





 超级会员免费看
超级会员免费看

一、论文主要内容
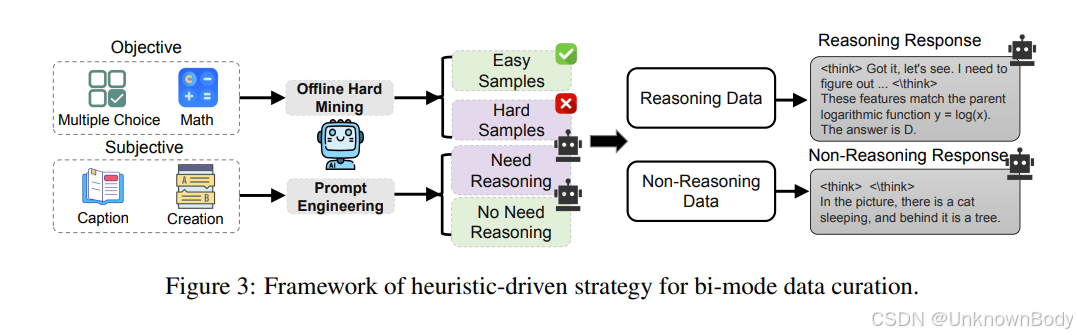
该论文聚焦多模态大型语言模型(MLLMs)在推理过程中的效率问题,提出了名为R-4B的自动思考型MLLM。现有具备逐步思考能力的MLLMs在处理简单问题时,复杂的思考流程会产生冗余,导致效率低下。R-4B的核心目标是让模型能根据问题复杂度自适应决定是否启动思考流程,具体实现分为两步:
- 数据训练阶段:使用精心筛选的、涵盖多个主题的数据集对模型进行训练,该数据集同时包含“思考模式”和“非思考模式”的样本,为模型奠定双模式基础。
- 优化训练阶段:在改进的GRPO(可能为特定强化学习框架)下进行第二阶段训练,强制策略模型对每个输入查询都从“思考”和“非思考”两种模式生成响应,并通过双模式策略优化(BPO)提升模型判断是否启动思考流程的准确性。
实验结果显示,R-4B在25个具有挑战性的基准测试中实现了最先进(state-of-the-art)的性能:在大多数任务上优于Qwen2.5-VL-7B,且在推理密集型基准测试中,以更低的计算成本达到了与更大规模模型(如16B参数的Kimi-VL-A3B-Thinking-2506)相当的性能。
二、论文创新点
- 自适应思考机制:突破现有MLLMs“要么全程思考,要么全程不

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 4552
4552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











