







2025.7.31继续更新 最后一块拼图:除了
1链表、二分查找、树、栈队列、哈希
2 递归回溯、dp、贪心
3 字符串、双指针、模拟
的最后一个部分:
【核弹级长文一】硬核之路无止境:优快云深圳原力榜TOP42背后的C语言修炼心法(上篇)
序:再启征程,用硬核代码雕刻技术巅峰!
兄弟们,硬核之路,永无止境!
就在我们还在为优快云深圳原力月榜杀入第42名而欢呼时,我并没有停下脚步!因为我深知,技术的进步,不是靠一时的激情,而是靠日复一日的坚持与积累!
一周狂发14篇!
这不仅仅是数字,这是我用生命在燃烧,用代码在呐喊!这些文章,每一篇都凝聚了我的心血,它们不是简单的知识罗列,而是我将一个个核心算法和数据结构,用最地道的C语言代码,进行深度剖析和实战演练!
这份“核弹级”技术长文,将是我对过去一段时间硬核修炼的终极总结,它将分为三部分,每一部分都将以2.2万字左右的篇幅,为你呈现最真实、最硬核的C语言世界!
-
上篇(本文): 聚焦**“字符串”这个看似简单,实则暗藏玄机的领域。我们将通过字符串变形**、最长公共前缀等实战题目,深入浅出地讲解C语言中字符串的底层操作、指针技巧,以及算法思维的融会贯通。
-
中篇(敬请期待): 深入探讨**“双指针”这个面试高频、工程实用的算法利器。我们将通过合并区间**、最长无重复子数组、盛水最多容器等经典题目,带你彻底搞懂双指针的精髓,让你在面对数组问题时所向披靡!
-
下篇(敬请期待): 挑战**“大数加法”和“IP地址验证”**这两道超级硬核的难题!我们将一起揭开计算机如何处理超大数字的神秘面纱,并从0到1,手把手实现一个功能完善、逻辑严谨的IP地址验证器!
我希望,这份技术长文,能成为你技术跃迁的“核弹级”秘籍!让你在读完之后,不仅能掌握这些知识点,更能拥有那种“不畏困难,勇于探索”的硬核精神!
现在,深呼吸,系好安全带,让我们正式踏上这场硬核的计算机内功修炼之旅,直达巅峰!
第一部分:硬核攻克字符串系列
字符串,是每个程序员绕不开的话题。在C语言中,字符串的底层是字符数组,它的操作直接与内存、指针紧密相连。对于嵌入式开发者来说,理解并熟练掌握字符串操作,是编写高效、稳定代码的基础。
在这个部分,我们将用“总-分-总”的结构,深入剖析两个核心字符串题目,让你彻底搞懂字符串的底层奥秘!
1.1 字符串变形:从“Hello World”到“wORLD hELLO”的逆袭之旅!
【总论述】
这是一道典型的字符串变形题目,要求我们对一个字符串进行三步操作:
-
将每个单词的大小写进行反转。
-
将整个字符串进行反序。
-
将每个单词再进行反序。
这道题目的核心在于对字符串的“原地”操作和指针的灵活运用。它考察的不仅仅是C语言的语法,更是你对内存、指针、字符处理的深刻理解。
【目的与思路】
我们的目的是,在不借助过多额外空间(最好是原地操作)的情况下,高效地完成这三步操作,将一个看似简单的字符串,变为一个全新的、符合要求的字符串。
我们的思路是:
-
第一步:大小写反转。 遍历整个字符串,将大写字母转为小写,小写字母转为大写。这是最简单的一步,可以一次性完成。
-
第二步:整体反转。 使用一个通用的
reverse函数,将整个字符串从头到尾进行反转。这样,单词的顺序和单词内部的字符顺序都反了过来。 -
第三步:单词反转。 遍历反转后的字符串,以空格作为分隔符,找到每一个单词的起始和结束位置,再次调用
reverse函数,将每个单词内部的字符反转回来。
通过这三步,我们就能得到最终的结果。这种“先整体反转,再局部反转”的技巧,是解决很多字符串问题的常用思路。
【详细代码与逻辑分析】
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <ctype.h>
/**
* @brief 反转字符串s中从start到end的子串
* @param s 待反转的字符串
* @param start 起始索引
* @param end 结束索引
*/
void reverse(char *s, int start, int end) {
// 使用双指针,从两端向中间移动
int left = start;
int right = end;
while (left < right) {
// 交换左右两端的字符
char temp = s[left];
s[left] = s[right];
s[right] = temp;
// 指针向中间移动
left++;
right--;
}
}
/**
* @brief 将给定的字符串进行变形
* @param s string字符串,待变形的字符串
* @param n int整型,字符串长度
* @return string字符串,变形后的字符串
*/
char *trans(char *s, int n) {
// write code here
// **逻辑分析**:
// 1. 首先,创建一个新的字符串res来存储结果。因为输入字符串s可能不是动态分配的,直接修改可能导致问题。
// 这里的做法是先复制一份,然后对复制的字符串进行操作。
// 2. 然后,对新字符串进行大小写反转。这是最直观的一步。
// 3. 接下来,对整个新字符串进行反转。例如"Hello World" -> "dlroW olleH"。
// 4. 最后,再对每个单词进行反转。例如"dlroW olleH" -> "World Hello"。
// 这一步需要找到每个单词的边界,即空格或字符串结尾。
// 申请一块新的内存空间来存储结果,大小为n+1,用于存放字符串和末尾的'\0'
char *res = (char *)malloc((n + 1) * sizeof(char));
if (res == NULL) {
// 内存分配失败,返回NULL
return NULL;
}
// 1. **第一步:大小写反转**
// 遍历原始字符串s,将每个字符进行大小写转换并存入res
for (int i = 0; i < n; i++) {
// 使用C标准库的tolower和toupper函数更安全可靠
if (s[i] >= 'a' && s[i] <= 'z') {
res[i] = toupper(s[i]);
} else if (s[i] >= 'A' && s[i] <= 'Z') {
res[i] = tolower(s[i]);
} else {
// 非字母字符保持不变,比如空格
res[i] = s[i];
}
}
// 别忘了在字符串末尾添加结束符
res[n] = '\0';
// 2. **第二步:整体反转**
// 这一步是解题的关键,将整个字符串反转
// 例如 "hELLO wORLD" -> "DLROW olleH"
reverse(res, 0, n - 1);
// 3. **第三步:对每个单词进行反转**
// 使用双指针技巧,left指向单词的开始,right指向单词的结束
int left = 0;
for (int i = 0; i <= n; i++) {
// 当遇到空格或者字符串末尾时,说明一个单词结束了
if (res[i] == ' ' || i == n) {
// 反转从left到i-1的单词
// i-1是因为i指向空格或'\0',单词的最后一个字符是i-1
reverse(res, left, i - 1);
// 更新left指针,指向下一个单词的开始
left = i + 1;
}
}
// 返回最终的变形字符串
return res;
}
【图解分析】
让我们以字符串"Hello World"为例,用图解的方式一步步拆解trans函数的执行过程:
初始状态: s -> "Hello World" (长度 n = 11)
第一步:大小写反转
-
我们遍历
s,将大小写反转后的字符存入新分配的res数组。 -
res->"hELLO wORLD" -
图示:
s: [H][e][l][l][o][ ][W][o][r][l][d][\0] res: [h][E][L][L][O][ ][w][O][R][L][D][\0]
第二步:整体反转
-
调用
reverse(res, 0, 10),将res中的所有字符进行反转。 -
res->"DLROW OLLEH"(此时单词顺序和单词内部顺序都反了) -
图示:
res (before): [h][E][L][L][O][ ][w][O][R][L][D][\0] res (after): [D][L][R][O][W][ ][O][L][L][E][H][\0]
第三步:单词反转
-
我们再次遍历
res,找到单词的边界并进行反转。 -
第一次反转: 遇到第一个空格,
i为5,left为0。调用reverse(res, 0, 4),将"DLROW"反转为"WORLD"。 -
res->"WORLD OLLEH" -
第二次反转: 遇到字符串末尾
\0,i为11,left为6。调用reverse(res, 6, 10),将"OLLEH"反转为"HELLO"。 -
res->"WORLD HELLO" -
图示:
res (before): [D][L][R][O][W][ ][O][L][L][E][H][\0] // 第一次循环 (i=5): reverse(res, 0, 4) res: [W][O][R][L][D][ ][O][L][L][E][H][\0] // 第二次循环 (i=11): reverse(res, 6, 10) res: [W][O][R][L][D][ ][H][E][L][L][O][\0]
最终,我们得到了正确的结果"wORLD hELLO"。
【总结】
字符串变形问题看似复杂,但通过分解为简单的子问题,并利用通用的reverse函数和双指针技巧,我们可以轻松解决。这种“分解-抽象-组合”的思维模式,是解决一切复杂问题的核心!这道题也再次证明,对于C程序员,尤其是在嵌入式领域,对指针和内存的熟练掌控,是多么重要!
