




1 文章来源:

今天下午搞这个题目的时候,竟然再数组指针和指针数组这里碰到了一个问题,数组指针和指针数组的核心区别!!!!!非常重要!!!!
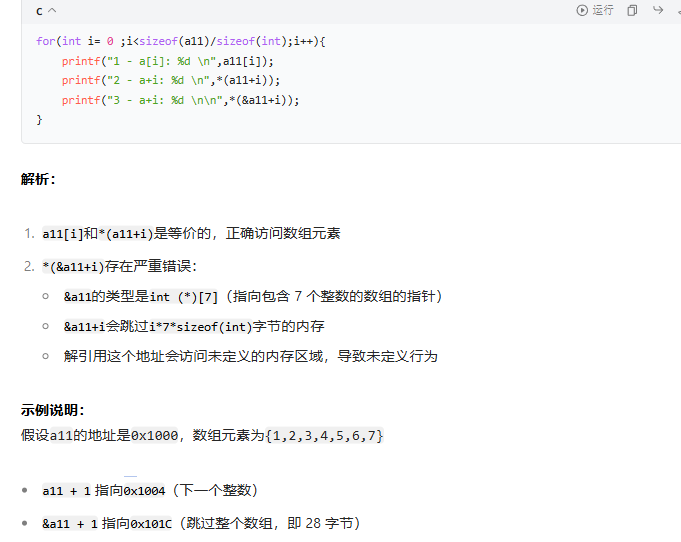
这是非常核心的一个认知错误!!!
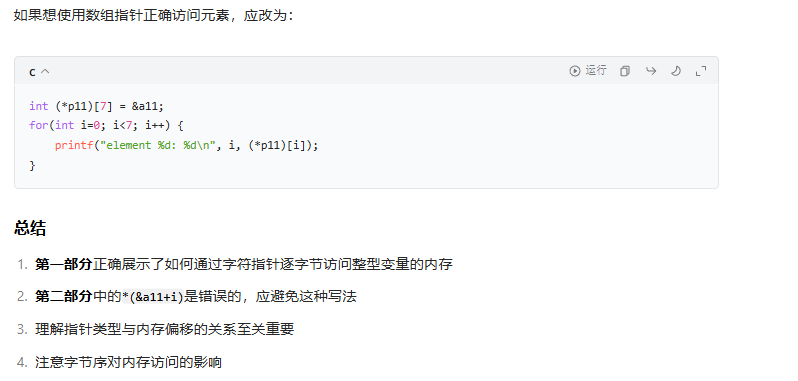
在 C 语言的浩瀚世界里,指针无疑是其最强大也最令人望而却步的特性之一。而当指针与数组结合时,便诞生了两个常常让初学者乃至有经验的开发者都感到困惑的概念:数组指针(Pointer to Array)和指针数组(Array of Pointers)。它们在语法上仅有一字之差,但在语义和用途上却有着天壤之别。
1. 概念辨析:形似神异
在理解数组指针和指针数组之前,我们必须牢记 C 语言中一个核心的规则:“近绑定”原则。这意味着在声明中,一个变量会优先与其最近的修饰符结合。
1.1. 数组指针 (Pointer to Array)
定义: 数组指针,本质上是一个指针。它指向的是一个完整的数组。
声明形式: Type (*pointer_name)[size];
-
Type:数组中元素的数据类型。 -
*pointer_name:括号()的存在使得pointer_name首先与*结合,表明pointer_name是一个指针。 -
[size]:接在(*pointer_name)之后,表示这个指针指向的是一个包含size个Type类型元素的数组。
理解要点:
-
“先是一个指针”:
(*pointer_name)决定了它的本质是指针。 -
“再指向一个数组”:
[size]决定了它指向的目标是一个具有特定大小的数组。 -
类型匹配:数组指针的类型必须与其所指向的数组的类型和大小完全匹配。
示例:
int arr[5]; // 声明一个包含5个整型元素的数组
int (*p)[5]; // 声明一个数组指针 p,它指向一个包含5个整型元素的数组
p = &arr; // 将数组 arr 的地址赋值给 p
在这里,p 的类型是 int (*)[5]。这意味着 p 存储的是 arr 整个数组的地址。当你对 p 进行 p + 1 运算时,它会跳过整个 arr 数组的大小(5 * sizeof(int) 字节)。
1.2. 指针数组 (Array of Pointers)
定义: 指针数组,本质上是一个数组。它的每个元素都是一个指针。
声明形式: Type *array_name[size];
-
Type:数组中每个指针所指向的数据类型。 -
array_name[size]:array_name首先与[size]结合,表明array_name是一个包含size个元素的数组。 -
*:接在Type和array_name[size]之间,表示数组的每个元素都是Type类型的指针。
理解要点:
-
“先是一个数组”:
array_name[size]决定了它的本质是数组。 -
“再是每个元素都是指针”:
*决定了数组的每个元素都是指针类型。 -
元素独立:数组中的每个指针元素可以指向不同的内存位置,甚至可以是不同的类型(尽管通常为了类型安全,会保持一致)。
示例:
int *arr_ptr[3]; // 声明一个指针数组 arr_ptr,它包含3个指向整型的指针
int a = 10, b = 20, c = 30;
arr_ptr[0] = &a; // arr_ptr 的第一个元素指向变量 a
arr_ptr[1] = &b; // arr_ptr 的第二个元素指向变量 b
arr_ptr[2] = &c; // arr_ptr 的第三个元素指向变量 c
在这里,arr_ptr 的类型是 int *[3]。这意味着 arr_ptr 是一个数组,它里面存放了三个 int* 类型的指针。每个 arr_ptr[i] 都是一个独立的指针变量。
2. 内存布局与操作差异
理解了定义,接下来我们将通过内存布局和实际操作来进一步区分两者。
2.1. 数组指针的内存布局与操作
一个数组指针变量本身只占用固定的内存空间(通常是 4 或 8 字节,取决于系统位数),用于存储它所指向的整个数组的起始地址。
内存布局(示意图):
内存地址 -> | ... |
| ------- |
| p (地址) | <-- 数组指针 p 存储的地址
| ------- |
| ... |
| ------- |
| arr[0] | <-- arr 数组的起始地址
| arr[1] |
