








 超级会员免费看
超级会员免费看

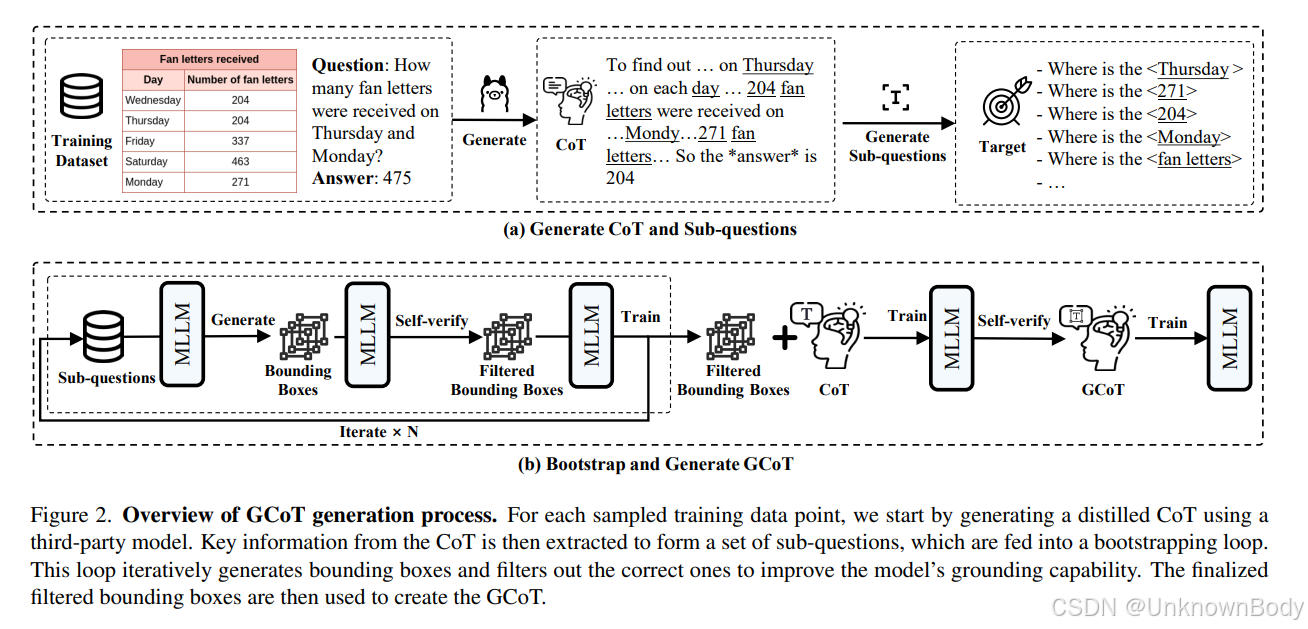
文章主要内容总结
本文聚焦多模态大型语言模型(MLLMs)在数据有限场景下对专业视觉任务(如图表、表格、收据、报告等)的适应问题。研究发现,思维链(CoT)数据能促进模型适应,但从预训练MLLMs蒸馏出的CoT数据存在中间推理步骤的事实错误。为此,作者提出Grounded Chain-of-Thought(GCoT) 方法,通过注入边界框等接地信息,使推理步骤更忠实于输入图像,并采用自举(bootstrapping)策略迭代生成和优化接地信息(通过自验证过滤错误)。在五个专业视觉数据集(ChartQA、TabMWP、SROIE、DVQA、TAT-QA)上的实验表明,在数据有限情况下,GCoT显著优于零样本、微调及直接使用CoT蒸馏等方法,验证了其有效性。
创新点
- 发现CoT数据的价值与局限:首次指出CoT数据可促进模型从通用视觉任务向专业任务适应,但预训练MLLMs生成的CoT数据存在推理步骤的事实错误。
- 提出GCoT方法:通过自举策略注入自验证的接地信息(边界框),修正CoT数据的错误,使推理更忠实于输入图像,提升数据质量。
- 验证数据有限场景的有效性:在五个涵盖多种视觉格式的专业任务上,证明GCoT在少样本(如8-128个样本)情况下显著优于现有基线,为数据

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 137
137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











