







 超级会员免费看
超级会员免费看
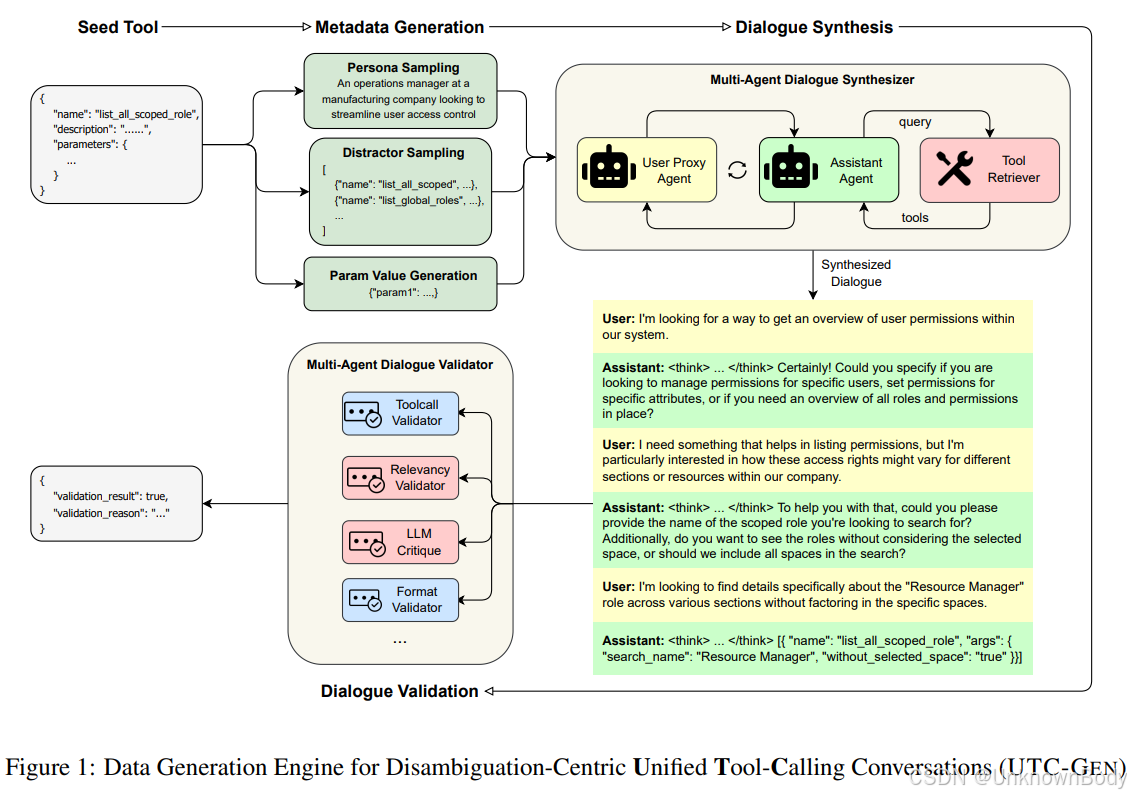
文章主要内容总结
本文针对大型语言模型(LLMs)在调用企业API时存在的工具歧义识别困难、参数缺失处理能力不足等问题,提出了一个以消歧为核心的三阶段框架DIAFORGE(Dialogue Framework for Organic Response Generation & Evaluation)。该框架包括:
- 合成对话生成:通过多智能体引擎UTC-GEN生成基于角色的多轮对话,聚焦于相似工具的区分和缺失参数的获取;
- 监督微调:利用包含推理轨迹的数据对3B–70B参数的开源模型进行微调;
- 动态评估:通过动态基准测试DIABENCH,在实时代理循环中评估模型的端到端目标完成度,并结合静态指标综合判断其实用性。
实验结果显示,经DIAFORGE训练的模型在工具调用成功率上显著优于GPT-4o(提升27个百分点)和Claude3.5-Sonnet(提升49个百分点)。此外,作者还公开了包含约5,000个企业级API规范及消歧对话的数据集,为构建可靠的企业级工具调用代理提供了实践蓝图。
创新点
- 消歧驱动的合成数据生成:通过多智能体模拟生成聚焦于相似工具区分和参数补全的多轮对话,针对性解决LLMs在

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 9803
9803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











