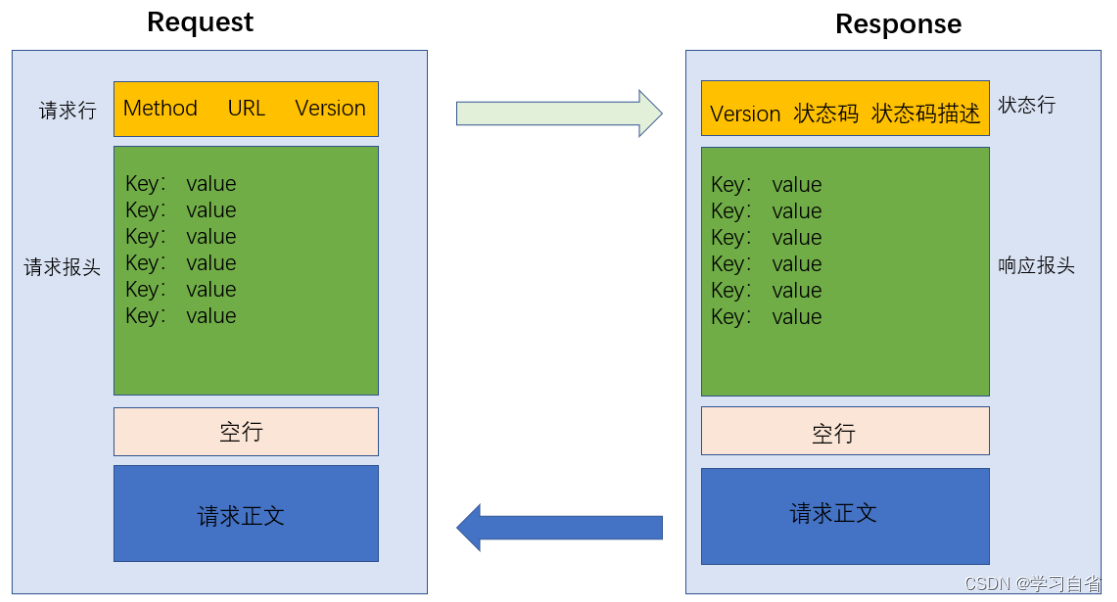
这里叙述HTTP部分:首行、请求头(header)、空行、正文(body)
GET请求 没有body
POST请求 一般有body
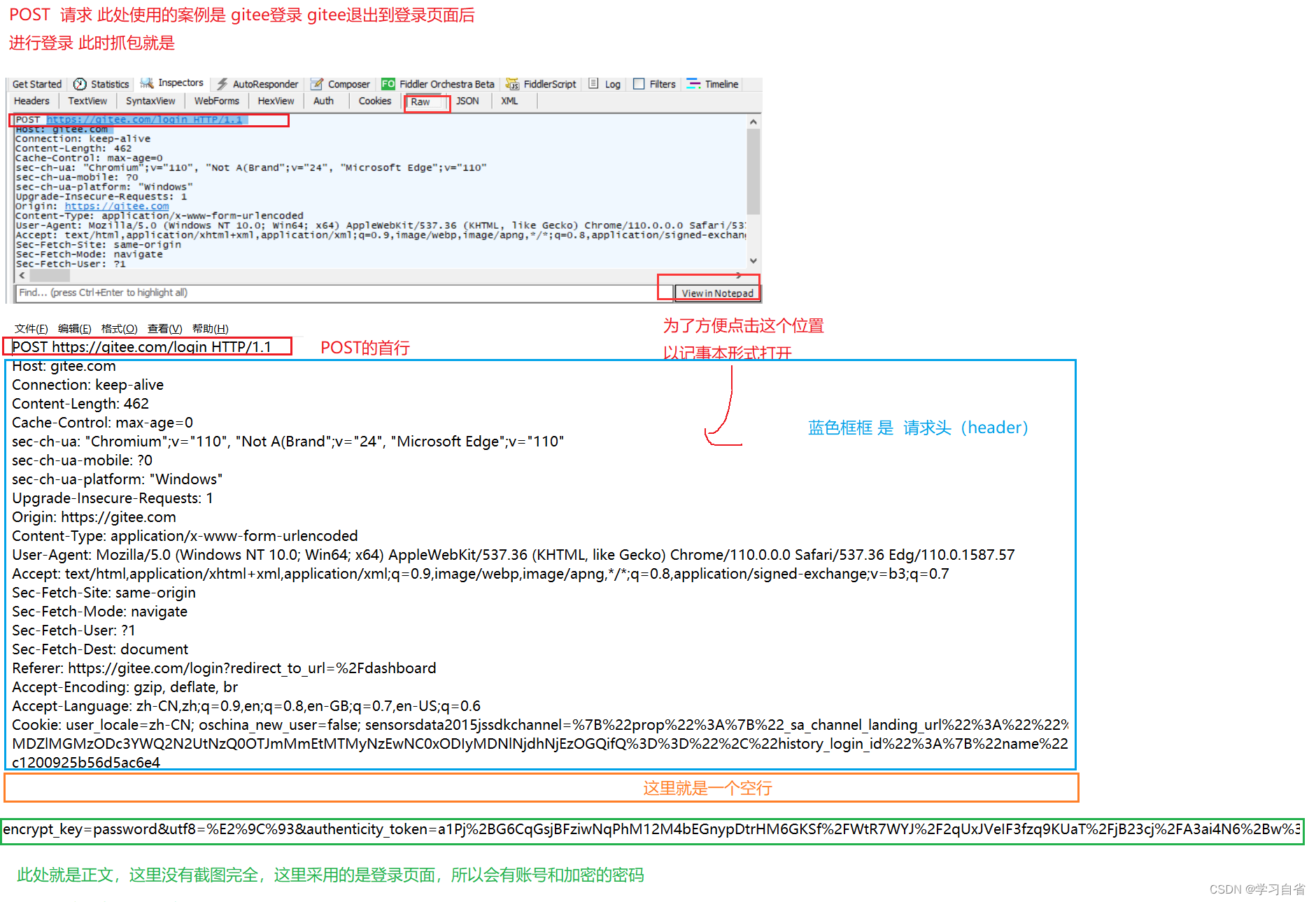
通过抓包结果看POST以记事本打开 其中body是程序员自定义的内容,当然这里账号是能看见的,密码也是加密的(这里的账号在body中一看会很明了)
2.2.3、GET和POST之间的典型区别
GET和POST本质上没有区别(因为在大部分场景下都是可以相互替换的,以下都是习惯用法上的区别)
<1>GET 也可以给服务器传递一些信息,GET传递的信息一般都是放在query string 中;POST传递消息则是通过body
注:GET也不是不能有body,POST也不是不能有query string(不常见)
<2>语义上的差别,GET请求一般是用于从服务器获取数据;POST一般是用于给服务器提交数据
注:可以反过来, GET提交 ,POST获取
<3>GET通常会被设计幂等的;POST不要求幂等
幂等是什么意思:输入相同;幂等是什么意思:相同输入的值,返回的是相同的结果也是确定的结果(可能感觉有点奇怪)
幂等直白说:就是一成不变的(稳定); 非幂等:就是可能相同的操作带来不同结果,例如骰子,每次骰,123456都是有可能的也就是非幂等(不稳定)
注:完全可以把POST设定为幂等 GET不幂等
<4>GET可以被缓存的;POST则一般不能被缓存
缓存(针对这里):把请求的结果保存下来,下次请求就不需要再次请求,直接取缓存结果
扩展:
(1)那GET请求传输的数据存在上限 吗???
比如上限的版本,2KB,1KB等等,过去的浏览器可能是的,但是真的就这么规定吗,(会更新的),HTTP 中GET请求的长度上限在FRC中没有规定
(2)POST比GET更安全 吗???