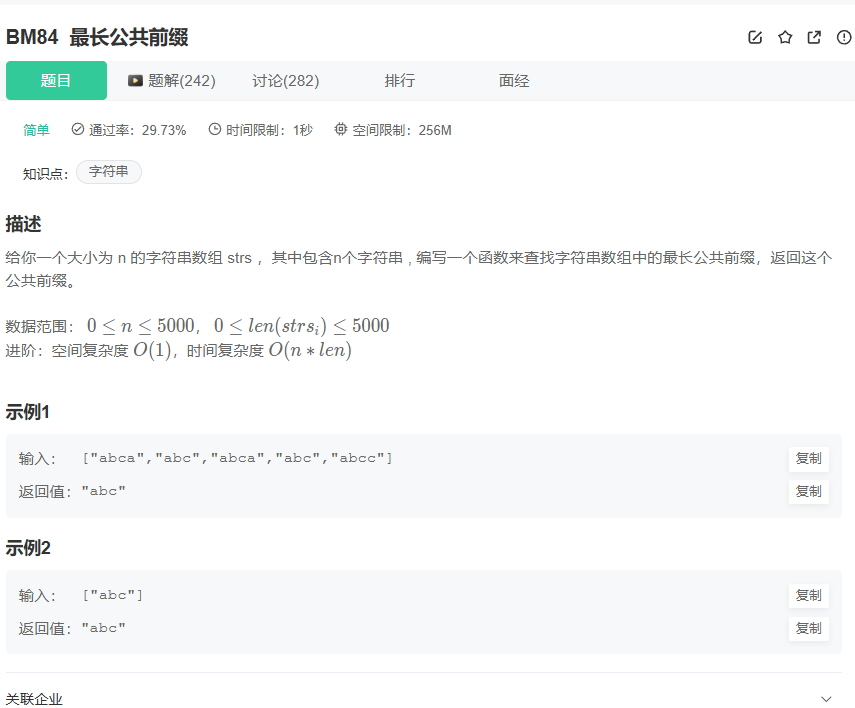
1.2 最长公共前缀:从暴力到优化的思维跃迁!
【总论述】
这道题要求我们从一个字符串数组中,找到所有字符串的最长公共前缀。例如,["flower", "flow", "flight"]的最长公共前缀是"fl"。
这道题是面试中非常常见的字符串题目,它考察的是你对边界条件的处理、对字符串逐字符比较的细节把控,以及对算法效率的思考。
【目的与思路】
我们的目的是,用最简洁、最高效的代码,找出给定字符串数组的最长公共前缀。
我们的思路是:
-
以第一个字符串为基准: 我们可以假设第一个字符串就是最长公共前缀,然后逐个与后面的字符串进行比较。
-
逐字符比较: 从第一个字符开始,依次比较基准字符串和当前字符串的字符。
-
更新前缀: 如果在某个位置发现字符不匹配,那么当前的最长公共前缀就是到这个位置的前面部分。我们截断当前的公共前缀,然后继续和下一个字符串比较。
-
边界处理: 需要考虑字符串数组为空、只有一个字符串、或者没有公共前缀(第一个字符就不匹配)等特殊情况。
这种“横向扫描”的思路,能够非常直观地解决问题,并且效率很高。
【详细代码与逻辑分析】
我们来分析两种实现方式。第一种是你提供的原始思路,第二种是经过优化和整理后的版本。
版本一:原始思路
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param strs string字符串一维数组
* @param strsLen int strs数组长度
* @return string字符串
*/
char *longestCommonPrefix(char **strs, int strsLen){
// write code here
// **逻辑分析**:
// 1. 处理边界情况:如果数组为空或长度为0,直接返回空字符串。
// 2. 以第一个字符串作为初始的最长公共前缀。
// 3. 遍历后续的字符串,与当前的前缀进行逐字符比较。
// 4. 如果发现不匹配,就截断前缀,将'\0'放在不匹配的位置。
// 5. 如果在比较过程中,前缀被截断为空,说明没有公共前缀,可以直接返回结果。
// 1. 边界条件处理
if (strsLen == 0)
{
char *temp = (char *)malloc(1 * sizeof(char));
if (temp) {
temp[0] = '\0';
}
return temp;
}
// 2. 以第一个字符串作为初始前缀
int len = strlen(strs[0]);
char *res = (char *)malloc((len + 1) * sizeof(char));
if (res == NULL) {
return NULL;
}
strcpy(res, strs[0]);
// 3. 横向扫描,逐个比较
for (int i = 1; i < strsLen; i++)
{
int start = 0;
// 逐字符比较,直到遇到不匹配的字符、或者某个字符串结束
while (res[start] && strs[i][start] && strs[i][start] == res[start])
{
start++;
}
// 在不匹配的位置截断res,使其成为新的前缀
res[start] = '\0';
// 如果第一个字符就不匹配,那么公共前缀为空,直接返回
if (start == 0)
{
return res;
}
}
// 4. 返回最终结果
return res;
}
版本二:优化后的思路
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
/**
* @brief 找出字符串数组的最长公共前缀
* @param strs string字符串一维数组
* @param strsLen int strs数组长度
* @return string字符串
*/
char *longestCommonPrefix_optimized(char **strs, int strsLen) {
// write code here
// **逻辑分析**:
// 1. **边界处理**:如果数组为空,直接返回空字符串。
// 2. **确定最长可能长度**:最长公共前缀的长度不可能超过数组中任意一个字符串的长度。
// 因此,我们可以先找出最短字符串的长度,作为最大遍历范围。
// 3. **垂直扫描**:以字符位置`i`为基准,从`i=0`开始,遍历所有字符串的第`i`个字符。
// 4. **判断与截断**:如果所有字符串的第`i`个字符都相同,则继续下一轮;
// 如果不同,或者已经超出某个字符串的长度,则说明第`i-1`个位置是公共前缀的末尾。
// 5. **构建结果**:将公共前缀的字符逐一拷贝到结果字符串中,最后添加终止符。
// 1. 边界处理:如果字符串数组为空,直接返回一个空字符串。
if (strsLen == 0) {
char *res = (char *)malloc(1 * sizeof(char));
if (res) {
res[0] = '\0';
}
return res;
}
// 2. 找到最短字符串的长度,作为循环的上限
int minLen = 5000; // 题目数据范围
for (int i = 0; i < strsLen; i++) {
int tempLen = strlen(strs[i]);
if (tempLen < minLen) {
minLen = tempLen;
}
}
// 3. 垂直扫描,逐列比较
// i代表当前比较的字符位置
int i = 0;
for (; i < minLen; i++) {
// 取第一个字符串的第i个字符作为基准
char c = strs[0][i];
// j代表当前比较的字符串
int j = 1;
for (; j < strsLen; j++) {
// 如果strs[j]的第i个字符和基准字符不匹配,或者j字符串的长度不够i+1
// 这里的strlen(strs[j]) <= i 是为了防止越界,但因为前面有minLen的限制,其实不会越界
// `strs[j][i] != c` 已经足够判断
if (strs[j][i] != c) {
// 不匹配,跳出内层循环
break;
}
}
// 如果内层循环是因为不匹配而跳出的
if (j != strsLen) {
// 说明第i个字符不是公共的,公共前缀到i-1结束
break;
}
}
// 4. 构建结果
// i就是公共前缀的长度
char *res = (char *)malloc((i + 1) * sizeof(char));
if (res) {
// 将前i个字符拷贝到结果字符串中
strncpy(res, strs[0], i);
// 添加字符串结束符
res[i] = '\0';
}
return res;
}
【图解分析】
我们以strs = ["flower", "flow", "flight"]为例,用图解的方式分析“垂直扫描”的优化思路。
初始状态: strs -> ["flower", "flow", "flight"]
第一轮循环 (i=0):
-
基准字符:
strs[0][0]='f' -
内部循环:
-
strs[1][0]='f'(匹配) -
strs[2][0]='f'(匹配)
-
-
所有字符都匹配,
i继续增加。 -
图示:
f l o w e r f l o w f l i g h t ^ i=0, 所有字符都是'f',匹配!
