





 超级会员免费看
超级会员免费看

文章主要内容
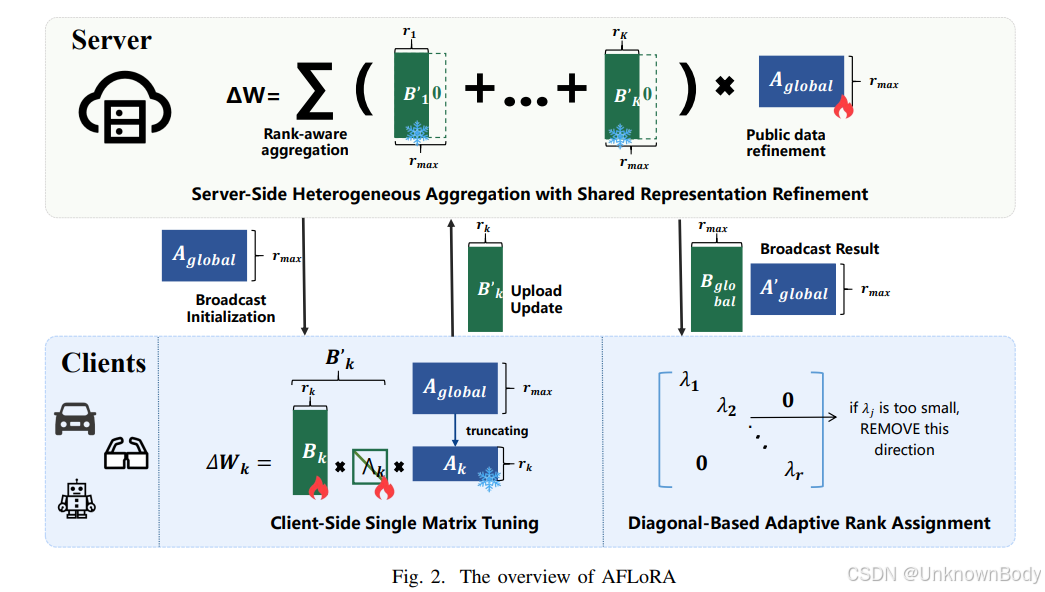
本文针对异构资源和非独立同分布(Non-IID)数据环境下大型语言模型(LLMs)的联邦微调问题,提出了一种名为AFLoRA的自适应轻量级联邦微调框架。该框架通过以下核心机制解决现有挑战:
- 解耦更新机制:将LoRA的低秩矩阵分解为共享矩阵A(服务器端优化)和客户端特定矩阵B(客户端优化),减少聚合干扰并平衡泛化能力与领域知识。
- 基于对角矩阵的动态秩剪枝:引入可学习的对角矩阵Λ,根据客户端数据特征和资源动态调整有效秩,剔除低信息维度,降低冗余和通信开销。
- 秩感知聚合与公共数据优化:通过零填充对齐不同秩的矩阵,结合数据规模和秩权重进行聚合,并利用服务器端公共数据优化共享矩阵A,提升模型在Non-IID场景下的泛化能力。
实验结果表明,在通用数据集(如WizardLM、Databricks-Dolly)和领域数据集(如FinGPT-Sentiment、AG News)上,AFLoRA相比FLoRA、HETLoRA、FlexLoRA等基线方法,在模型准确率和计算/通信成本上均表现更优,尤其在异构资源和Non-IID数据分布下优势显著。
文章创新点
- 解耦式LoRA架构:分离共享矩阵A和客户端矩阵

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1495
1495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