使用GET请求进行登录的时候,此时用户名密码通过query string 来传递,就会出现浏览器地址栏中显示出来账号和密码会被看见;
安全:敏感信息不会被泄漏
2.3、请求报头
2.3.1、header
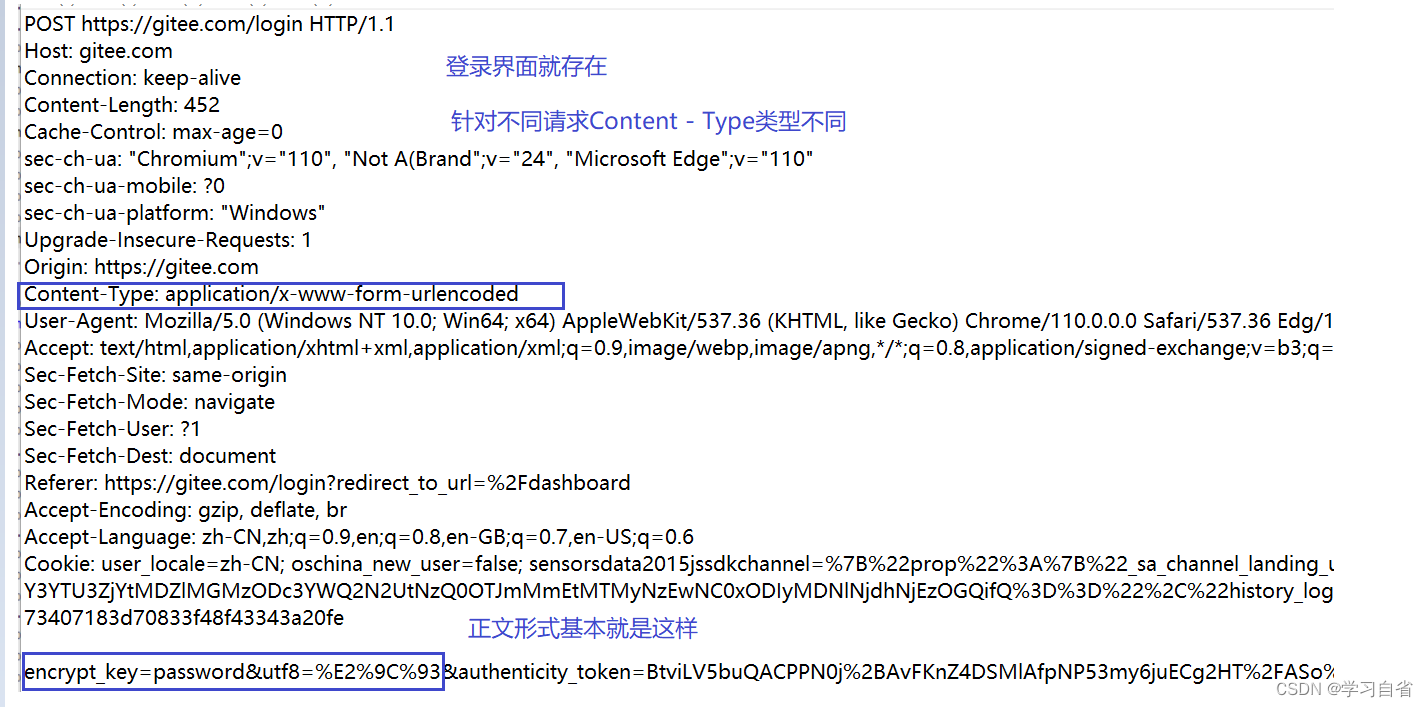
以下是一个POST请求的截图

请求头 中是一堆键值对 (此处 每行是一个键值对,键和值之间使用 “冒号”分割,是HTTP定义好的,有对应的含义)
2.3.2、Host
![]()
作用:描述了服务器所在的 地址 和 端口(都是最终要访问的目标)
内容一定概率和URL中是一样的,也有概率情况不相同
2.3.3、Content-Length
作用:表示body中的数据长度
注:如果是GET请求,没body,自然也就没有该字段;如果是POST请求有该字段
2.3.4、Content-Type
作用:表示请求的body中的数据格式
<1>application/x-www-form-urlencoded: form 表单提交的数据格式.