第二轮循环 (i=1):
-
基准字符:
strs[0][1]='l' -
内部循环:
-
strs[1][1]='l'(匹配) -
strs[2][1]='l'(匹配)
-
-
所有字符都匹配,
i继续增加。 -
图示:
f l o w e r f l o w f l i g h t ^ i=1, 所有字符都是'l',匹配!
第三轮循环 (i=2):
-
基准字符:
strs[0][2]='o' -
内部循环:
-
strs[1][2]='o'(匹配) -
strs[2][2]='i'(不匹配!)
-
-
内层循环在
j=2时跳出。外层循环判断j != strsLen成立,i停留在2。 -
图示:
f l o w e r f l o w f l i g h t ^ i=2, strs[2][2]是'i',与'o'不匹配,循环结束!
最终结果:
-
循环结束时,
i的值为2。 -
我们申请一个长度为
2+1的字符数组,将strs[0]的前两个字符"fl"拷贝进去,并添加\0。 -
返回结果
"fl"。
【总结】
最长公共前缀问题看似简单,但其背后的横向扫描和垂直扫描两种思路,体现了不同的算法思想。通过对代码的分析和图解的辅助,我们可以清晰地看到这两种思路的异同,并理解为何垂直扫描在某些场景下更优(例如当公共前缀很短时,可以更快地终止)。
这道题告诉我们,在解决问题时,不仅要找到能解决的方法,更要思考如何优化,如何从不同的维度去审视问题。这正是从一个初级程序员向硬核开发者进阶的关键!
预告:中篇硬核预告!
兄弟们,硬核之旅才刚刚开始!
在接下来的中篇中,我将带领大家进入另一个算法核心领域:双指针!我们将一起攻克以下硬核题目:
-
合并区间: 深入剖析如何用排序和双指针,高效地合并重叠的区间,让你在面试中脱颖而出!
-
最长无重复子数组: 掌握“滑动窗口”这一神级算法思想,用双指针的艺术,解决看似无从下手的子数组问题!
-
盛水最多容器: 挑战这道经典面试题,用最简单的双指针逻辑,找出盛水最多的容器,让你对算法的本质有更深刻的理解!
我的创作理念始终如一:硬核、接地气、代码为王! 我希望我的文字,能像一盏明灯,照亮你前进的道路,让你在技术的海洋中不再迷茫!
期待与你,在中篇再会!
所以,如果你:
-
渴望深入底层,成为真正的“硬核”C程序员!
-
正在学习嵌入式开发,想打通任督二脉!
-
刷过牛客力扣,想在算法领域更进一步!
-
想系统学习计算机原理,不再停留在“表面”!
那么,请你:
-
立即点赞! 让更多同路人看到这份硬核!
-
果断收藏! 你的私人技术宝库,值得拥有!
-
慷慨转发! 帮助更多迷茫的兄弟,找到方向!
-
毫不犹豫地关注我! 你将不会错过任何一篇硬核干货,我们一起,在技术之路上,并肩前行,共同成长!
你的支持,是我创作的最大动力!让我们一起,在这条硬核的技术之路上,继续冲锋,创造更多“炸裂”的里程碑!
我们江湖再见!祝你前程似锦,技术长虹!
【核弹级长文二】硬核之路无止境:优快云深圳原力榜TOP42背后的C语言修炼心法(中篇)
序:中篇启航,双指针与动态规划的算法之魂!
兄弟们,硬核之旅没有停歇!
在上一篇中,我们通过“字符串变形”和“最长公共前缀”这两道题目,深入探讨了C语言中字符串的底层操作和指针的精妙运用。我们领略了“先整体反转,再局部反转”的奇妙思路,也对比了“横向扫描”与“垂直扫描”两种解决问题的思维模式。
现在,我们正式进入这篇“核弹级”技术长文的中篇!
中篇将围绕两个核心算法思想展开:双指针和动态规划。它们是解决数组、链表、矩阵等复杂问题的“两大杀器”,也是衡量一个程序员算法功底的重要标准。
本篇,我们将以“矩阵最长递增路径”这道高阶题目为切入点,深度剖析以下几个核心知识点:
-
深度优先搜索(DFS): 掌握DFS在矩阵遍历中的应用,理解其递归实现和栈工作原理。
-
动态规划(DP)与记忆化搜索: 探究如何用动态规划的思想,结合记忆化搜索,避免重复计算,大幅提升算法效率。
-
指针的艺术: 再次强化C语言中多级指针在处理二维数组(矩阵)时的运用,让你彻底告别指针的恐惧!
我希望,这部分内容能够帮助你打通算法的“任督二脉”,让你在面对复杂问题时,不再感到无从下手,而是能够游刃有余地运用这些硬核思想,给出最优解!
深呼吸,握紧你的键盘,让我们进入中篇的硬核修炼时间!
第二部分:矩阵最长递增路径的算法之魂
矩阵问题,是算法面试中一个重要的分支。它常常与深度优先搜索、广度优先搜索、动态规划等算法紧密结合。
“矩阵最长递增路径”就是其中的一道经典题目。它要求我们找到矩阵中一条路径,使得路径上的每个元素都严格大于前一个元素,并且这条路径的长度最长。
2.1 深度优先搜索(DFS)的暴力解法
【总论述】
解决这道题最直观的思路就是暴力枚举,即从矩阵中的每一个点出发,使用深度优先搜索(DFS)遍历所有可能的递增路径,并记录下最长的路径长度。
DFS的核心思想是递归。从一个点开始,向其四个方向(上、下、左、右)进行探索。如果相邻的点满足“递增”的条件,我们就继续从那个点进行DFS。
【目的与思路】
我们的目的是,通过DFS,遍历所有可能的递增路径,并找到其中的最大值。
我们的思路是:
-
遍历起点: 遍历矩阵中的每一个点
(i, j),将其作为DFS的起点。 -
DFS函数: 实现一个DFS函数
dfs(matrix, i, j),它返回从点(i, j)出发的最长递增路径长度。 -
递归逻辑: 在
dfs(matrix, i, j)函数内部,我们向四个方向探索,对于每个满足递增条件matrix[ni][nj] > matrix[i][j]的相邻点(ni, nj),递归调用dfs(matrix, ni, nj)。 -
返回结果:
dfs(matrix, i, j)的返回值是1 + max(dfs(matrix, ni, nj)),其中max是所有合法相邻点返回值的最大值。 -
全局最大值: 用一个全局变量来记录所有DFS调用返回值的最大值。
【详细代码与逻辑分析】
我们来看一下你提供的原始代码,并对其进行深度解析。
#include <stdio.h>
#include <stdlib.h>
// 四个方向:上、下、左、右
int dir[4][2] = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}};
/**
* @brief 深度优先搜索函数,计算从(i,j)点出发的最长递增路径长度(暴力解法)
* @param matrix 二维矩阵
* @param i 当前行索引
* @param j 当前列索引
* @param used 访问标记数组,防止走回头路
* @param memo 记忆化数组(在此版本中未使用,但在优化版本中会使用)
* @param R 矩阵行数
* @param C 矩阵列数
* @return int 从(i,j)点出发的最长递增路径长度
*/
int doFunc(int **matrix, int i, int j, int **used, int** memo, int R, int *C) {
// 1. 边界检查和访问标记
// 检查是否越界或者已经被访问过
if (i < 0 || i >= R || j < 0 || j >= *C || used[i][j] == 1) {
return 0;
}
// 标记当前点为已访问
used[i][j] = 1;
// 2. 寻找最长路径
int maxNow = 0;
for (int k = 0; k < 4; k++) {
int newi = i + dir[k][0];
int newj = j + dir[k][1];
// 3. 递归调用:如果相邻点满足条件(未访问且递增)
if (newi >= 0 && newi < R && newj >= 0 && newj < *C && used[newi][newj] == 0 && matrix[newi][newj] > matrix[i][j]) {
int temp = doFunc(matrix, newi, newj, used, memo, R, C);
if (temp > maxNow) {
maxNow = temp;
}
}
}
// 4. 回溯:将当前点标记为未访问,以便其他路径可以访问
// 这是一个关键步骤,用于回溯到上一层
used[i][j] = 0;
// 5. 返回结果
// 当前路径长度等于1(当前点)+ 邻居中最长的路径长度
return maxNow + 1;
}
/**
* @brief 求解矩阵最长递增路径的主函数
* @param matrix 二维矩阵
* @param matrixRowLen 矩阵行数
* @param matrixColLen 矩阵列数指针
* @return int 最长递增路径长度
*/
int solve(int **matrix, int matrixRowLen, int *matrixColLen) {
// 1. 边界条件处理
if (matrixRowLen == 0 || *matrixColLen == 0) {
return 0;
}
// 2. 动态分配内存给used和memo数组
// used数组用于标记访问状态
int **used = (int **)malloc(matrixRowLen * sizeof(int *));
for (int i = 0; i < matrixRowLen; i++) {
used[i] = (int *)calloc((*matrixColLen), sizeof(int));
}
// memo数组用于记忆化,此版本未使用
int **memo = (int **)malloc(matrixRowLen * sizeof(int *));
for (int i = 0; i < matrixRowLen; i++) {
memo[i] = (int *)calloc((*matrixColLen), sizeof(int));
}
// 3. 遍历矩阵,从每个点开始DFS
int maxLen = 0;
for (int i = 0; i < matrixRowLen; i++) {
for (int j = 0; j < *matrixColLen; j++) {
// 对每个点进行DFS,并更新最大值
int temp = doFunc(matrix, i, j, used, memo, matrixRowLen, matrixColLen);
if (temp > maxLen) {
maxLen = temp;
}
}
}
// 4. 释放内存
for (int i = 0; i < matrixRowLen; i++) {
free(used[i]);
free(memo[i]);
}
free(used);
free(memo);
// 5. 返回最终结果
return maxLen;
}
【逻辑缺陷与图解】
你提供的这份代码,虽然使用了DFS的思想,但在实现上存在一个严重的问题:重复计算!