| arr[2] |
| arr[3] |
| arr[4] |
| ------- |
| ... |
操作:
-
赋值: 只能通过
&数组名获取整个数组的地址来赋值给数组指针。int arr[5]; int (*p)[5] = &arr; // 正确 // int (*p)[5] = arr; // 错误!arr 是首元素地址,类型是 int*,与 int (*)[5] 不匹配 -
解引用:
-
*p:解引用数组指针p得到的是它所指向的整个数组。*p的类型相当于int[5]。 -
(*p)[i]:通过解引用得到的数组再通过下标访问元素。 -
p[0][i]:另一种等价的访问方式,编译器会将p[0]解释为*p。 -
p[i]:当i不为 0 时,p[i]会被解释为*(p + i),即跳过i个完整数组的地址,然后解引用。这在实际中很少用于单个数组指针,更多用于数组指针的数组(即指向多个数组的数组指针)。
-
-
指针算术:
-
p + 1:移动到下一个“完整数组”的起始地址。如果p指向arr,那么p + 1将指向arr后面紧接着的内存区域(如果存在的话,或者更准确地说是跳过sizeof(*p)即sizeof(arr)字节)。 -
p - 1:移动到前一个“完整数组”的起始地址。
-
示例代码:
#include <stdio.h>
int main() {
int arr[5] = {10, 20, 30, 40, 50};
int (*p)[5]; // 声明一个数组指针,指向一个包含5个整型元素的数组
p = &arr; // 将数组 arr 的地址赋值给 p
printf("arr 的地址: %p\n", (void*)arr);
printf("&arr 的地址: %p\n", (void*)&arr);
printf("p 的值 (arr 的地址): %p\n", (void*)p);
printf("p + 1 的值: %p (跳过 sizeof(arr) 字节)\n", (void*)(p + 1));
printf("----------------------------------------\n");
// 访问数组元素
printf("通过数组指针访问元素:\n");
for (int i = 0; i < 5; i++) {
printf("(*p)[%d] = %d\n", i, (*p)[i]);
}
printf("----------------------------------------\n");
// 另一种访问方式:p[0] 等价于 *p
printf("通过 p[0] 访问元素:\n");
for (int i = 0; i < 5; i++) {
printf("p[0][%d] = %d\n", i, p[0][i]);
}
printf("----------------------------------------\n");
return 0;
}
运行结果(示例):
arr 的地址: 000000AA62DFFB20
&arr 的地址: 000000AA62DFFB20
p 的值 (arr 的地址): 000000AA62DFFB20
p + 1 的值: 000000AA62DFFB34 (跳过 sizeof(arr) 字节) // 0x34 - 0x20 = 0x14 = 20 字节 (5 * 4 字节)
----------------------------------------
通过数组指针访问元素:
(*p)[0] = 10
(*p)[1] = 20
(*p)[2] = 30
(*p)[3] = 40
(*p)[4] = 50
----------------------------------------
通过 p[0] 访问元素:
p[0][0] = 10
p[0][1] = 20
p[0][2] = 30
p[0][3] = 40
p[0][4] = 50
----------------------------------------
2.2. 指针数组的内存布局与操作
一个指针数组变量本身占用 size * sizeof(Type*) 字节的内存空间,因为它需要为每个指针元素分配独立的存储空间。
内存布局(示意图):
内存地址 -> | ... |
| ------- |
| arr_ptr[0] (存储的是 &a 的地址) | <-- 指针数组 arr_ptr 的起始地址
| ------- |