<2>multipart/form-data: form 表单提交的数据格式(在 form 标签中加上enctyped="multipart/form-data" . 通常用于提交图片/文件.
<3>application/json: 数据为 json 格式.
注:如果是GET请求,没body,自然也就没有该字段;如果是POST请求有该字段
2.3.5、User-Agent(UA)
![]()
作用:描述了浏览器和操作系统的版本
User-Agent后来判定请求针对不同版本(因为针对附加文本,图片,js等),依次针对不同的情况,老浏览器一个版本,新浏览器一个版本,最新的一个版本
现在User-Agent主要用来区分PC和移动(屏幕大小不一,采用“响应式页面”自动适应宽度)
2.3.6、Referer
作用:当前页面的来源,但是不是真正的来源,就像直接通过地址栏输入地址,直接点击收藏夹,都是没有referer,广告我网站就很是如此,你点击很多东西来下载的时候会弹出别的下载,头缸多个平台
注:HTTP为明文传输,很容易获取收到请求内容,也有办法篡改内容,本来是来自网页的请求,referer被改成了别人的(运营商劫持)
2.3.7、Cookie
本质上是浏览器给网页提供的本地存储数据的机制,网页默认不允许访问计算机的硬盘(保证安全)
cookie就是浏览器对于访问硬盘做出的明确限制,cookie通过键值对的方式来组织数据的
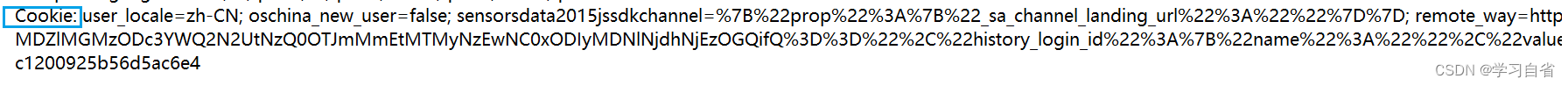