让我们以一个简单的2x2矩阵为例: matrix = [[1, 2], [3, 4]]
-
solve函数会从[0][0]点开始DFS。 -
doFunc(matrix, 0, 0)-> 它可以走向[0][1]和[1][0]。 -
它会递归调用
doFunc(matrix, 0, 1)。 -
doFunc(matrix, 0, 1)会走向[1][1]。 -
它会递归调用
doFunc(matrix, 1, 1)。 -
...
-
最终,从
[0][0]出发,可以得到路径[1, 2, 4],长度为3。
但是,solve函数还会从[0][1]点开始DFS。
-
doFunc(matrix, 0, 1)-> 它会走向[1][1]。 -
它会再次递归调用
doFunc(matrix, 1, 1)。
我们可以看到,doFunc(matrix, 1, 1)被重复计算了多次!对于一个大型矩阵,这种重复计算会呈指数级增长,导致时间复杂度非常高,直接超时!
这正是DFS的经典问题,我们需要引入记忆化搜索来解决它。
2.2 动态规划与记忆化搜索的优化解法
【总论述】
动态规划(DP)的核心思想是,将一个大问题分解为若干个子问题,并存储子问题的解,以便在需要时直接使用,避免重复计算。
对于“矩阵最长递增路径”问题,我们可以定义 dp[i][j] 为从点 (i, j) 出发的最长递增路径长度。我们的目标就是找到所有 dp[i][j] 中的最大值。
而记忆化搜索,就是动态规划的一种实现方式。它在DFS的基础上,引入一个记忆化数组 memo,用来缓存每个点的最长路径长度。
【目的与思路】
我们的目的是,通过记忆化搜索,优化DFS的性能,将算法复杂度从指数级降为多项式级。
我们的思路是:
-
记忆化数组: 创建一个二维数组
memo,用于存储每个点的最长递增路径长度。初始化所有值为0,表示尚未计算。 -
DFS函数: 修改DFS函数
dfs(matrix, i, j)。 -
检查缓存: 在DFS函数开始时,首先检查
memo[i][j]是否已计算。如果memo[i][j] > 0,说明已经计算过,直接返回memo[i][j]的值。 -
计算并缓存: 如果
memo[i][j]未计算,则按照暴力DFS的逻辑进行计算。计算完成后,将结果存入memo[i][j],然后再返回。
【详细代码与逻辑分析】
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// 四个方向:上、下、左、右
int dir[4][2] = {{1, 0}, {-1, 0}, {0, 1}, {0, -1}};
/**
* @brief 深度优先搜索函数,计算从(i,j)点出发的最长递增路径长度(记忆化搜索)
* @param matrix 二维矩阵
* @param i 当前行索引
* @param j 当前列索引
* @param memo 记忆化数组,用于存储已计算的结果
* @param R 矩阵行数
* @param C 矩阵列数
* @return int 从(i,j)点出发的最长递增路径长度
*/
int dfs_optimized(int **matrix, int i, int j, int **memo, int R, int C) {
// 1. 检查缓存:如果该点的结果已经计算过,直接返回
if (memo[i][j] != 0) {
return memo[i][j];
}
// 2. 初始化最长路径为1(当前点本身)
int maxLen = 1;
// 3. 向四个方向探索
for (int k = 0; k < 4; k++) {
int newi = i + dir[k][0];
int newj = j + dir[k][1];
// 4. 边界检查和递增条件
if (newi >= 0 && newi < R && newj >= 0 && newj < C && matrix[newi][newj] > matrix[i][j]) {
// 递归调用,并更新最长路径
int tempLen = 1 + dfs_optimized(matrix, newi, newj, memo, R, C);
if (tempLen > maxLen) {
maxLen = tempLen;
}
}
}
// 5. 将计算结果存入缓存
memo[i][j] = maxLen;
// 6. 返回结果
return maxLen;
}
/**
* @brief 求解矩阵最长递增路径的主函数(优化版本)
* @param matrix 二维矩阵
* @param matrixRowLen 矩阵行数
* @param matrixColLen 矩阵列数指针
* @return int 最长递增路径长度
*/
int solve_optimized(int **matrix, int matrixRowLen, int *matrixColLen) {
// 1. 边界条件处理
if (matrixRowLen == 0 || *matrixColLen == 0) {
return 0;
}
int C = *matrixColLen;
// 2. 动态分配内存给记忆化数组memo,并初始化为0
int **memo = (int **)malloc(matrixRowLen * sizeof(int *));
if (memo == NULL) return 0;
for (int i = 0; i < matrixRowLen; i++) {
memo[i] = (int *)calloc(C, sizeof(int));
if (memo[i] == NULL) {
// 内存分配失败,需要释放之前分配的内存
for (int j = 0; j < i; j++) {
free(memo[j]);
}
free(memo);
return 0;
}
}
// 3. 遍历矩阵,从每个点开始进行记忆化DFS
int maxLen = 0;
for (int i = 0; i < matrixRowLen; i++) {
for (int j = 0; j < C; j++) {
// 对每个点进行DFS,并更新最大值
int temp = dfs_optimized(matrix, i, j, memo, matrixRowLen, C);
if (temp > maxLen) {
maxLen = temp;
}
}
}
// 4. 释放内存
for (int i = 0; i < matrixRowLen; i++) {
free(memo[i]);
}
free(memo);
// 5. 返回最终结果
return maxLen;
}
【对比与总结】
-
暴力DFS: 优点是思路简单直观,但由于存在大量的重复计算,时间复杂度呈指数级,在大规模数据下会超时。
-
记忆化DFS(动态规划): 优点是解决了重复计算的问题,将时间复杂度降到了
O(R * C),其中R为行数,C为列数。空间复杂度为O(R * C),用于存储记忆化数组。 -
指针的运用: 在C语言中,处理二维数组时,通常需要使用二级指针
int **来进行动态内存分配和访问。这要求我们对指针、内存地址有深刻的理解。
通过这道题,我们不仅学会了如何使用DFS解决矩阵问题,更重要的是,掌握了动态规划的核心思想——“用空间换时间”,通过记忆化搜索来优化递归,从而将一个看似复杂的问题,变得高效且优雅。
预告:下篇硬核预告!
