








 超级会员免费看
超级会员免费看

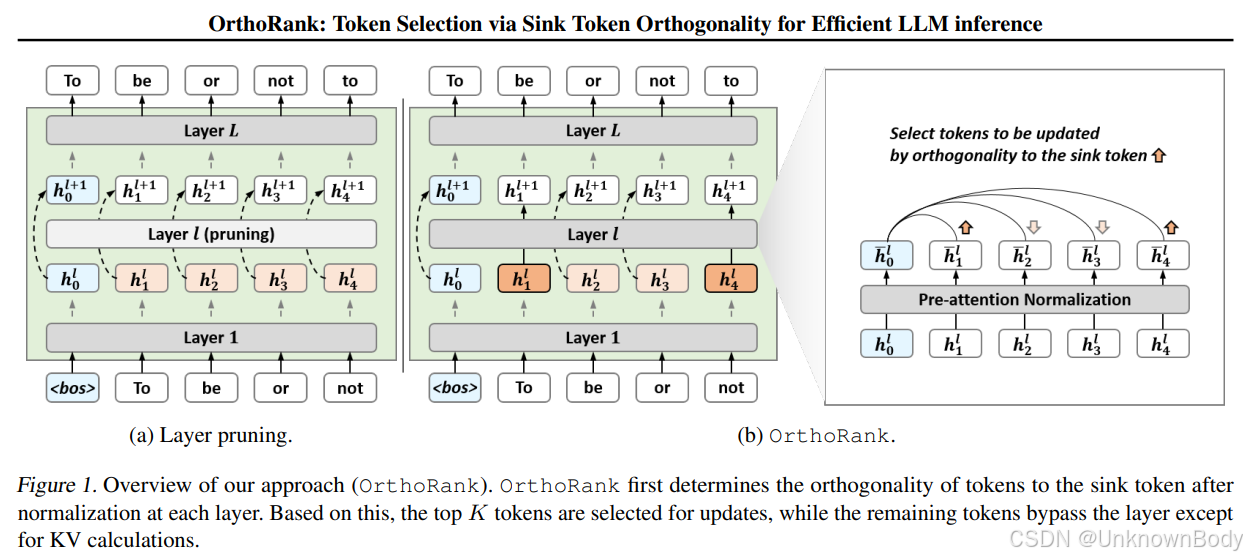
文章主要内容总结
本文围绕大型语言模型(LLMs)推理效率的优化展开,提出了一种基于sink token正交性的动态token选择方法OrthoRank,以降低计算成本并保持模型性能。
-
核心观察:
- 分析发现,在LLMs中,sink token(通常为输入序列的第一个token)的归一化隐藏状态在深层中几乎不变,而其他token的归一化隐藏状态与sink token的余弦相似度随层数加深逐渐增加,即其他token在不断向sink token“靠近”。
-
OrthoRank方法:
- 基于上述观察,定义token的重要性为其与sink token的正交性(正交性越高,重要性越大),因为正交性高的token仍有较大潜力提升与sink token的相似度,需要继续处理。
- 动态选择正交性高的token进行完整层计算,未被选中的token仅参与键值(KV)计算而不更新自身状态,类似早期退出机制但无需额外训练。
-
实验结果:
- 在相同稀疏率下,OrthoRank的困惑度(perplexity)更低,零样本任务准确率更高,且在LongBench长文本任务

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











