







 超级会员免费看
超级会员免费看
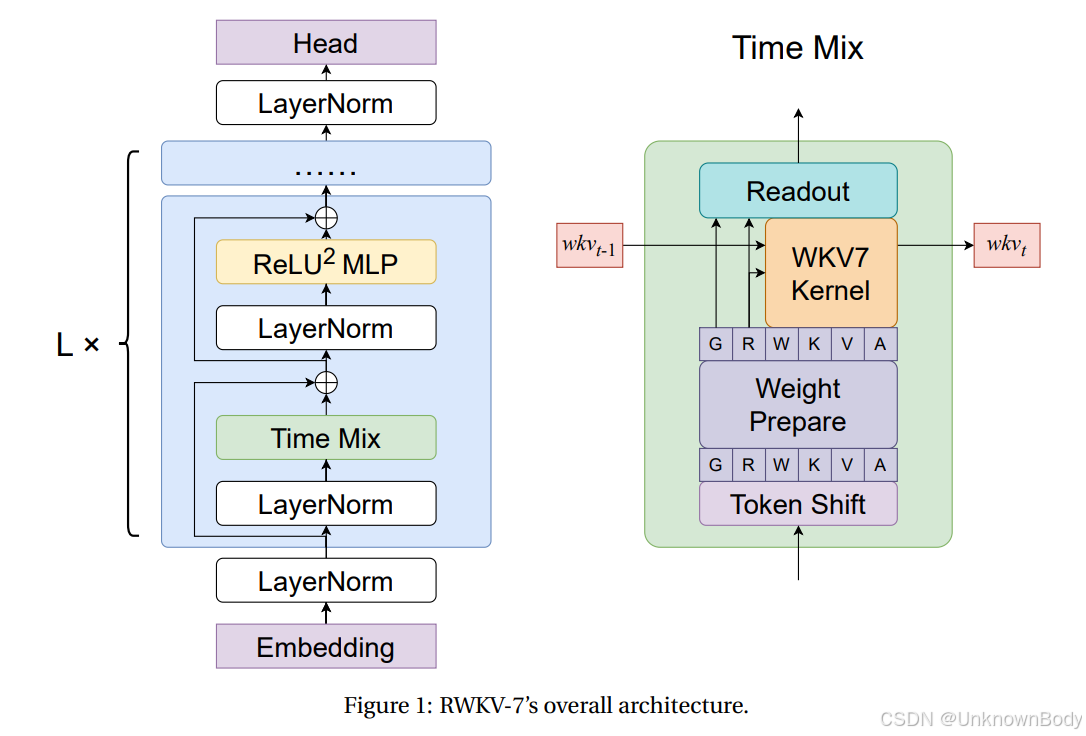
主要内容与创新点
核心架构
- 动态状态演化:通过推广增量规则(delta rule),引入向量值门控和上下文学习率,实现了更灵活的状态更新机制。
- 常数复杂度:保持线性时间和常数内存复杂度,适用于长序列任务。
- 并行训练:支持高效的并行化训练,同时通过状态压缩提升推理效率。
关键创新点
- 广义增量规则:提出新的状态更新公式,允许向量值衰减和上下文学习率,增强模型表达能力。
- 状态跟踪能力:理论证明RWKV-7可识别所有正则语言,超越Transformer的TC⁰限制。
- 多语言性能:在3B参数规模下实现多语言任务SOTA,且训练数据量显著少于同类模型。
- 开放资源:发布3.1万亿token的多语言数据集RWKV World v3,以及4个不同参数规模的预训练模型。
实验结果
- 语言建模:在LAMBADA、MMLU

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 1573
1573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