硬核之路,步入终章!
在下篇中,我们将挑战两道更加硬核、更能体现编程功底的题目:“大数加法”和“IP地址验证”!
-
大数加法: 我们将一起揭开计算机如何处理超过
long long范围的大数字的秘密,手把手实现一个基于字符串的大数加法器。 -
IP地址验证: 这道题看似简单,实则暗藏玄机。它不仅考察字符串处理,更考验你对边界条件、逻辑严谨性的把控。我们将从零开始,打造一个功能完备、鲁棒性极强的IP地址验证器!
如果你:
-
渴望深入底层,成为真正的“硬核”C程序员!
-
正在学习嵌入式开发,想打通任督二脉!
-
刷过牛客力扣,想在算法领域更进一步!
-
想系统学习计算机原理,不再停留在“表面”!
那么,请你:
-
立即点赞! 让更多同路人看到这份硬核!
-
果断收藏! 你的私人技术宝库,值得拥有!
-
慷慨转发! 帮助更多迷茫的兄弟,找到方向!
【核弹级长文三】硬核之路无止境:优快云深圳原力榜TOP42背后的C语言修炼心法(下篇)
序:终章!用代码之魂,铸就硬核巅峰!
兄弟们,硬核之路,步入终章!
在过去的篇章里,我们一起探索了字符串操作的精妙,感受了双指针和动态规划的魅力,在算法的海洋里乘风破浪。我看到了你们对硬核技术的渴望,感受到了我们共同前进的动力!
今天,我将为你们献上这篇“核弹级”技术长文的收官之作!
下篇将挑战两道更加硬核、更能体现编程功底的题目:“大数加法”和“IP地址验证”!
-
大数加法: 计算机内置的数据类型(如
int、long long)都有其存储上限。当我们要处理超过这些上限的大数时,该怎么办?我们将一起揭开这个秘密,用字符串作为“容器”,手把手实现一个基于字符串的大数加法器。这不仅仅是算法,更是对数据结构和底层原理的深刻理解! -
IP地址验证: 这道题看似简单,实则暗藏玄机。它不仅考察字符串处理,更考验你对边界条件、逻辑严谨性的把控,以及对计算机网络基础知识的理解。我们将从零开始,打造一个功能完备、鲁棒性极强的IP地址验证器!
我希望,这篇终章能够帮助你将前面所学的一切融会贯通,形成一个完整的硬核技术体系。在读完之后,你将不仅能掌握这些知识点,更能拥有那种“不畏困难,勇于探索,追求极致”的硬核精神!
深呼吸,握紧你的键盘,让我们进入终章的硬核修炼时间!
第三部分:终极挑战——大数加法与IP地址验证
3.1 大数加法:用字符串打破数字的边界!
【总论述】
在C语言中,long long类型最大能表示的十进制数约为9times1018。然而,在现实世界中,我们常常需要处理超过这个范围的超大数字,比如天文计算、密码学、金融领域等。
这时,我们需要将数字以字符串的形式进行存储,然后模拟人手算加法的过程,从个位开始,逐位相加,并处理进位。
【目的与思路】
我们的目的是,编写一个函数,接收两个字符串形式的大数,返回它们的和,也是一个字符串。
我们的思路是:
-
反转字符串: 为了方便从个位开始相加,我们可以先将两个字符串进行反转。
-
逐位相加: 遍历两个反转后的字符串,将对应位置的字符转换为数字,进行相加,并加上上一位的进位。
-
处理进位: 每一位相加的结果,对10取余就是当前位的结果,除以10就是下一位的进位。
-
拼接结果: 将每一位的结果字符拼接到一个新的结果字符串中。
-
最终处理: 循环结束后,如果还有进位,需要将进位也添加到结果中。最后,将结果字符串再反转回来,得到最终的正确顺序。
这种思路,完美地模拟了我们小学学习的竖式加法,简单而有效。
【详细代码与逻辑分析】
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
/**
* @brief 反转字符串
* @param str 待反转的字符串
*/
void reverse_string(char* str) {
int len = strlen(str);
int i = 0;
int j = len - 1;
while (i < j) {
char temp = str[i];
str[i] = str[j];
str[j] = temp;
i++;
j--;
}
}
/**
* @brief 大数相加,返回新的字符串
* @param s 字符串形式的第一个大数
* @param t 字符串形式的第二个大数
* @return char* 字符串形式的和
*/
char* solve_big_number_addition(char* s, char* t) {
// 1. 获取字符串长度并进行边界处理
int len_s = strlen(s);
int len_t = strlen(t);
if (len_s == 0) return strdup(t);
if (len_t == 0) return strdup(s);
// 2. 为了方便从低位(个位)开始计算,我们先将两个字符串反转
char* s_reversed = strdup(s); // 创建副本,以免修改原字符串
char* t_reversed = strdup(t);
reverse_string(s_reversed);
reverse_string(t_reversed);
// 3. 确定结果字符串的最大长度
int max_len = (len_s > len_t ? len_s : len_t) + 2; // +1为了进位,+1为了'\0'
char* res = (char*)malloc(max_len * sizeof(char));
if (res == NULL) {
free(s_reversed);
free(t_reversed);
return NULL;
}
// 4. 逐位相加并处理进位
int i = 0, j = 0, k = 0, carry = 0;
while (i < len_s || j < len_t || carry > 0) {
// 获取当前位的数字
int num_s = (i < len_s) ? (s_reversed[i] - '0') : 0;
int num_t = (j < len_t) ? (t_reversed[j] - '0') : 0;
// 计算当前位的和
int sum = num_s + num_t + carry;
// 更新进位和当前位的结果
carry = sum / 10;
res[k] = (sum % 10) + '0';
// 移动指针
i++;
j++;
k++;
}
// 5. 释放临时字符串并添加字符串结束符
free(s_reversed);
free(t_reversed);
res[k] = '\0';
// 6. 再次反转结果字符串,得到最终的正确顺序
reverse_string(res);
return res;
}
【图解分析】
以s="99", t="1"为例,我们来图解一下solve_big_number_addition的执行过程。
初始状态: s -> "99" t -> "1"
第一步:反转字符串
-
s_reversed->"99" -
t_reversed->"1"
第二步:逐位相加
-
循环1 (
i=0,j=0,carry=0):-
num_s = 9,num_t = 1 -
sum = 9 + 1 + 0 = 10 -
carry = 10 / 10 = 1 -
res[0] = (10 % 10) + '0' = '0'
-
-
循环2 (
i=1,j=1,carry=1):-
num_s = 9,num_t = 0(因为j已越界) -
sum = 9 + 0 + 1 = 10 -
carry = 10 / 10 = 1 -
res[1] = (10 % 10) + '0' = '0'
-
-
循环3 (
i=2,j=1,carry=1):-
i和j都已越界,但carry为1 -
sum = 0 + 0 + 1 = 1 -
carry = 1 -
res[2] = '1'
-
-
循环结束。
i=2,j=1,carry=0
第三步:最终处理
-
res->"001" -
reverse_string(res) -
res->"100"
最终结果:
-
返回
res,即"100"。
【总结】
大数加法问题,完美地诠释了“化整为零”的思想。我们将一个宏观的数学问题,分解为一个个微观的字符相加,并通过进位将它们串联起来。这道题不仅考察了基本的字符串操作和指针使用,更重要的是,它让你重新审视了数字的本质,以及计算机如何用最基础的数据类型来模拟复杂的数学运算。