这里都是程序员写的,针对 Cookie的问题
<<1>>Cookie 是从哪来的
Cookie中的数据是来自于服务器的,服务器会通过HTTP响应的报头部分(Set-Cookie字段)服务器来决定浏览器的Cookie要存什么
<<2>>Cookie是在哪存的
可以认为存在浏览器中,存在硬盘,Cookie在存的时候,是按照浏览器+域名维度来进行细分的不同浏览器也有各自不同的cookie,同一个浏览器不同的域名,对应不同的cookie(cookie里的内容不光是键值对,同时还有过期时间,例如:记录登录状态)
<<3>>Cookie要到哪里去
回到服务器这里,客户端同一时刻是有很多的,客户端这边就会通过Cookie来保存当前用户使用中间的状态,当客户端访问浏览器的时候,就会自动的把Cookie的内容带入到请求中,服务器就能够知道现在客户端是啥样子
Cookie里存的是以“上下文”的状态:
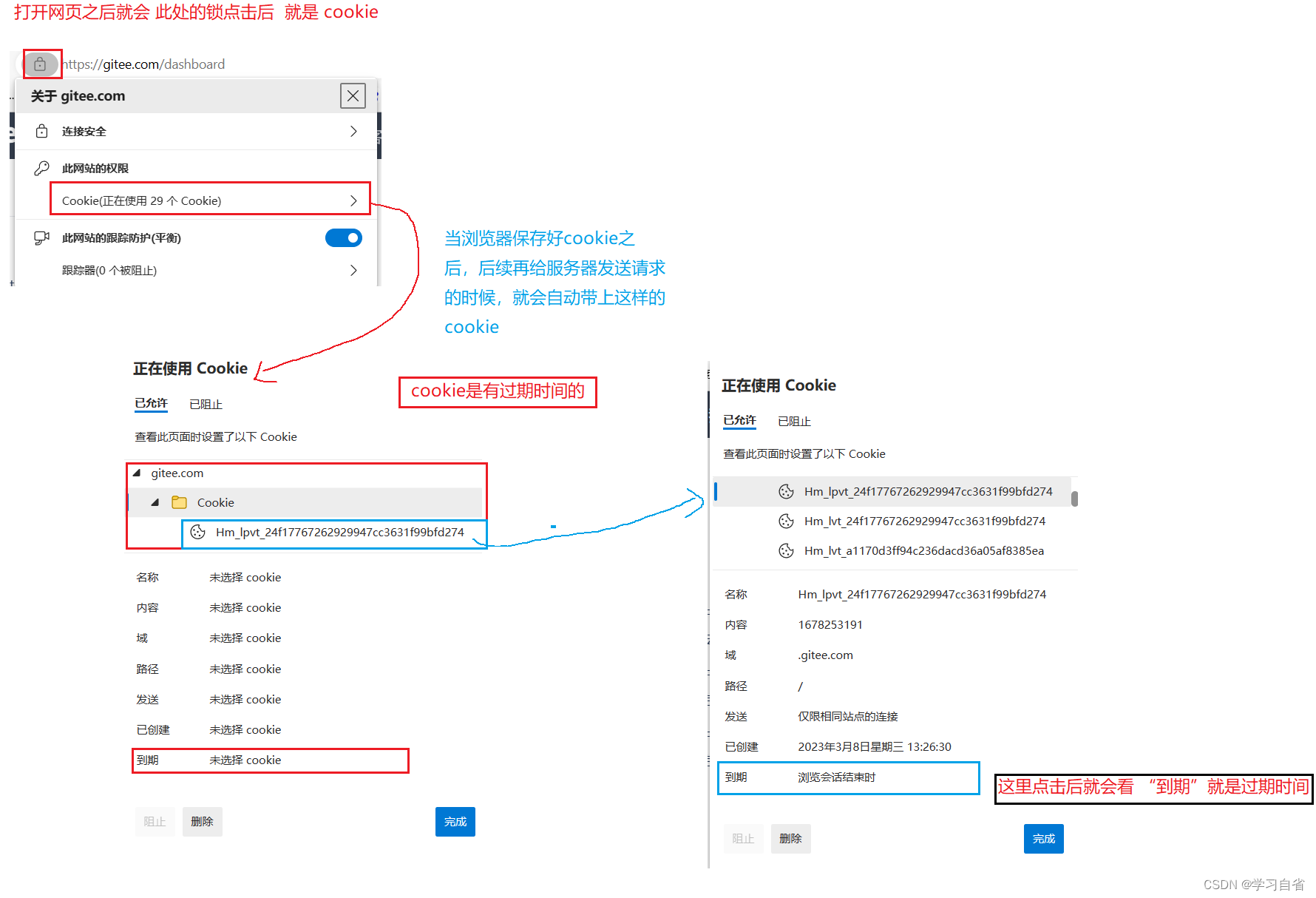
过期时间有啥用呢???
针对公共的电脑,在公共电脑上,登录自己的账号,登录一段时间内保存cookie,下个人使用的时候cookie就过期了,就要求重新登录(看需求而定)
3、HTTP响应
3.1、响应报头(header)
响应报头的基本格式和请求报头的格式基本一致
类似于 Content-Type , Content-Length 等属性的含义也和请求中的含义一致.
