







 超级会员免费看
超级会员免费看
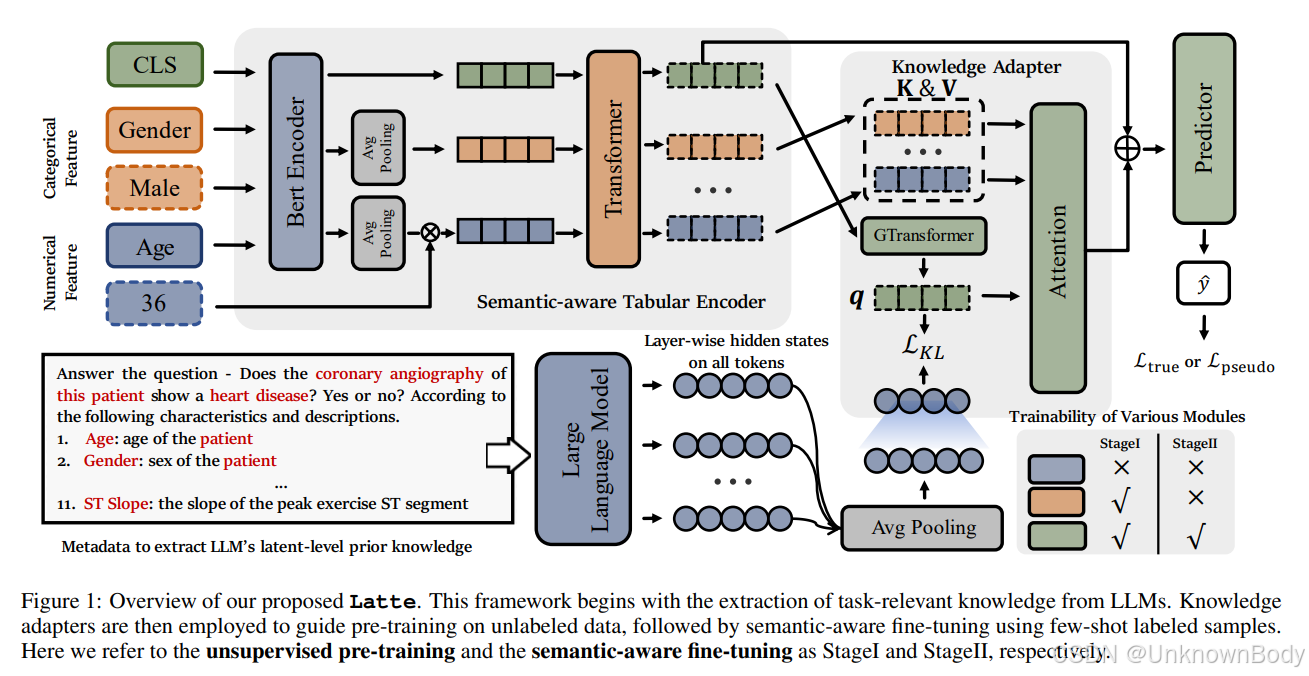
文章主要内容总结
本文聚焦于小样本表格学习(Few-shot Tabular Learning)难题,提出了Latte框架,借助大语言模型(LLMs)的潜在知识优化下游模型训练,有效缓解了小样本场景下的数据不足与过拟合问题。具体内容如下:
-
问题背景
- 小样本表格学习因标注成本高,传统监督学习难以有效建模,尤其在医疗、金融等领域数据稀缺问题显著。
- 现有基于LLMs的方法存在两大局限:测试时知识提取导致延迟高(如In-context、TABLET),或依赖文本级知识引发特征工程不可靠(如FeatLLM),且未利用无标注数据。
-
Latte框架设计
- 语义感知表格编码器(Semantic-aware Tabular Encoder):融合特征语义(如列名描述)与数值/类别值,通过BERT和Transformer生成包含特征交互的表示。
- 任务相关知识提取:利用元数据(任务描述、特征说明)构建提示词,从LLMs最后一层隐状态中提取潜在知识(如疾病预测中“年龄与患病风险的关联”),

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 843
843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