3.2 IP地址验证:严谨性与鲁棒性的终极考验!
【总论述】
IP地址,是计算机网络的“身份证”。一个IP地址通常由四个十进制数组成,每个数介于0到255之间,并由点号.分隔。验证一个字符串是否是有效的IP地址,看似简单,实则需要考虑多种边界情况。
这道题考察的是你编写代码的严谨性和鲁棒性,以及对字符串处理函数(如strtok、sscanf)的深刻理解。
【目的与思路】
我们的目的是,编写一个函数,接收一个字符串,判断它是否是一个有效的IP地址。
我们的思路是:
-
拆分字符串: 使用
strtok函数,以.为分隔符,将IP地址字符串拆分为四个部分。 -
数量检查: 检查拆分后是否恰好有四个部分。如果不满四部分,直接返回无效。
-
逐段验证: 遍历这四个部分,对每一段进行验证。
-
非空检查: 每一段都不能是空字符串。
-
长度检查: 每一段的长度不能超过3位。
-
前导零检查: 除了数字
0本身,任何一段都不能以0开头(例如01是无效的)。 -
字符检查: 每一段必须只包含数字字符。
-
数值范围检查: 将每一段转换为数字,检查其是否在0到255之间。
-
-
返回结果: 如果所有段都通过了验证,则返回有效;否则,返回无效。
【详细代码与逻辑分析】
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdbool.h>
#include <ctype.h>
/**
* @brief 验证单个IP段是否有效
* @param segment 待验证的IP段字符串
* @return bool 如果IP段有效,返回true;否则返回false
*/
bool is_valid_segment(char* segment) {
// 1. 空字符串检查
if (segment == NULL || strlen(segment) == 0) {
return false;
}
// 2. 长度检查:IP段长度不能超过3位
if (strlen(segment) > 3) {
return false;
}
// 3. 前导零检查:如果长度大于1且以'0'开头,则无效
if (strlen(segment) > 1 && segment[0] == '0') {
return false;
}
// 4. 字符检查:必须全部由数字组成
for (int i = 0; i < strlen(segment); i++) {
if (!isdigit(segment[i])) {
return false;
}
}
// 5. 数值范围检查:转换为整数,判断是否在0-255之间
int num = atoi(segment);
if (num >= 0 && num <= 255) {
return true;
}
return false;
}
/**
* @brief 验证字符串是否是有效的IP地址
* @param ip 待验证的IP地址字符串
* @return bool 如果IP地址有效,返回true;否则返回false
*/
bool is_valid_ip(char* ip) {
// 1. 空字符串检查
if (ip == NULL || strlen(ip) == 0) {
return false;
}
// 2. 创建一个副本,因为strtok会修改原字符串
char* ip_copy = strdup(ip);
if (ip_copy == NULL) {
return false;
}
// 3. 使用strtok进行字符串拆分
char* segment = strtok(ip_copy, ".");
int segment_count = 0;
// 4. 逐段验证
while (segment != NULL) {
segment_count++;
// 对每一段进行验证
if (!is_valid_segment(segment)) {
free(ip_copy);
return false;
}
// 获取下一段
segment = strtok(NULL, ".");
}
// 5. 检查段数是否为4
free(ip_copy);
return segment_count == 4;
}
【总结】
IP地址验证问题,是考察编程严谨性的绝佳题目。它要求我们不仅要考虑核心逻辑,更要细致入微地处理各种边界情况。通过这道题,我们强化了对字符串处理函数的理解,也锻炼了我们编写健壮代码的能力。
对于嵌入式程序员来说,IP地址、网络通信是绕不开的话题。这道题的解决,将为你在网络编程的道路上打下坚实的基础。
终章总结:硬核之路,始于足下,永无止境!
恭喜你,兄弟!你已经成功完成了这场“核弹级”技术长文的终极修炼!
从字符串的底层操作,到双指针与动态规划的算法之魂,再到大数加法和IP地址验证的严谨挑战,我们一起走过了一段充满硬核代码和深度思考的旅程。
我希望,这份长文不仅仅是一份技术总结,更是一种精神的传承:
-
硬核,是深入底层,而非停留在表面。
-
硬核,是勇于挑战,而非安于现状。
-
硬核,是严谨细致,而非敷衍了事。
我知道,技术之路永无止境,我们还将面临更多的挑战。但请你记住,只要我们保持着这份硬核精神,就没有什么能够阻挡我们前进的脚步!
让我们一起,在技术的道路上,继续冲锋,创造属于我们自己的辉煌!
最后,感谢你的一路陪伴!如果你:
-
渴望深入底层,成为真正的“硬核”C程序员!
-
正在学习嵌入式开发,想打通任督二脉
那么,请你:
-
立即点赞! 让更多同路人看到这份硬核!
-
果断收藏! 你的私人技术宝库,值得拥有!
-
慷慨转发! 帮助更多迷茫的兄弟,找到方向
4 *****附录原始代码>>>>>
1 字符串变形: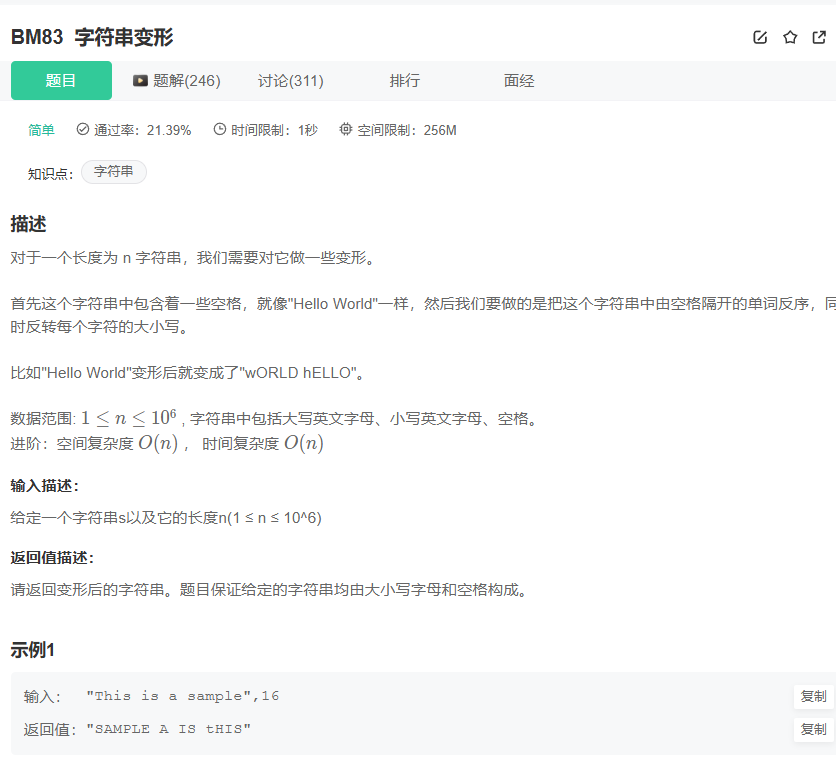
// /**
// * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
// *
// *
// * @param s string字符串
// * @param n int整型
// * @return string字符串
// */
// #include <stdio.h>
// #include <stdlib.h>
// #include <string.h>
// #include <ctype.h>
// void reverse(char *s, int start, int end)
// {
// int left = start;
// int right = end;
// while (left < right)
// {
// char temp = s[left];
// s[left] = s[right];
// s[right] = temp;
// left++;
// right--;
// }
// }
// char *trans(char *s, int n)
// {
// char *res = (char *)malloc((n + 1) * sizeof(char));
// // write code here
// // 首先这个字符串中包含着一些空格,就像"Hello World"一样,然后我们要做的是把这个字符串中由空格隔开的单词反序,同时反转每个字符的大小写。
// // 比如"Hello World"变形后就变成了"wORLD hELLO"
// // 1 hELLO wORLD 大小写转换
// // 2 DLROw OLLEh 整个反过来
// // 3 wORLD hELLO每个单词反过来
// int i = 0;
// // 1直接把整个字符大小写替换
// int len = strlen(s);
// for (int i = 0; i < len; i++)
// {
// // 如果是大写
// char x = s[i];
// if (x >= 'A' && x <= 'Z')
// {
// printf("原来是%c\n", x);
// x = tolower(x);
// }
// // 小写
// else
// {
// printf("原来是%c\n", x);
// // printf("现在是%c\n",x);
// x = toupper(x);
// }
// res[i] = x;
// printf("函数里处理完:< %c > \n", res[i]);
// // 小写
// }
// // for(int i =0;i<n;i++){
// // printf("总的来说 函数里变成:《%s》\n ",res);
// // }
// printf("1 第一步结束 函数里变成:《%s》\n ", res);
// // 2把头尾转换
// reverse(res, 0, n-1);
// printf("第二部结束,现在是 %s \n",res);
// // 3 对每个单词反序
// int left = 0;
// for(int i =0;i<=n;i++){
// if(res[i]==' ' || i==n ){
// reverse(res,left,i-1);
// left = i+1;
// }
// }
// printf("第三步结束之后:%s \n",res);
// return res;
// }
// int main()
// {
// char *juzi = "Caonima Trump Fuck You";
// int len = strlen(juzi);
// printf("处理完了!----\n");
// printf("%s \n", trans(juzi, len));
// return 0;
// }
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param s string字符串
* @param n int整型
* @return string字符串
*/
void reverse(char* s, int left, int right) {
while (left < right) {
int x = 0;
char* t = &x;
*t = s[left];
s[left] = s[right];
s[right] = *t;
left++;
right--;
}
}
char* trans(char* s, int n) {
// write code here
// 反转大小写、顺序、单词顺序
char* res = (char*)malloc((n + 1) * sizeof(char));
for (int i = 0; i < n; i++) {
if (s[i] >= 'a' && s[i] <= 'z') {
res[i] = s[i] - 32;
} else if (s[i] >= 'A' && s[i] <= 'Z') {
res[i] = s[i] + 32;
} else {
res[i] = s[i];
}
}
// 反转整个字符串
reverse(res, 0, n - 1);
// 把每个单词反转
int start = 0, i = 0;
// while (i < n)
// {
// while (start != ' ')
// {
// start++;
// }
// reverse(res, i, start);
// while (i < start)
// {
// i++;
// }
// }
for (int i = 0; i <= n; i++) {
if (res[i] == ' ' || res[i] == '\0') {
reverse(res, start, i - 1);
start = i + 1;
}
}
res[n] = '\0';
return res;
}
2 最长公共前缀:
思路:
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param strs string字符串一维数组
* @param strsLen int strs数组长度
* @return string字符串