3.2、Content-Type
<1>text/html : body 数据格式是 HTML
<2>text/css : body 数据格式是 CSS
<3>application/javascript : body 数据格式是 JavaScript
<4>application/json : body 数据格式是 JSON
以下只是举出例子,因为很多,看后缀其实不难辨认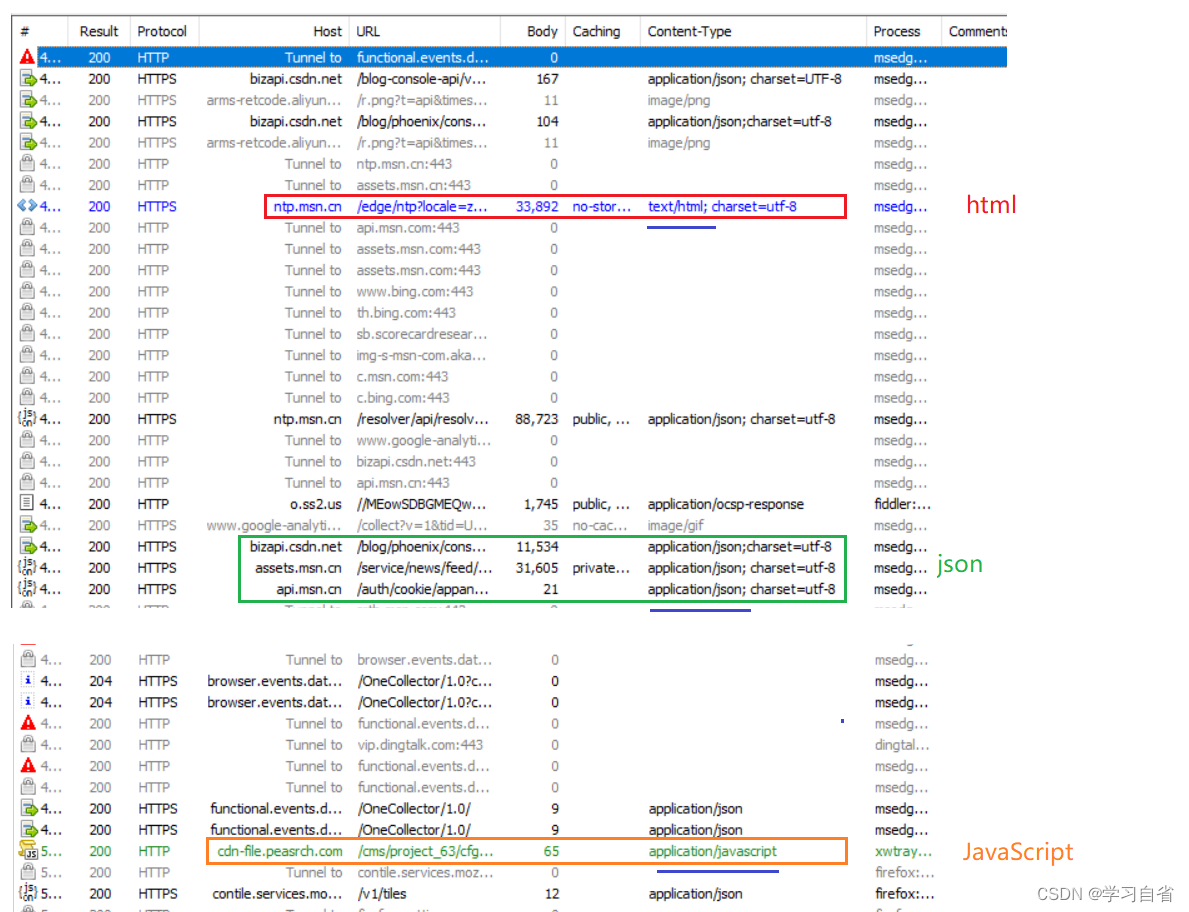
3.3、状态码
状态码作用:描述了这次响应的结果 成功或者失败或者因为什么原因而产生的
那来解析以下不同的三位数字来对应的意义(解释通性和常见的)
200 OK 表示:成功(抓包过程中很常见)
404 Not Found 表示 :访问的资源不存在 或者服务器没有找到
403 Forbidden 表示 : 访问被拒绝(没有权限进行访问)
302 Move temporarily 重定向(很想是电话转接)
重定向举例:一个网站可能更换了网址但是你使用原来的网址仍旧能访问到,通过你访问旧的网址,302响应报文中,会在header里带有个Location属性通过这个属性来描述要跳转到哪个新的地址(直白:如果网站迁移,方便再次访问)
