







 本文探讨了概率PCA和变分自编码器(VAE)这两种降维方法,指出PCA是线性降维的基础,而自编码器则通过非线性变换实现降维。概率PCA提供了PCA的生成模型视角,适用于需要生成新样本的场景。变分自编码器则是非线性降维的生成式方法,通过变分推断解决优化问题。对比中强调了线性与非线性、生成式与非生成式方法的区别,并分析了它们在降维、重建和新样本生成中的应用。
本文探讨了概率PCA和变分自编码器(VAE)这两种降维方法,指出PCA是线性降维的基础,而自编码器则通过非线性变换实现降维。概率PCA提供了PCA的生成模型视角,适用于需要生成新样本的场景。变分自编码器则是非线性降维的生成式方法,通过变分推断解决优化问题。对比中强调了线性与非线性、生成式与非生成式方法的区别,并分析了它们在降维、重建和新样本生成中的应用。

作者丨知乎DeAlVe
学校丨某211硕士生
研究方向丨模式识别与机器学习
介绍
主成分分析(PCA)和自编码器(AutoEncoders, AE)是无监督学习中的两种代表性方法。
PCA 的地位不必多说,只要是讲到降维的书,一定会把 PCA 放到最前面,它与 LDA 同为机器学习中最基础的线性降维算法,SVM/Logistic Regression、PCA/LDA 也是最常被拿来作比较的两组算法。
自编码器虽然不像 PCA 那般在教科书上随处可见,但是在早期被拿来做深度网络的逐层预训练,其地位可见一斑。尽管在 ReLU、Dropout 等神器出现之后,人们不再使用 AutoEncoders 来预训练,但它延伸出的稀疏 AutoEncoders,降噪 AutoEncoders 等仍然被广泛用于表示学习。2017 年 Kaggle 比赛 Porto Seguro’s Safe Driver Prediction 的冠军就是使用了降噪 AutoEncoders 来做表示学习,最终以绝对优势击败了手工特征工程的选手们。
PCA 和 AutoEncoders 都是非概率的方法,它们分别有一种对应的概率形式叫做概率 PCA (Probabilistic PCA) 和变分自编码器(Variational AE, VAE),本文的主要目的就是整理一下 PCA、概率 PCA、AutoEncoders、变分 AutoEncoders 这四者的关系。
先放结论,后面就围绕这个表格展开:
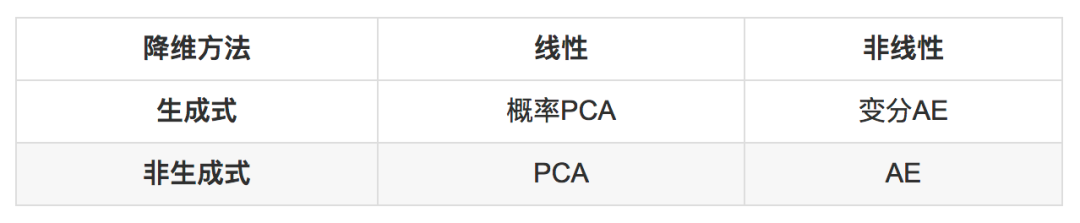
降维的线性方法和非线性方法
降维分为线性降维和非线性降维,这是最普遍的分类方法。
PCA 和 LDA 是最常见的线性降维方法,它们按照某种准则为数据集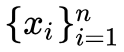 找到一个最优投影方向 W 和截距 b,然后做变换
找到一个最优投影方向 W 和截距 b,然后做变换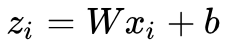 得到降维后的数据集
得到降维后的数据集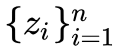 。因为是一个线性变换(严格来说叫仿射变换,因为有截距项),所以这两种方法叫做线性降维。
。因为是一个线性变换(严格来说叫仿射变换,因为有截距项),所以这两种方法叫做线性降维。
非线性降维的两类代表方法是流形降维和 AutoEncoders,这两类方法也体现出了两种不同角度的“非线性”。流形方法的非线性体现在它认为数据分布在一个低维流形上,而流形本身就是非线性的,流形降维的代表方法是两篇 2000 年的 Science 论文提出的:多维放缩(multidimensional scaling, MDS)和局部线性嵌入(locally linear embedding, LLE)。不得不说实在太巧了,两种流形方法发表在同一年的 Science 上。
AutoEncoders 的非线性和神经网络的非线性是一回事,都是利用堆叠非线性激活函数来近似任意函数。事实上,AutoEncoders 就是一种神经网络,只不过它的输入和输出相同,真正有意义的地方不在于网络的输出,而是在于网络的权重。
降维的生成式方法和非生成式方法
两类方法
降维还可以分为生成式方法(概率方法)接非生成式方法(非概率方法)。
教科书对 PCA 的推导一般是基于最小化重建误差或者最大化可分性的,或者说是通过提取数据集的结构信息来建模一个约束最优化问题来推导的。事实上,PCA 还有一种概率形式的推导,那就是概率 PCA,PRML 里面有对概率 PCA 的详细讲解,感兴趣的读者可以去阅读。需要注意的是,概率 PCA 不是 PCA 的变体,它就是 PCA 本身,概率 PCA 是从另一种角度来推导和理解 PCA,它把 PCA 纳入了生成式的框架。
设是我们拿到的数据集,我们的目的是得到数据集中每个样本的低维表示,其中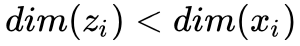 。
。
降维的非生成式方法不需要概率知识,而是直接利用数据集的结构信息建模一个最优化问题,然后求解这个问题得到对应的。
降维的生成式方法认为数据集是对一个随机变量 x 的 n 次采样,而随机变量 x 依赖于随机变量 z ,对 z 进行建模:
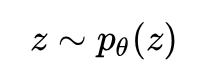
再对这个依赖关系进行建模:
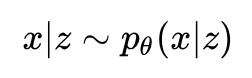
有了这两个公式,我们就可以表达出随机变量 x 的分布:
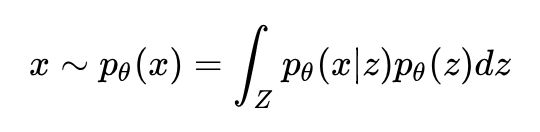
随后我们利用数据集对分布的参数 θ 进行估计,就得到这几个分布。好了,设定了这么多,可是降维降在哪里了呢,为什么没有看到?
回想一下降维的定义:降维就是给定一个高维样本 xi ,给出对应的低维表示 zi ,这恰好就是 p(z|x) 的含义。所以我们只要应用 Bayes 定理求出这个概率即可:
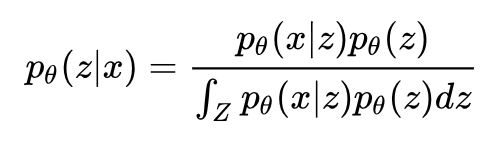
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 23
23

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









