




 超级会员免费看
超级会员免费看
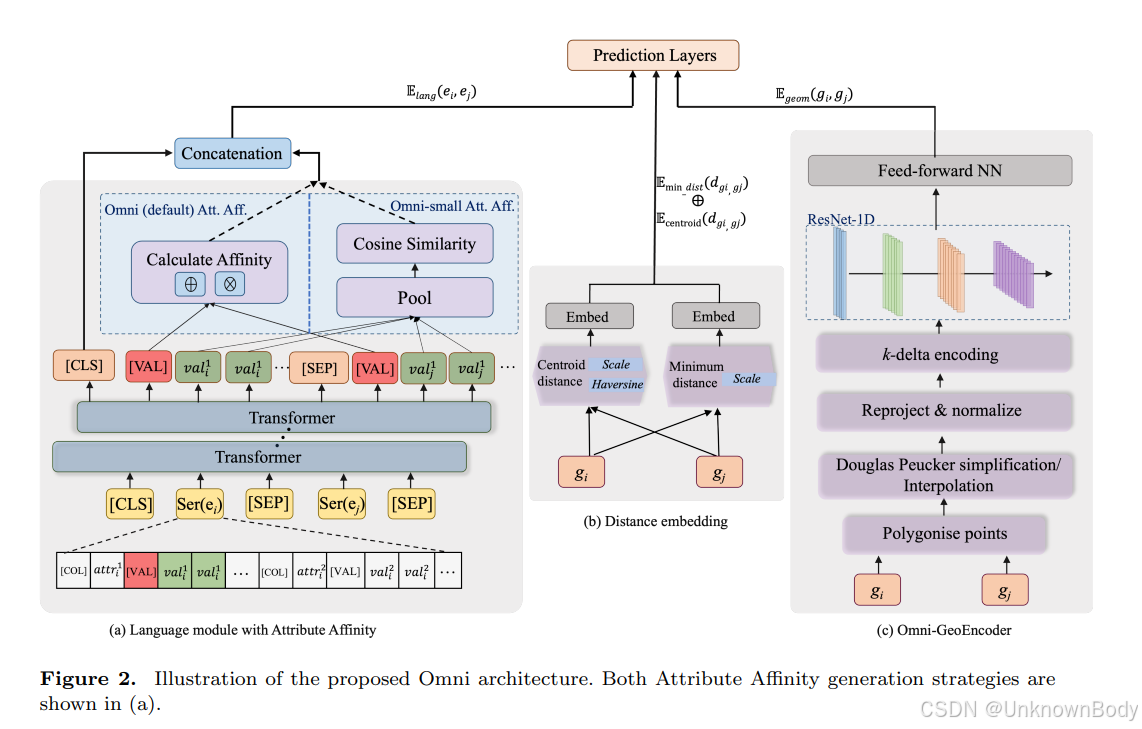
文章总结与翻译
一、文章主要内容
该研究聚焦地理空间实体解析(Geospatial Entity Resolution, ER)问题,针对现有方法多局限于兴趣点(POI)的点几何数据、忽略复杂几何类型(线、折线、多边形等)导致空间信息丢失的缺陷展开研究,主要内容如下:
- 问题背景:地理空间数据库的开发、集成和维护依赖高效准确的地理空间ER,但现有神经方法常将复杂几何简化为单点,丢失关键空间信息;同时,大语言模型(LLMs)在通用ER中表现优异,却未被应用于地理空间ER场景。
- 模型提出:设计Omni模型,包含三个核心模块——语言模块(结合Attribute Affinity机制捕捉文本属性语义相似性)、地理距离模块(融合质心距离与最小距离)、Omni-GeoEncoder(统一编码点、线、多边形等多种几何类型),实现文本与空间信息的深度融合。
- 数据集构建:创建首个公开的多几何类型地理空间ER数据集NZER,涵盖新西兰5个地区,结合OpenStreetMap(OSM)、GeoNames(GN)等多源数据,标注多语言地名与复杂几何实体。
- 实验验证:在点几何数据集(如GeoD)和多几何数据集(如SGN、GTMD、NZER)上开展实验,对比Omni与现

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 599
599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











