





 超级会员免费看
超级会员免费看

该文章提出了FedSRD框架,旨在解决联邦学习中大型语言模型(LLMs)微调的通信开销问题,通过“稀疏化-重构-分解”三步流程,在大幅降低通信成本的同时提升模型性能,还提出了计算效率更高的变体FedSRD-e。
一、文章主要内容
- 研究背景
- 现有LLMs依赖公开网络数据训练的模式不可持续,专业领域高质量数据稀缺,且数据隐私问题突出,联邦学习(FL)成为解决去中心化Web下AI训练的关键方案。
- 低秩适应(LoRA)是LLMs高效微调的主流方法,但在联邦场景中,其参数通信开销仍是异构网络环境下的主要瓶颈,且LoRA参数的结构冗余会导致客户端更新聚合时产生冲突。
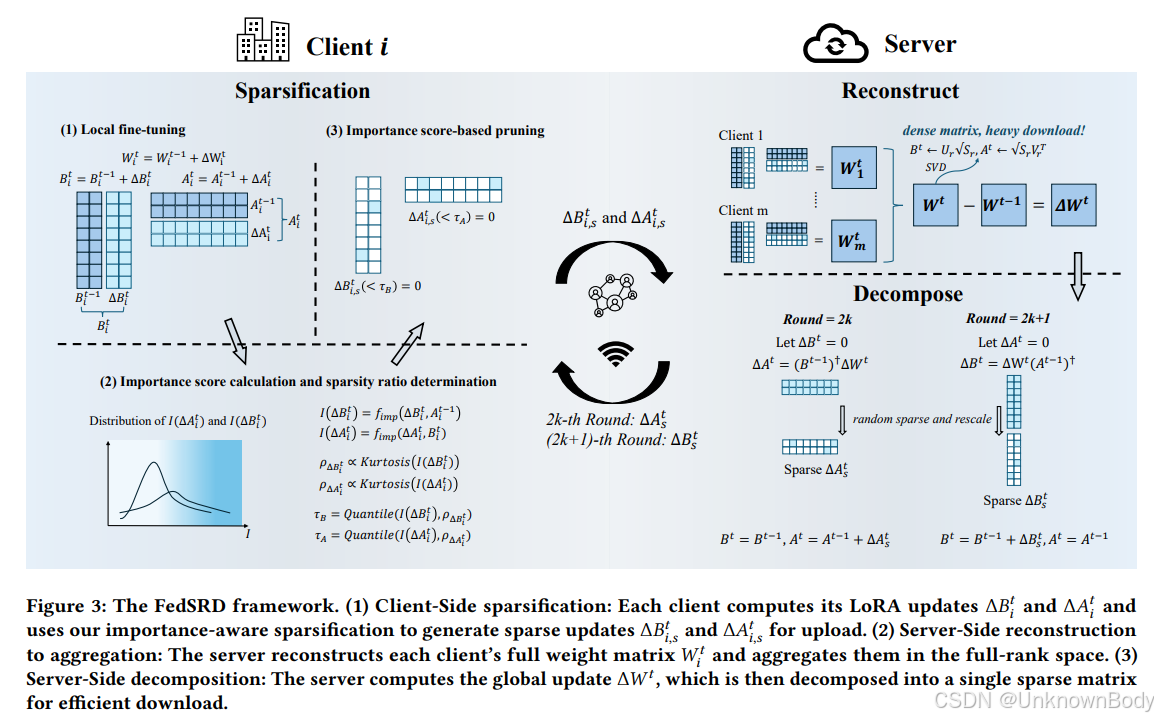
- 核心框架:FedSRD
- 客户端:重要性感知稀疏化:不依赖参数幅值,而是计算更新矩阵元素对低秩更新的贡献度(重要性分数),保留LoRA矩阵的结构关联性;同时根据各层重要性分数分布的峰度,自适应确定每层的稀疏率,重要性集中的层采用高稀疏率,反之则采用低稀疏率。
- 服务器端:重构与聚合:接收客户端稀疏更新后,先重构每个客户端的全秩权重更新矩阵,再在全秩空间进行聚合,从数学上保证聚合的合理性,缓解非独立同分布(non-IID)数据导致的更新冲突。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 529
529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











