








 超级会员免费看
超级会员免费看

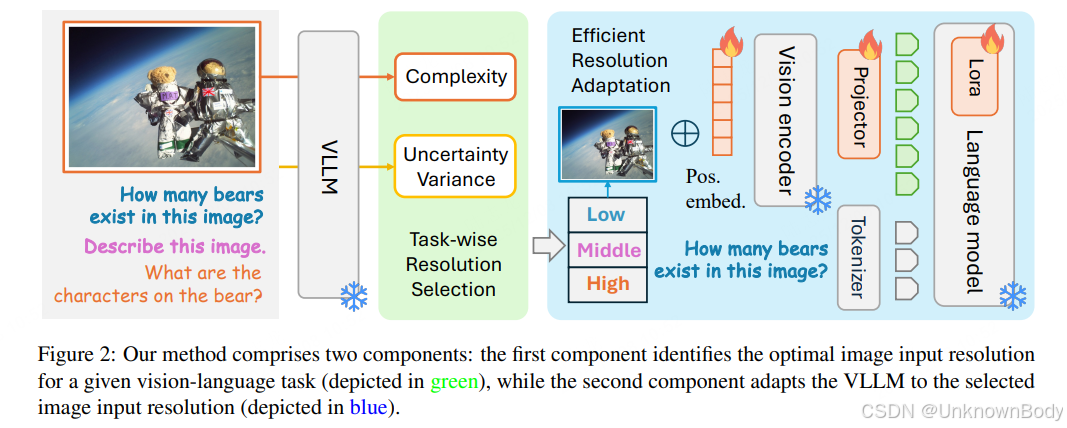
文章核心是提出“任务感知分辨率优化”方案,解决现有VLLM固定分辨率导致的性能问题,主要包含两部分:一是通过图像复杂度和模型不确定性方差确定任务最优分辨率,二是用参数高效微调(PEFT)适配该分辨率,最终在8个视觉语言任务上验证了有效性。
一、文章主要内容总结
- 研究背景与问题
- 现有VLLM(如LLaVA)多采用固定输入分辨率,而实际任务对感知粒度需求不同(如自动驾驶需高分辨率、简单图像分类需低分辨率),导致性能不佳。
- 直接通过“ exhaustive training ”(全量训练不同分辨率模型)适配任务,会产生极高训练成本,因此提出两个核心问题:如何无全量训练确定任务最优分辨率(RQ1)、如何高效适配该分辨率(RQ2)。
- 核心方法
- 任务最优分辨率选择:通过两个启发式指标构建经验公式。一是图像复杂度(基于最小描述长度原理量化图像固有复杂度),二是不确定性方差(衡量模型在不同分辨率下预测不确定性的变化),两者与最优分辨率呈正相关,经验公式为 (Reso(T)=Reso_{0}\cdot (1+k\cdot C(T)\cdot V(T)))((Reso_0)为基线分辨率,(k)为超参数)。
- 参数高效适配(PEFT)<

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1768
1768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











