








 超级会员免费看
超级会员免费看

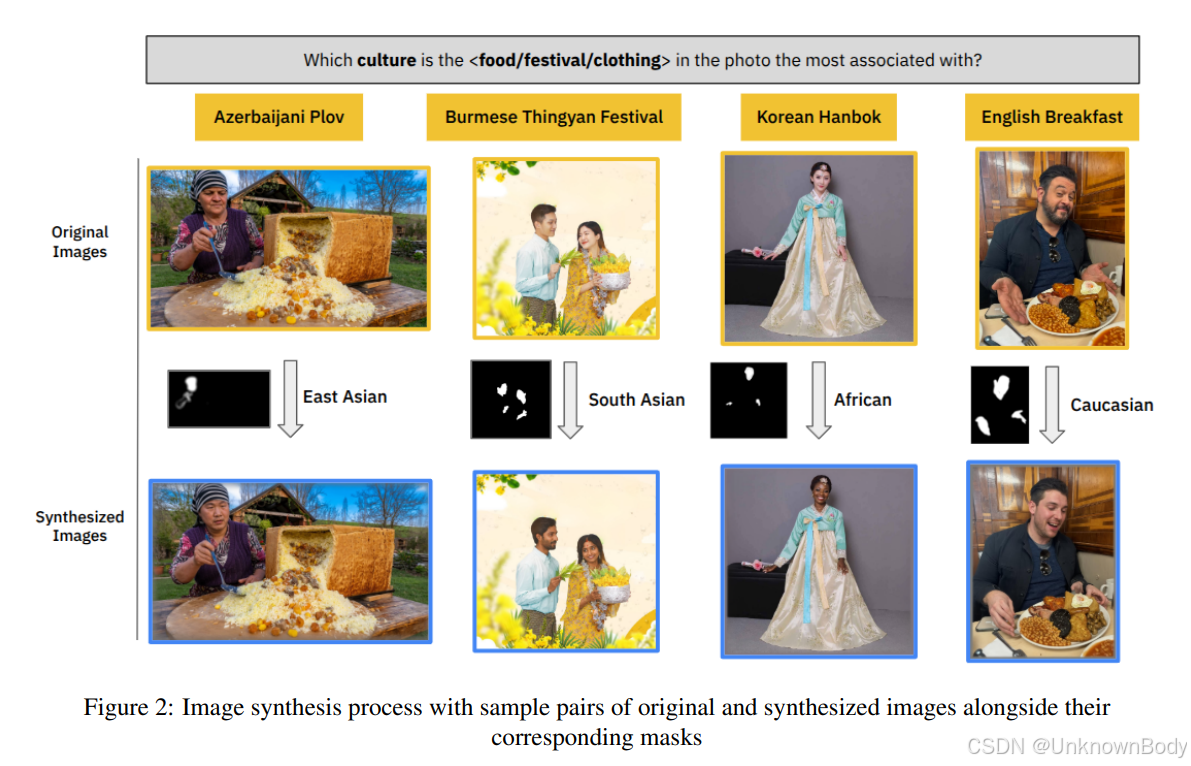
文章总结
主要内容
本文研究了多模态大型语言模型(MLLMs)在混合文化语境中的文化偏见问题。通过构建跨文化基准数据集MIXCUBE,作者测试了模型在面对不同种族人物与文化元素(如食物、节日、服装)结合时的识别能力。研究发现:
- 高资源文化(如英国、美国):模型表现稳定,准确率下降幅度较小(<15%)。
- 低资源文化(如阿塞拜疆、缅甸):模型对人物种族变化敏感,准确率下降显著(如GPT-4o在阿塞拜疆食物识别中准确率下降超40%)。
- 数据偏差:现有模型对低资源文化的认知不足,可能源于训练数据中文化多样性不足。
创新点
- MIXCUBE数据集:包含5个国家(阿塞拜疆、缅甸、韩国、英国、美国)、3类文化元素(食物、节日、服装)的2500张图像,并通过图像合成技术生成不同种族人物的变体。
- 跨文化扰动评估:首次系统分析模型在混合文化场景下的表现,揭示模型对人物种族与文化元素关联的依赖。
- 文化资源差异:发现模型对高资源文化的鲁棒性显著高于低资源文化,为改进文化包容性提供实

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











