





 超级会员免费看
超级会员免费看

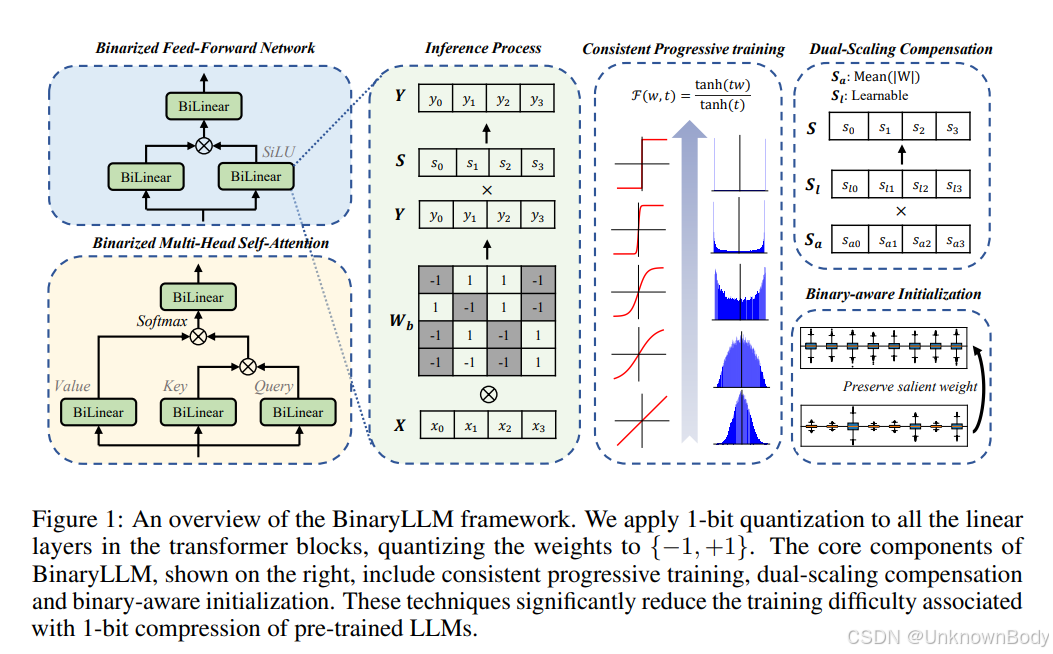
一、文章主要内容
本文聚焦1位大语言模型(1-bit LLM)量化领域,旨在解决现有方法的核心痛点——多数1-bit LLM需从头训练,无法充分利用预训练模型的知识,导致训练成本高、精度损失显著。
首先,文章分析了现有1-bit量化技术的局限:后训练量化(PTQ)如BiLLM、ARB-LLM对不同模型稳定性差,易出现精度崩溃;量化感知训练(QAT)如BitNet、FBI-LLM虽效果稍好,但需从头训练,消耗海量计算资源与数据。同时指出,全精度与1-bit表示差距大,直接量化会严重破坏预训练权重的有效信息。
为解决这些问题,本文提出BinaryLLM框架,核心包含三大技术模块:
- 一致性渐进训练(Consistent Progressive Training):设计渐进近似函数F(x,t)=tanh(tx)/tanh(t)\mathcal{F}(x, t)=\tanh(tx)/\tanh(t)

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