| arr_ptr[1] (存储的是 &b 的地址) |
| ------- |
| arr_ptr[2] (存储的是 &c 的地址) |
| ------- |
| ... |
| ------- |
| a (值 10) | <-- 变量 a 的地址
| ------- |
| b (值 20) | <-- 变量 b 的地址
| ------- |
| c (值 30) | <-- 变量 c 的地址
| ------- |
| ... |
操作:
-
赋值: 数组的每个元素都可以独立地被赋值为某个变量的地址,或者另一个指针的值。
int *arr_ptr[3]; int a = 10, b = 20, c = 30; arr_ptr[0] = &a; // 正确 arr_ptr[1] = &b; // 正确 arr_ptr[2] = &c; // 正确 // arr_ptr[0] = a; // 错误!类型不匹配 -
解引用:
-
arr_ptr[i]:获取数组中第i个指针元素的值(即它所指向的地址)。 -
*arr_ptr[i]:解引用数组中第i个指针元素,得到它所指向的值。
-
-
指针算术:
-
arr_ptr + 1:移动到下一个“指针元素”的起始地址。 -
arr_ptr[0] + 1:如果arr_ptr[0]指向一个数组的起始,则arr_ptr[0] + 1会移动到该数组的下一个元素。这通常用于char *arr[]存储字符串数组的场景。
-
示例代码:
#include <stdio.h>
int main() {
int num1 = 100, num2 = 200, num3 = 300;
int *arr_ptr[3]; // 声明一个指针数组,包含3个指向整型的指针
arr_ptr[0] = &num1;
arr_ptr[1] = &num2;
arr_ptr[2] = &num3;
printf("num1 的地址: %p, 值: %d\n", (void*)&num1, num1);
printf("num2 的地址: %p, 值: %d\n", (void*)&num2, num2);
printf("num3 的地址: %p, 值: %d\n", (void*)&num3, num3);
printf("----------------------------------------\n");
printf("arr_ptr 的地址: %p\n", (void*)arr_ptr); // 指针数组的起始地址
printf("arr_ptr + 1 的地址: %p (跳过 sizeof(int*) 字节)\n", (void*)(arr_ptr + 1));
printf("----------------------------------------\n");
printf("通过指针数组访问元素:\n");
for (int i = 0; i < 3; i++) {
printf("arr_ptr[%d] 的值 (地址): %p, *arr_ptr[%d] 的值: %d\n",
i, (void*)arr_ptr[i], i, *arr_ptr[i]);
}
printf("----------------------------------------\n");
// 字符串数组是典型的指针数组应用
char *names[3] = {"Alice", "Bob", "Charlie"};
printf("字符串数组示例:\n");
for (int i = 0; i < 3; i++) {
printf("names[%d]: %s\n", i, names[i]);
}
printf("----------------------------------------\n");
return 0;
}
运行结果(示例):
num1 的地址: 000000965F2FF874, 值: 100
num2 的地址: 000000965F2FF878, 值: 200
num3 的地址: 000000965F2FF87C, 值: 300
----------------------------------------
arr_ptr 的地址: 000000965F2FF850
arr_ptr + 1 的地址: 000000965F2FF858 (跳过 sizeof(int*) 字节) // 0x58 - 0x50 = 0x8 = 8 字节 (在64位系统上)
