 PRESELECT:语言模型预训练数据选择新方法
PRESELECT:语言模型预训练数据选择新方法








 超级会员免费看
超级会员免费看
摘要
语言模型预训练需要在海量语料库上进行训练,数据质量在其中起着关键作用。在这项工作中,我们旨在直接评估数据在预训练过程中的贡献,并高效地选择预训练数据。具体来说,我们从最近的研究中获得启发,当文本领域与下游基准测试对齐时,不同模型在特定文本上的压缩效率(即归一化损失)与它们的下游性能密切相关(Huang等人,2024)。基于这一观察,我们假设那些模型损失能够预测下游能力的数据,也能有效地促进模型学习。为了利用这一见解,我们提出了预测性数据选择方法(PRESELECT),这是一种轻量级且高效的数据选择方法,仅需训练和部署一个基于fastText的评分器。通过对1B和3B参数模型的全面实验,我们发现使用PRESELECT选择的30B tokens训练的模型性能超过了使用300B tokens的随机基线模型,计算需求降低了10倍。此外,在3B模型使用100B tokens的情况下,PRESELECT显著优于其他竞争基线,如DCLM和FineWebEdu。我们开源了训练好的数据选择评分器以及精选的数据集,地址为https://github.com/hkust-nlp/PreSelect。
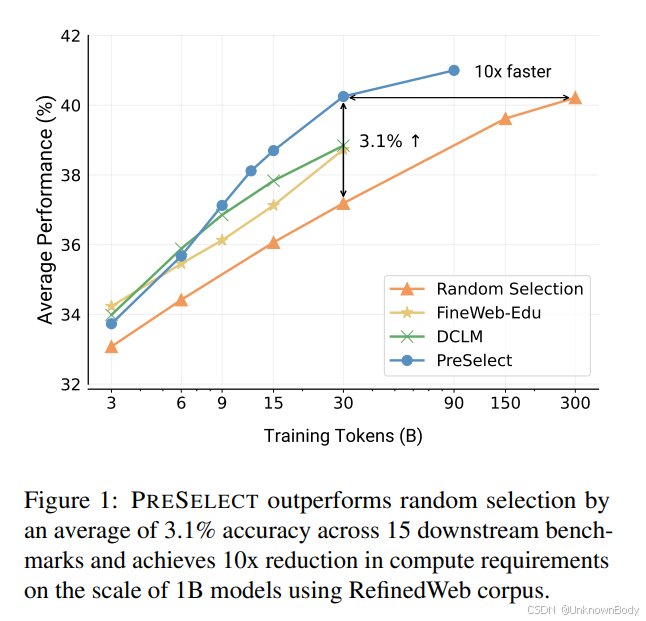
引言
大型语言模型(LLM)的预训练通常需要在如网络爬取数据等海量数据源上进行,而低质量数据的存在会导致缩放定律的缓慢(Kaplan等人,2020;Chowdhery等

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 1251
1251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











