





 超级会员免费看
超级会员免费看

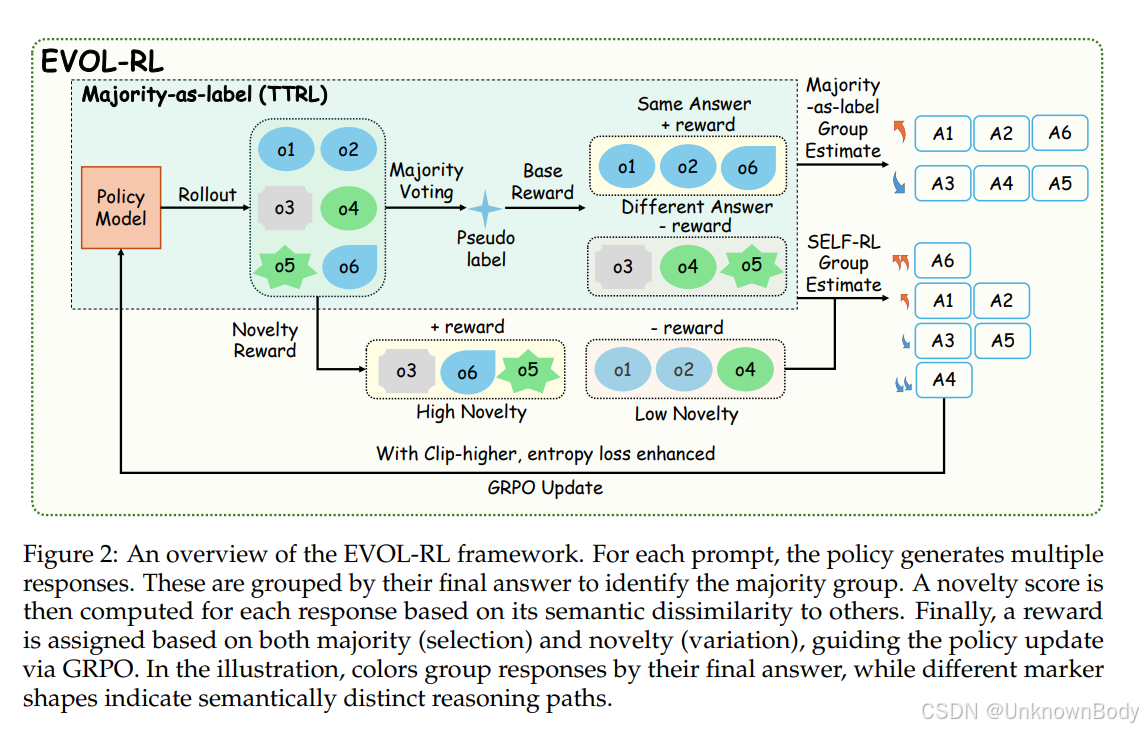
一、文章主要内容总结
本文聚焦大语言模型(LLMs)在无标签场景下的自主进化问题,针对现有无标签方法(如置信度最小化、自一致性、多数投票目标)易导致“熵坍缩”(生成内容更短、多样性降低、鲁棒性差)的缺陷,提出了EVOL-RL(Evolution-Oriented and Label-free Reinforcement Learning,面向进化的无标签强化学习)框架,核心内容如下:
1. 问题背景
- 现有LLMs常依赖带可验证奖励的强化学习(RLVR)训练,但现实部署中需要模型在无标签、无外部评判的情况下实现自改进。
- 传统无标签方法(如测试时强化学习TTRL)虽能稳定学习,但会压缩探索空间,引发“熵坍缩”,且仅能适配即时无标签数据集,无法实现通用能力提升(即“进化”)。
- 文中定义“进化”为模型在当前任务上提升能力的同时,保持甚至增强域外(OOD)任务性能与整体潜力(如pass@k指标),而“适配”往往以牺牲通用能力为代价换取目标数据上的局部收益。
2. EVOL-RL框架设计
EVOL-RL借鉴生物进化“变异产生候选、选择保留有效”的原则,通过“多数投票保稳定(选择)+语义新颖性促探索(变异)”的核心逻辑,平衡学习稳定性与多样性:

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1017
1017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











