








 超级会员免费看
超级会员免费看

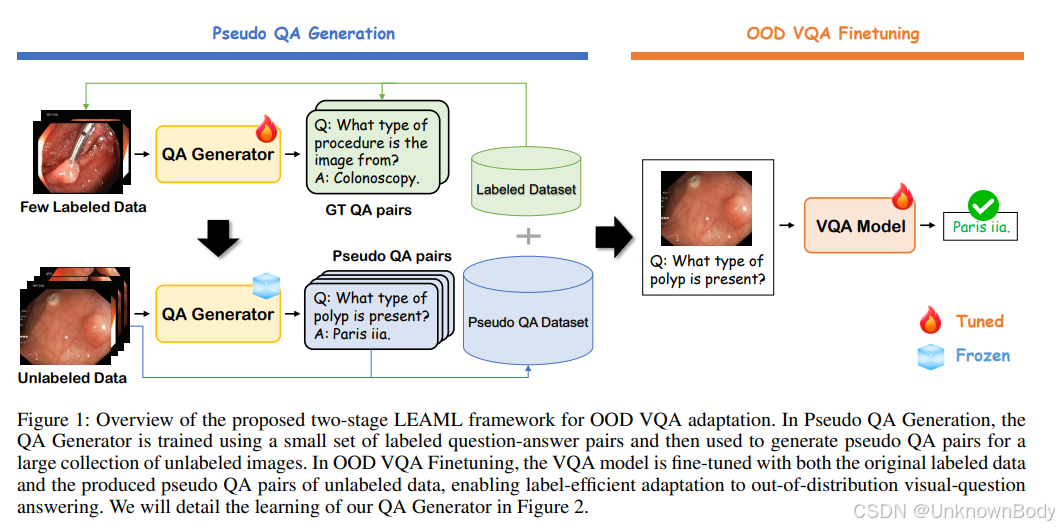
该文章提出LEAML框架,旨在解决多模态大型语言模型(MLLMs)在分布外(OOD)视觉任务中标签数据稀缺的问题,通过伪问答生成和选择性神经元蒸馏,实现高效适应并在医学和体育领域验证了有效性。
一、文章主要内容
- 研究背景:MLLMs在通用视觉基准任务表现优异,但在医学成像、体育分析等专业领域的OOD任务中表现不佳,且这些领域标注数据稀缺昂贵,传统微调易过拟合。
- 核心框架LEAML:分为两阶段,一是伪问答生成(Pseudo QA Generation),用少量标注数据训练QA生成器,结合大型模型生成的图像描述进行蒸馏,为无标注数据生成领域相关伪问答对;二是OOD VQA微调(OOD VQA Finetuning),用标注数据和伪问答对微调目标MLLM。
- 关键技术:引入选择性神经元蒸馏(Selective Neuron Distillation),仅更新与问答生成相关的神经元,确保QA生成器高效获取领域知识,避免学习无关能力。
- 实验验证:在胃肠道内窥镜(Kvasir-VQA)和体育(SPORTU)两个OOD数据集上实验,仅用1%标注数据,LEAML相比传统微调显著提升VQA准确率,尤其在高难度任务上效果突出。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