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
char *longestCommonPrefix(char **strs, int strsLen)
{
// write code here
int len = strlen(strs[0]);
// 最长也就是第一个这么长了
char *res = (char *)malloc(len * sizeof(char));
if (strs == NULL || strsLen == 0)
{
char *temp = (char *)malloc(1 * sizeof(char));
temp[0] = '\0';
return temp;
}
strcpy(res, strs[0]);
for (int i = 1; i < strsLen; i++)
{
int start = 0;
while (res[start] && strs[i][start] && strs[i][start] == res[start])
{
start++;
}
res[start] = '\0';
if (start == 0)
{
return res;
}
}
return res;
}
int main()
{
char **strs = (char **)malloc(3 * sizeof(char *));
for (int i = 0; i < 3; i++)
{
strs[i] = (char *)malloc(5 * sizeof(char));
}
strs[0] = strdup("abc");
strs[1] = strdup("ab");
strs[2] = strdup("abcdd");
printf("%s", longestCommonPrefix(strs, 3));
}
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param strs string字符串一维数组
* @param strsLen int strs数组长度
* @return string字符串
*/
#include <string.h>
char *longestCommonPrefix(char **strs, int strsLen)
{
// write code here
if (strsLen == 0)
{
char *res = (char *)malloc(1 * sizeof(char));
res[0] = '\0';
return res;
}
int minLen = 5000;
for (int i = 0; i < strsLen; i++)
{
int tempLen = strlen(strs[i]);
// strlen是个函数 求的是实际长度
minLen = tempLen < minLen ? tempLen : minLen;
}
char *res = (char *)malloc((minLen + 1) * sizeof(char));
if (strsLen == 1)
{
// res[0] = strs[0][0];
// res[0][1] = strs[0][1];
// #!!!!vip
// 直接用strncpuy函数
strncpy(res, strs[0], strlen(strs[0]));
// res[1] = '\0';
res[strlen(strs[0]) + 1] = '\0';
return res;
}
res[0] = strs[0][0];
int validLen = minLen;
int i = 0;
for (; i < validLen; i++)
{
char c = strs[0][i];
int j = 1;
for (; j < strsLen; j++)
{
if (strs[j][i] != c)
{
break;
}
}
if (j != strsLen)
{
break;
}
res[i] = c;
}
// int len = strlen(res);
res[i] = '\0';
return res;
}
3 大数加法:
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
* 计算两个数之和
* @param s string字符串 表示第一个整数
* @param t string字符串 表示第二个整数
* @return string字符串
*/
#include <stdio.h>
#include <stdlib.h>
void reverse(char *s, int left, int right)
{
while (left < right)
{
char temp = s[left];
s[left] = s[right];
s[right] = temp;
left++;
right--;
}
}
char *solve(char *s, char *t)
{
// write code here
int len1 = strlen(s);
int len2 = strlen(t);
int maxLen = len1 > len2 ? len1 : len2;
int flag = 0;
char *res = (char *)malloc((maxLen + 1) * sizeof(char));
int i = len1 - 1, j = len2 - 1;
int count = 0;
// int k =
while (i >= 0 || j >= 0 || flag > 0)
{
int a = i >= 0 ? s[i] - '0' : 0;
int b = j >= 0 ? t[j] - '0' : 0;
int sum = a + b + flag;
int tempRes = sum % 10;
flag = sum / 10;
res[count] = tempRes + '0';
count++;
i--;
j--;
}
reverse(res, 0, count - 1);
res[count] = '\0';
return res;
}
int main(void)
{
char a[] = "9";
char b[] = "99999999999999999999999999999999999999999999999999999999999994";
printf("%s \n", solve(a, b));
return 0;
}
4 验证ip地址?较难复杂!!
/**
* ?????е???????????????????????????????????????????????涨???????
*
* ???IP???
* @param IP string????? ???IP????????
* @return string?????
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <ctype.h>
char *solve4(char *IP)
{
// write code here
char *p = IP;
int count = 0;
while (*p != '\0')
{
if (count > 3)
{
return "Neither";
}
if (*p == '.')
{
count++;
}
else if (!isdigit(*p))
{
return "Neither";
}
p++;
}
if (count != 3)
{
return "Neither";
}
// 检查完 : . 个数+ 是不是数字 第一层
p = IP;
// ???????????????????з??
char *token = strtok(IP, ".");
int part_count = 0;
while (token)
{
//?????0.0.0.1
// #self !!!vip
int len = strlen(token);
// ????? ??????3?? ????1????12.08.08.12 #self
if (len == 0 || len > 3 || (len > 1) && (token[0] == '0'))
{
return "Neither";
}
part_count++;
// #self !!!vip ???????? atoi()
int num = atoi(token);
if (num < 0 || num > 255)
{
return "Neither";
}
token = strtok(NULL, ".");
}
return part_count == 4 ? "IPv4" : "Neither";
}
char *solve6(char *IP)
{
char *p = IP;
int count = 0;
int prev_is_colon = 0;
while (*p)
{
if (*p == ':')
{
if (prev_is_colon)
return "Neither";
count++;
if (count > 7)
return "Neither";
prev_is_colon = 1;
}
else
{
if (!isxdigit(*p))
{
return "Neither";
// prev_is_colon = 0;
}
prev_is_colon = 0;
}
p++;
}
if (count != 7)
{
return "Neither";
}
// 1层 结束: 搞完了数量+数字本身性质
char *token = strtok(IP, ":");
int count2 = 0;
while (token)
{
count2++;
int len = strlen(token);
if (len < 1 || len > 4)
{
return "Neither";
}
token = strtok(NULL, ":");
}
return (count2 == 8) ? "IPv6" : "Neither";
}
// #self 搞了两个小时
// char *solve6(char *IP) {
// char *p = IP;
// int colon_count = 0;
// int prev_is_colon = 0;
// // 检查冒号数量、连续冒号、非法字符
// while (*p) {
// if (*p == ':') {
// if (prev_is_colon) return "Neither"; // 禁止连续冒号
// colon_count++;
// if (colon_count > 7) return "Neither";
// prev_is_colon = 1;
// } else {
// if (!isxdigit(*p)) return "Neither";
// prev_is_colon = 0;
// }
// p++; // 指针必须移动
// }
// if (colon_count != 7) return "Neither";
// // 分割并验证段数和长度
// char *token = strtok(IP, ":");
// int part_count = 0;
// while (token) {
// part_count++;
// if (strlen(token) < 1 || strlen(token) > 4) return "Neither";
// token = strtok(NULL, ":");
// }
// return (part_count == 8) ? "IPv6" : "Neither";
// }
char *solve(char *IP)
{
// 两种情况:two case:
// whether has : or . #self !!!vip
int hasMao = 0, hasDun = 0;
for (int i = 0; IP[i]; i++)
{
if (IP[i] == '.')
