








 超级会员免费看
超级会员免费看

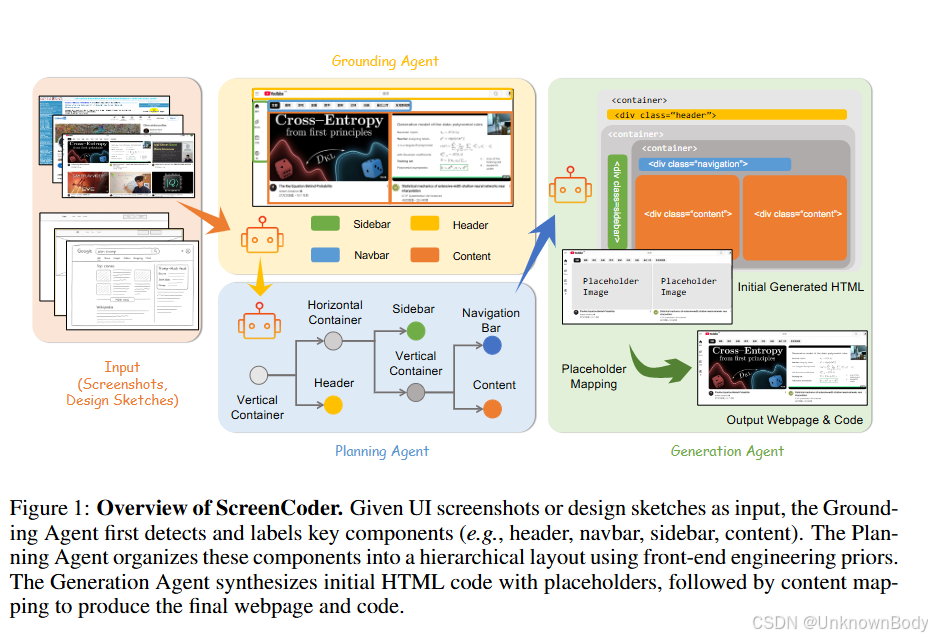
文章主要内容总结
本文提出了一个名为ScreenCoder的模块化多智能体框架,旨在解决将用户界面(UI)设计自动转换为前端代码(HTML/CSS)的问题。该框架通过三个可解释的阶段实现UI到代码的生成:
- ** grounding阶段**:利用视觉-语言模型(VLM)检测并标记UI组件(如侧边栏、页眉、导航栏等);
- ** planning阶段**:结合前端工程知识构建层级布局树,明确组件的空间关系和结构;
- ** generation阶段**:通过自适应提示合成生成HTML/CSS代码,并支持用户自然语言指令的交互设计。
此外,该框架还扩展为一个可扩展的数据引擎,能自动生成大规模图像-代码对,用于对开源VLM(如Qwen2.5-VL)进行冷启动监督微调与强化学习,显著提升其UI理解和代码生成能力。实验表明,ScreenCoder在布局准确性、结构一致性和代码正确性上达到了当前最优性能。
创新点
- 系统分析现有VLM的局限性:明确指出现有视觉-语言模型在UI到代码生成任务中存在的两大失效模式——理解错误(组件遗漏或误分类)和规划错误(组件位置错误或违反布局约束)。
- 模块化多智能体框架:将UI到代码生成任务分解为grou

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











