 Qwen3-Omni多模态技术解析
Qwen3-Omni多模态技术解析









 超级会员免费看
超级会员免费看

一、文章主要内容总结
Qwen3-Omni是一款单模态多任务模型,在文本、图像、音频和视频等多模态任务上均实现了顶尖性能,且相较于单模态模型未出现性能衰减。
1. 核心性能表现
- 跨模态性能均衡:与Qwen系列同规模单模态模型在文本和视觉任务上性能相当,在音频任务上表现突出。在36个音频及视听基准测试中,开源领域有32个达到最优(SOTA),整体有22个达到最优,超越Gemini-2.5-Pro、Seed-ASR、GPT-4o-Transcribe等闭源强模型。
- 多语言与长音频支持:支持119种语言的文本交互、19种语言的语音理解和10种语言的语音生成;可处理单实例最长40分钟的音频录制,用于自动语音识别(ASR)和口语理解。
2. 架构设计
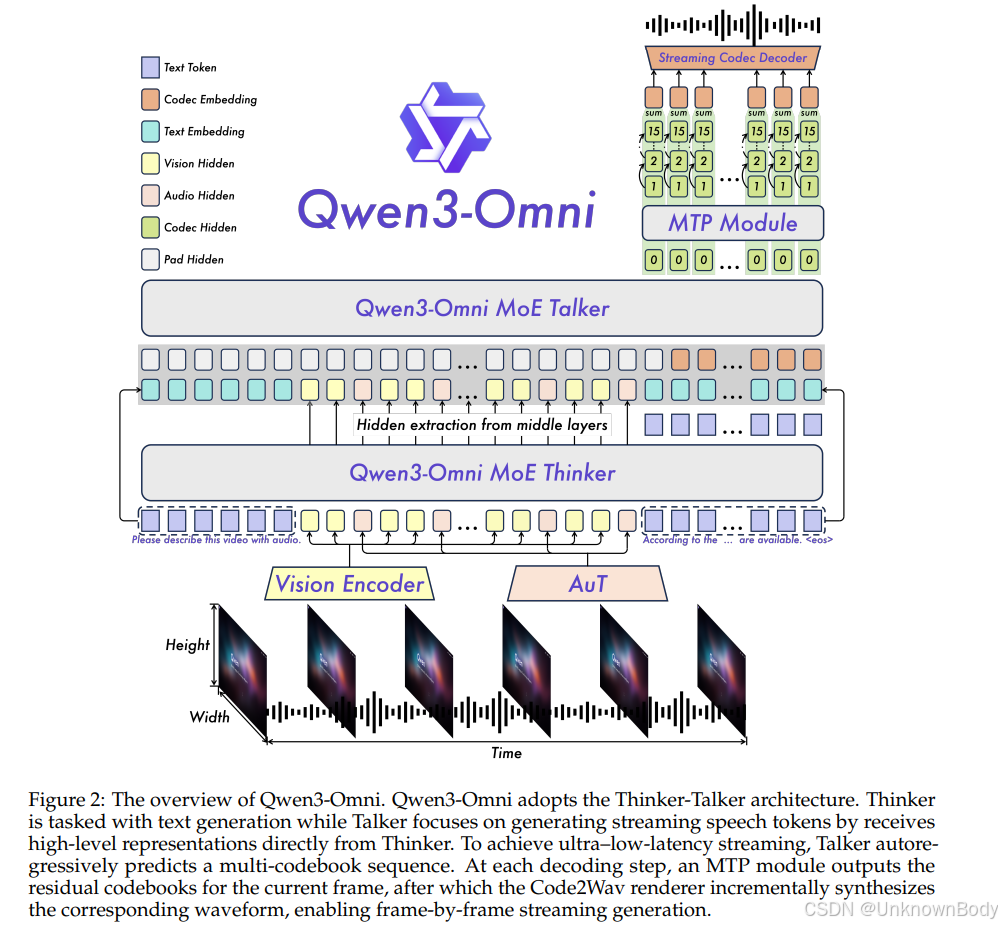
- Thinker–Talker混合专家(MoE)架构:统一文本、图像、音频、视频的感知与生成,实现流畅文本输出和自然实时语音生成。
- Thinker:负责文本生成,采用MoE Transformer架构(30B-A3B参数),支持流式处理,能将多模态输入转换为表征用于后续处理。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1272
1272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