----------------------------------------
通过指针数组访问元素:
arr_ptr[0] 的值 (地址): 000000965F2FF874, *arr_ptr[0] 的值: 100
arr_ptr[1] 的值 (地址): 000000965F2FF878, *arr_ptr[1] 的值: 200
arr_ptr[2] 的值 (地址): 000000965F2FF87C, *arr_ptr[2] 的值: 300
----------------------------------------
字符串数组示例:
names[0]: Alice
names[1]: Bob
names[2]: Charlie
----------------------------------------
3. 大厂面试高频考点与深入分析
在大型科技公司的 C 语言面试中,数组指针和指针数组是考察面试者对 C 语言底层理解程度的利器。这些题目往往不只是简单地让你区分概念,而是要求你深入理解它们在内存中的表现、类型转换、函数传参时的行为,以及如何避免常见的陷阱。
3.1. 考点一:sizeof 和 strlen 的行为
这是一个经典的考察点,它要求你理解 sizeof 和 strlen 的作用以及它们处理数组名和指针时的区别。
-
sizeof:计算类型或变量所占的字节数。-
当作用于数组名时,
sizeof(arr)返回整个数组的总字节数。 -
当作用于指针时,
sizeof(ptr)返回指针变量本身所占的字节数(在 32 位系统上是 4 字节,64 位系统上是 8 字节),而不是它指向的数据的大小。
-
-
strlen:计算字符串的长度,直到遇到第一个\0字符为止。它只适用于以\0结尾的字符数组或字符串。
深入分析: 对于数组指针 int (*p)[5];,sizeof(p) 返回指针变量 p 的大小(4 或 8 字节),而 sizeof(*p) 返回 p 所指向的整个数组的大小(5 * sizeof(int) 字节)。 对于指针数组 int *arr_ptr[3];,sizeof(arr_ptr) 返回整个指针数组的大小(3 * sizeof(int*) 字节),而 sizeof(arr_ptr[0]) 返回数组中第一个指针元素的大小(即 int* 的大小,4 或 8 字节)。
3.2. 考点二:函数传参时的“降维”问题
C 语言中,数组作为函数参数传递时,会发生降维(decay)。这意味着:
-
一维数组作为参数传递时,会降维为指向其首元素的指针。
-
例如,
void func(int arr[])或void func(int *arr)都表示func接收一个int*类型的参数。
-
-
多维数组作为参数传递时,会降维为指向其第一维元素的指针。
-
例如,
void func(int arr[][5])或void func(int (*arr)[5])都表示func接收一个指向包含 5 个整型元素的数组的指针(即一个数组指针)。
-
深入分析: 面试官会通过让你编写或分析涉及数组作为参数的函数来考察你是否理解这种降维行为。关键在于,函数内部无法直接得知原始数组的完整大小,只能得知其降维后的指针类型的大小。
3.3. 考点三:复杂指针声明的解读
这是最常见的面试题之一,要求你能够准确地解析复杂的指针声明。掌握“近绑定”原则和从内到外(或从右到左,再结合括号)的解析顺序是关键。
解析方法:
-
找到变量名:确定哪个是变量名。
-
看最接近的修饰符:如果变量名最近的是
[],则它是一个数组;如果最近的是*,则它是一个指针。 -
看括号:括号可以改变优先级。
(*p)表示p是一个指针。 -
逐步解析:根据修饰符的类型和顺序,逐步确定变量的完整含义。
示例:
-
int *p[10];-
p首先与[10]结合,表明p是一个大小为 10 的数组。 -
*再与int结合,表明数组的每个元素都是int*类型。 -
结论:
p是一个包含 10 个指向整型的指针的数组(指针数组)。
-
-
int (*p)[10];-
p首先与*结合,因为有括号(),表明p是一个指针。 -
[10]再与int结合,表明这个指针指向一个包含 10 个int元素的数组。 -
结论:
p是一个指向包含 10 个整型元素的数组的指针(数组指针)。
-
-
int **p;-
p首先与最近的*结合,表明p是一个指针。
-
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









