








 超级会员免费看
超级会员免费看

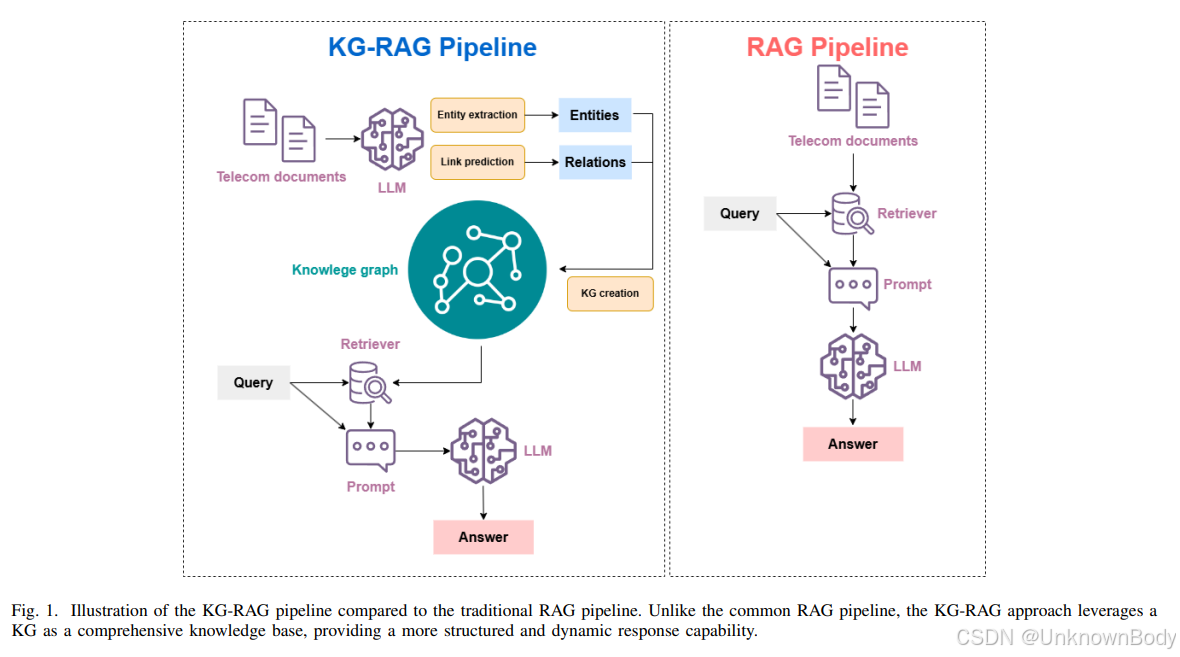
文章主要内容总结:
本文提出了一种结合知识图谱(KG)和检索增强生成(RAG)的框架(KG-RAG),旨在提升大型语言模型(LLM)在电信领域的专业能力。传统LLM在通用任务表现出色,但在电信等专业领域存在知识更新滞后、结构化推理不足等问题。作者通过构建电信领域KG,整合网络协议、标准、硬件组件等实体及其关系,并通过RAG动态检索相关知识片段,辅助LLM生成更精准的回答。实验表明,KG-RAG在Tspec-LLM数据集上的问答准确率达88%,显著优于RAG-only(82%)和LLM-only(48%)。
创新点:
- 领域知识结构化:首次将知识图谱与RAG结合,构建电信领域KG,解决LLM对结构化知识的动态利用问题。
- 混合检索机制:通过语义相似性、TF-IDF和实体匹配多维度优化检索,提升知识片段与问题的相关性。
- 动态适应性:利用KG的更新灵活性,解决电信标准快速演进导致的模型过时问题。
Abstract
大型语言模型(LLMs)在通用自然语言处理任务中取得了重大进展。然而,当应用于电信等需要专业知识和适应标准快速演进的领域时,LLMs仍面临挑战。本文提出了一种结合知识图谱(KG)和检索增强生成(R

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 471
471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