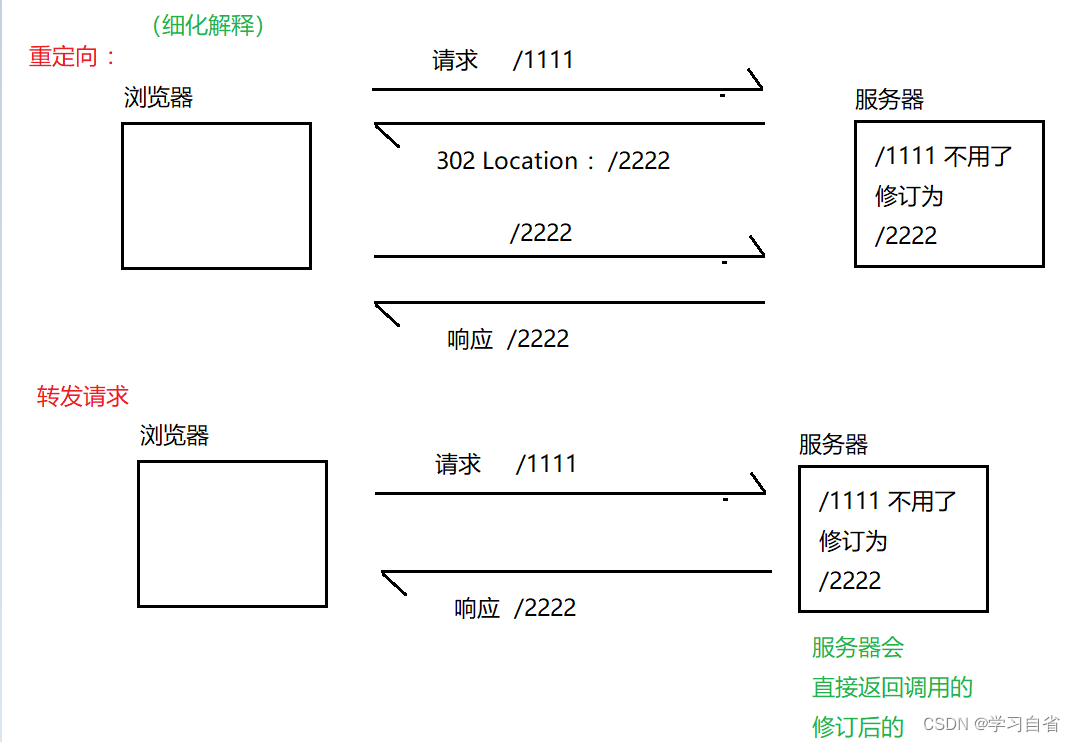
以上图解会产生一个问题:为啥两者情况不一样???
重定向:可以重定向到外部资源的(跳转到别的网站)
请求转发:只能该服务器内部的资源之间转发,少一次交互更高效
状态码可以分为几个大类:
1** :表示服务器正在处理请求的一个状态
2**:请求成功
3**:重定向的响应
4**:客户端请求错误
5**:服务器错误
以上所有为解析HTTP的格式:
3.4、HTTP协议可自定义部分
试问:状态码 能改变吗??不能自主改变
HTTP协议里,还是有不少地方是可以程序员定义的:
<1> URL 中的路径
<2>URL 中的query string
<3>header中的键值对
<4>header中的cookie的键值对
<5>body

















 1120
1120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









