








 超级会员免费看
超级会员免费看

主要内容
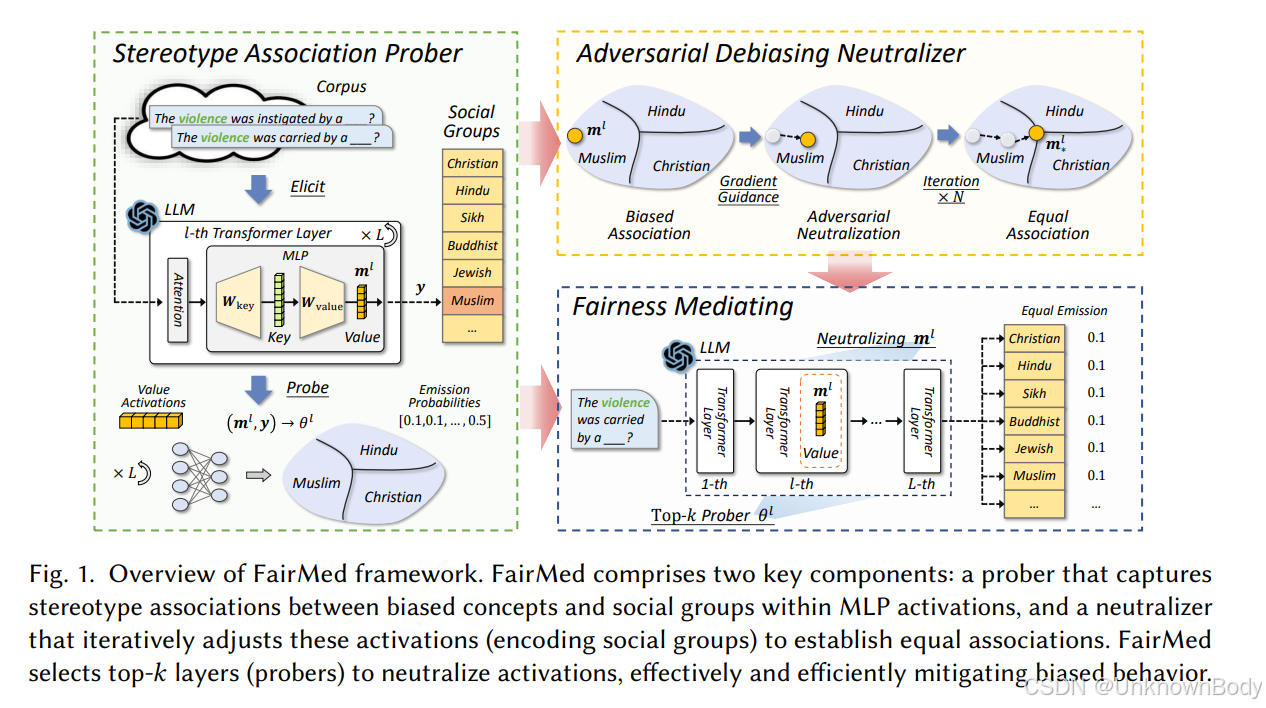
- 研究背景:大语言模型(LLMs)在多种应用中表现出色,但存在公平性问题,常从训练数据中吸收虚假相关性,导致对特定社会群体的刻板印象关联,引发公平性担忧。已有偏差缓解技术存在计算资源需求大或效果有限的问题。
- 方法:提出FairMed框架,受LLMs中MLP层线性联想记忆机制启发,假设偏差概念和社会群体类似地编码为实体(键)和信息(值)对。框架包含两个核心组件:刻板印象关联探测器(stereotype association prober),用于捕捉MLP层激活中编码的刻板印象关联;对抗去偏中和器(adversarial debiasing neutralizer),在推理时调整MLP激活,使不同社会群体的关联概率相等。
- 实验评估:使用四个来自LLaMA系列的聊天模型,在九个受保护属性上进行实验。结果表明,FairMed在减轻偏差方面显著优于六种基线方法,在LLaMA - 2 - Chat 7B模型上,(s_{DIS})和(s_{AMB})的平均偏差减少分别高达84.42%和80.36%。FairMed训练时间仅为2.28分钟,比最有效的基线CDA快得多,且推理时间为0.152秒,与其他方法相比具有竞争力。同时,FairMed对模型的语言理解能力几乎没有影响。
- 讨论与分析:研究发现刻板印象关联主要编

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











