








 超级会员免费看
超级会员免费看

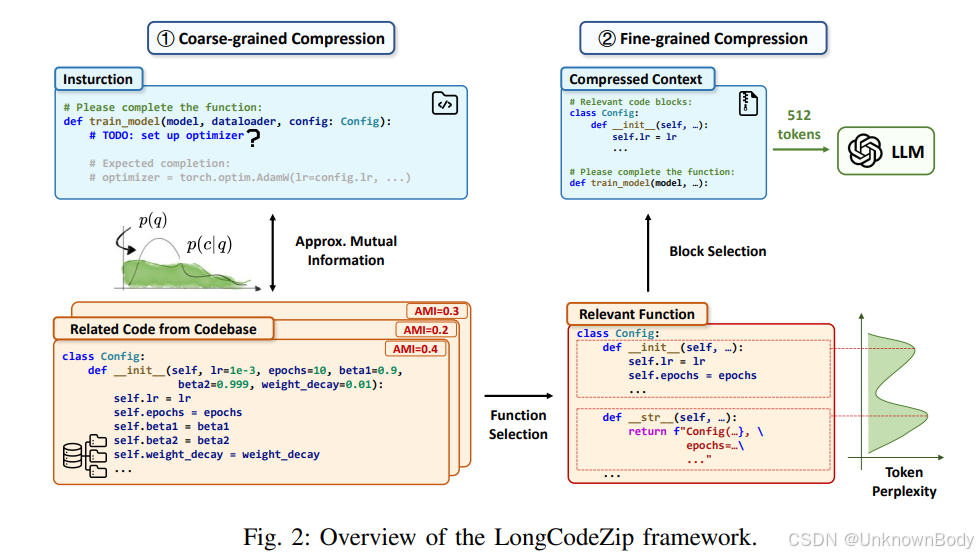
一、论文主要内容总结
1. 研究背景与问题
随着代码大语言模型(Code LLMs)在软件开发中广泛应用(如代码补全、总结、问答),长上下文处理需求日益迫切。但现有方案存在三大瓶颈:
- 效率与成本问题:Transformer注意力机制的二次复杂度导致长输入处理延迟高,API调用成本随token数量剧增;
- 相关性识别困难:模型难以在海量代码中定位关键信息;
- 上下文窗口限制:即使支持128k token的模型,处理大型代码库或长对话时仍会因截断导致输出质量下降。
同时,现有上下文压缩方法存在缺陷:通用文本压缩(如LLMLingua)忽略代码结构与依赖;检索增强生成(RAG)依赖表面语义相似性,易遗漏隐式依赖;传统代码压缩(如DietCode)仅支持函数级修剪,无法应对长上下文场景。
2. 核心方案:LongCodeZip框架
LongCodeZip是专为代码LLMs设计的无训练、模型无关、即插即用的长上下文压缩框架,采用“粗粒度+细粒度”两阶段压缩策略,在减少token消耗的同时保留代码语义:

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











