




Tracking?
Tracking,仅从字面上就有追踪、跟踪之意。在实际应用当中,埋点是为了满足能够跟踪并记录用户行为过程与结果而产生的技术方法。
1、 埋点数据的流水线
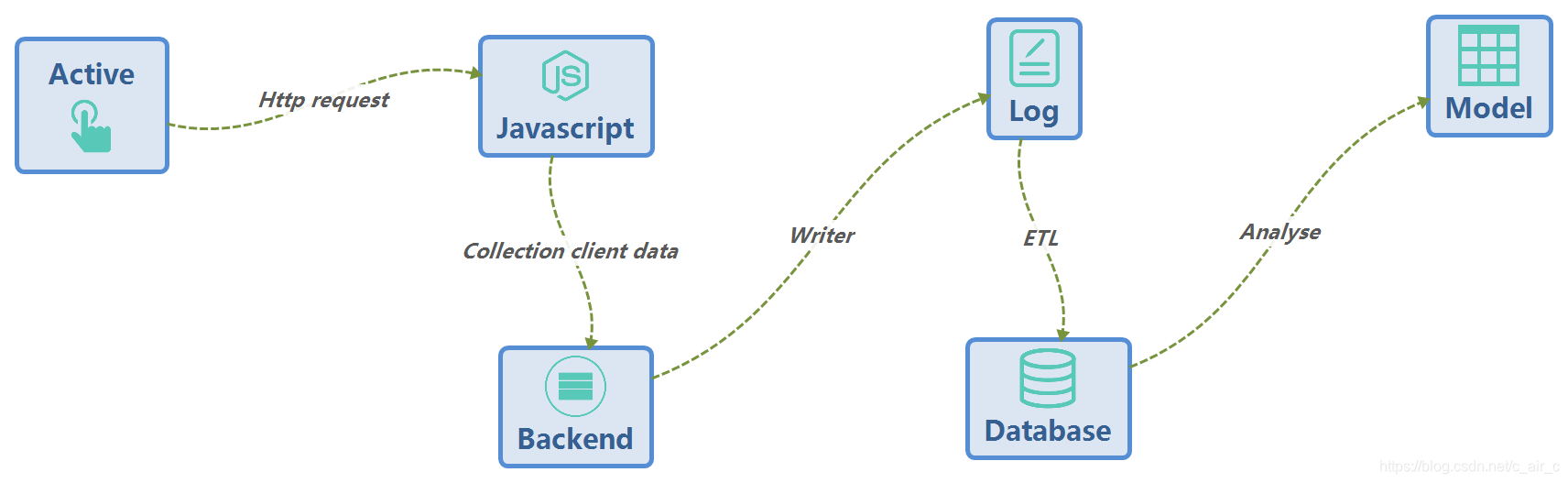
当用户在客户端发生交互(Active)时,会运行相应的请求指令,向服务器发出 Http request。其中运行的代码当中,我们就会隐式的载入埋点代码,通常为.js,这也是数据搜集的源头和最为关键的一步。通过.js代码我们搜集客户端的数据,并发送到我们的后端(Backend),写入日志(Log)当中。这时数据的搜集工作基本完成,如果想要进一步支持业务,那么ETL工程师就要发挥更大的作用。通过对原始日志的抽取(Extract)、转换(Transform)、加载(Load)工作写入数据库(Database)当中。当业务需要数据支持时,按照业务逻辑取出,并稍加处理就可交付给业务人员。这就是数据在用户>>收集>>存储>>业务生产线的生命过程。
2、埋点的设计原则
埋点设计和系统设计在一定程度上非常相似。在满足不同的业务需求的同时,易于管理和使用也非常重要。保证埋点的业务性 、复用性、一致性、只增不减性具有重要意义。
2.1 业务性
埋点,说到底就是为了支持业务而生。若仅仅是为了获取数据去做埋点,这将没有丝毫价值。这就要求,在设计埋点时,应该事先与需求方沟通业务逻辑与业务需求,使得获取数据能够满足逻辑的同时,更好的支持业务。这里的需求方,不仅仅包括需要优化产品的产品部门,需要内容排期推荐的内容部门,还包括渠道部门和用户部门等。举个栗子,对于一款阅读型产品的点赞功能,产品经理会更关心让用户使用点赞的体验,内容部门就会在意于哪一款内容更容易让用户点赞。这就要求在做埋点时,规划好数据收集的颗粒度,使得收集的数据即不冗余,也不会数到用时方恨少。
2.2 复用性
复用性,主要表现在,应用的功能调用在一定程度上是重复出现的,区别仅在于用户场景上的不一致。举个栗子,在未登录的状态下,使用bilibili内容下的转发、评论、点赞、关注功能时,均会触发登录事件。这时需要获取的事件属性,比如,content_id、up_id…基本一致,只需要添加一个origin来区分用户场景就能够满足需要。这将会给后期的BI建设提供很大的便利,业务上也足够清晰,埋点文档的维护也较为容易。
2.3 一致性
一致性,常出现在命名的问题上。一方面,在于Android、IOS、Quick App、H5小程序多平台开发,带来UI上的设计差异,文案差异,导致前端显示不一致;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 969
969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