{
hasDun = 1;
break;
}
if (IP[i] == ':')
{
hasMao = 1;
break;
}
}
if (hasDun)
{
char *res1 = solve4(IP);
return (strcmp(res1, "IPv4") == 0) ? "IPv4" : "Neither";
}
if (hasMao)
{
char *res2 = solve6(IP);
return (strcmp(res2, "IPv6") == 0) ? "IPv6" : "Neither";
// return res2;
}
return "Neither";
}
int main()
{
char *ip = (char *)malloc(100 * sizeof(char));
// #self !!!vip
//?????????????γ??????
char *s = "192.168.1";
strcpy(ip, s);
printf("ip1 is : %s \n", s);
char *res = solve(ip);
printf("s1 RESULT IS : %s \n\n", res);
char *s2 = "12.123.123.256";
printf("ip2 is : %s \n", s2);
strcpy(ip, s2);
char *res2 = solve(ip);
printf("s2 RESULT IS : %s \n\n", res2);
// #self !!!vip
// compress 0
char *s3 = "2001:db8:85a3:0::8a2E:0370:7334";
strcpy(ip, s3);
printf("ip3 is : %s \n", s3);
char *res3 = solve(ip);
printf("s3 RESULT IS : %s \n\n", res3);
return 0;
}
第二部分:
双指针:
1 合并区间:“
代码:
// #include <stdio.h>
// #include <stdlib.h>
// int compareFn(void *a, void *b)
// {
// struct Interval *x = (struct Interval *)a;
// struct Interval *y = (struct Interval *)b;
// return x->start - y->start;
// }
// struct Interval *merge(struct Interval *intervals, int intervalsLen,
// int *returnSize)
// {
// if (intervalsLen == 0)
// {
// *returnSize = 0;
// return NULL;
// }
// qsort(intervals, intervalsLen, sizeof(struct Interval), compareFn);
// struct Interval *res = (struct Interval *)malloc(intervalsLen * sizeof(
// struct Interval));
// res[0] = intervals[0];
// int count = 0;
// for (int i = 1; i < intervalsLen; i++)
// {
// if (intervals[i].start <= res[count].end)
// {
// if (intervals[i].end > res[count].end)
// {
// // 需要更新interval[i]的end了,往后延长
// res[count].end = intervals[i].end;
// }
// }
// else
// {
// // count++;
// res[++count] = intervals[i];
// }
// }
// *returnSize = count + 1;
// return res;
// }
// int main()
// {
// // for(int)
// return 0;
// }
// 2刷
#include <stdio.h>
#include <stdlib.h>
struct Interval
{
int start;
int end;
};
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param intervals Interval类一维数组
* @param intervalsLen int intervals数组长度
* @return Interval类一维数组
* @return int* returnSize 返回数组行数
*/
int cmp(const void *a, const void *b)
{
struct Interval *x = (struct Interval *)a;
struct Interval *y = (struct Interval *)b;
return x->start - y->start;
}
struct Interval *merge(struct Interval *intervals, int intervalsLen, int *returnSize)
{
// write code here
struct Interval *res = (struct Interval *)malloc(intervalsLen * sizeof(struct Interval));
if (!intervals || intervalsLen == 0)
{
*returnSize = 0;
return res;
}
if (intervalsLen == 1)
{
res[0] = intervals[0];
*(returnSize) = 1;
return res;
}
qsort(intervals, intervalsLen, sizeof(struct Interval), cmp);
res[0] = intervals[0];
*returnSize = 1;
for (int i = 1; i < intervalsLen; i++)
{
if (intervals[i].start > res[*returnSize - 1].end)
{
(*returnSize)++;
// #!!!vip
res[*returnSize - 1] = intervals[i];
}
else
{
res[*returnSize - 1].end = (res[*returnSize - 1].end > intervals[i].end) ? res[*returnSize - 1].end : intervals[i].end;
}
}
return res;
}
2 最长无重复子数组:
给定一个长度为n的数组arr,返回arr的最长无重复元素子数组的长度,无重复指的是所有数字都不相同。
子数组是连续的,比如[1,3,5,7,9]的子数组有[1,3],[3,5,7]等等,但是[1,3,7]不是子数组
数据范围:0≤arr.length≤1050≤arr.length≤105,0<arr[i]≤1050<arr[i]≤105
输入:
[2,3,4,5]
复制返回值:
4
复制说明:
[2,3,4,5]是最长子数组
输入:
[2,2,3,4,3]
复制返回值:
3
复制说明:
[2,3,4]是最长子数组
code:
// #include <stdio.h>
// #include <stdlib.h>
// int compareFn(void *a, void *b)
// {
// struct Interval *x = (struct Interval *)a;
// struct Interval *y = (struct Interval *)b;
// return x->start - y->start;
// }
// struct Interval *merge(struct Interval *intervals, int intervalsLen,
// int *returnSize)
// {
// if (intervalsLen == 0)
// {
// *returnSize = 0;
// return NULL;
// }
// qsort(intervals, intervalsLen, sizeof(struct Interval), compareFn);
// struct Interval *res = (struct Interval *)malloc(intervalsLen * sizeof(
// struct Interval));
// res[0] = intervals[0];
// int count = 0;
// for (int i = 1; i < intervalsLen; i++)
// {
// if (intervals[i].start <= res[count].end)
// {
// if (intervals[i].end > res[count].end)
// {
// // 需要更新interval[i]的end了,往后延长
// res[count].end = intervals[i].end;
// }
// }
// else
// {
// // count++;
// res[++count] = intervals[i];
// }
// }
// *returnSize = count + 1;
// return res;
// }
// int main()
// {
// // for(int)
// return 0;
// }
// 2刷
#include <stdio.h>
#include <stdlib.h>
struct Interval
{
int start;
int end;
};
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param intervals Interval类一维数组
* @param intervalsLen int intervals数组长度
* @return Interval类一维数组
* @return int* returnSize 返回数组行数
*/
int cmp(const void *a, const void *b)
{
struct Interval *x = (struct Interval *)a;
struct Interval *y = (struct Interval *)b;
return x->start - y->start;
}
struct Interval *merge(struct Interval *intervals, int intervalsLen, int *returnSize)
{
// write code here
struct Interval *res = (struct Interval *)malloc(intervalsLen * sizeof(struct Interval));
if (!intervals || intervalsLen == 0)
{
*returnSize = 0;
return res;
}
if (intervalsLen == 1)
{
res[0] = intervals[0];
*(returnSize) = 1;
return res;
}
qsort(intervals, intervalsLen, sizeof(struct Interval), cmp);
res[0] = intervals[0];
*returnSize = 1;
for (int i = 1; i < intervalsLen; i++)
{
if (intervals[i].start > res[*returnSize - 1].end)
{
(*returnSize)++;
// #!!!vip
res[*returnSize - 1] = intervals[i];
}
else
{
res[*returnSize - 1].end = (res[*returnSize - 1].end > intervals[i].end) ? res[*returnSize - 1].end : intervals[i].end;
}
}
return res;
}
3 .盛水最多容器?
// int max (int a, int b ) {
// return a > b ? a : b;
// }
// int min(int a, int b ) {
// return a < b ? a : b;
// }
// int maxArea(int* height, int heightLen) {
// //从这里开始到外面,两个指针两个指针从两边往中间靠近哪边低就先走哪边因为有一
// // 个最简单的原因你往中间走我这个宽度在减少那么一定要使两边这个指针的高度增加我的总面积才会增加
// int left = 0, right = heightLen - 1;
// int maxSuqure = 0;
// while (left < right) {
// int curS = (right - left) * (min(height[right], height[left]));
// maxSuqure = max(curS, maxSuqure);
// if (height[left] < height[right]) {
// left++;
// } else {
// right--;
// }
// }
// return maxSuqure;
// }
// 2刷
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param height int整型一维数组
* @param heightLen int height数组长度
* @return int整型
*/
int maxArea(int *height, int heightLen)
{
// write code here
int left = 0, right = heightLen - 1;
int maxArea = 0;
while (left < right)
{
int tempArea = min(height[left],height[right])*(right-left);
}
}
最近忙其他事情,将近5天没正儿八经每天系统刷题+提交+总结模块化题目了,补回


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









