



一、ui自动化测试介绍
1.什么是自动化测试?
概念:由程序代替人工进行系统校验的过程
2.自动化测试能解决的问题?
- 回归测试 (冒烟测试)
- 针对之前老的功能进行测试 通过自动化的代码来实现
- 针对上一个版本的问题的回归
- 兼容性测试 web实例化不同的浏览器驱动相当于对不同的浏览器进行操作,从而解决浏览器兼容性测试问题
- 性能测试 通过一些工具来模拟多个用户实现并发操作
- 提高工作效率,保障产品质量
3.自动化测试的优点
- 自动化测试能在较少的时间内执行给的的测试用例
- 自动化测试能够减少人为的错误
- 自动化测试能够克服手工的局限性
- 自动化测试可以重复执行(注册用户--已注册)
4.自动化测试的误区
- 自动化测试可以完全代替手工测试 针对某些功能(图片、页面架构)也是没有办法通过自动化来实现
- 自动化测试一定比手工测试厉害 金融行业更看重业务的积累
- 自动化测试可以发现更多的bug 是因为自动化测试主要用来做回归测试
- 自动化测试适用于所有的功能 页面的架构、图片、文字,用户体验无法适用
5.自动化测试分类
- web自动化测试 web系统
- 移动app自动化 app应用
- 接口自动化 接口:用来给web或者app前端传输数据用的
- 单元测试-自动化测试 针对开发人员的代码进行测试。是由开发自己来做的
- 安全测试(渗透测试) 针对系统、数据、应用等安全方面进行测试
- 桌面应用自动化测试 针对windows的桌面应用程序进行自动化测试
- 嵌入式自动化测试 针对嵌入式设备的应用程序进行自动化测试
6.什么是ui自动化测试?
概念 :ui(user interface)通过对web应用以及app应用进行自动化测试的过程
6.1什么项目适合做ui自动化测试?
- 需求变动不频繁 前端代码变更维护不方便
- 项目周期长 项目短,上线之后不需要再去测试
- 项目需要回归测试 不用回归测试的也不需要写自动化
6.2ui自动化测试是在什么阶段开始的》
- 手工测试完成之后才做自动化测试,相当于是编写自动化测试代码(通过手工测试能够清楚的知道自动化测试的步骤以及结果)
6.3UI自动化测试所属分类
- 黑盒测试(功能测试) UI自动化测试 模拟人工对web以及app页面进行操作的过程
- 白盒测试(单元测试)
- 灰盒测试(接口测试)
1、v1版本 通过手工测试完成之后,有十个功能。
2、针对v1版本的十个功能,进行自动化的代码编写
3、 v2 版本增加了十个功能(总共20个功能),v2版本的测试过程当中,新增的10个功能手工测试。针对老的10个功能就可以通过自动化来进行回归测试。
二、web自动化测试基础
1、web自动化框架
1.1主流的web自动化工具
selenium 主要用来做web自动化测试的,开源的免费的工具
1.2selenium特点
selenium中文名是硒,就是用来做web自动化测试的
- 开源软件:源代码开放,但不一定免费
- 跨平台:平台指操作系统。linux、windows、mac操作系统
- 支持多种浏览器:firefox、chrome、ie、edge、opera、safari
- 支持多语言:python\java\c#\Ruby\PHP
- 成熟稳定功能强大:被大公司使用。google、华为、百度、腾讯
后续大家在选择自动化工具的时候,这几个特点就是选择工具的依据。
2、环境搭建
2.1 selenium工作原理
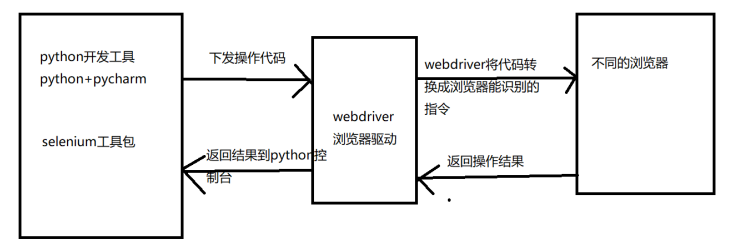
3、selenium环境安装
3.1python开发工具安装(python和pycharm)
3.2浏览器安装(浏览器电脑安装)
需要注意浏览器驱动的版本,不同浏览器有不同的浏览器驱动,而且不同的版本也有不同的浏览器驱动
3.3selenium工具包安装
- 在线安装方式:在dos命令行中输入:pip install selenium
- 离线安装方式:
- 需要获取selenium离线安装包并解压
- 在dos命令行进入到解压的目录,然后执行python setup.py install
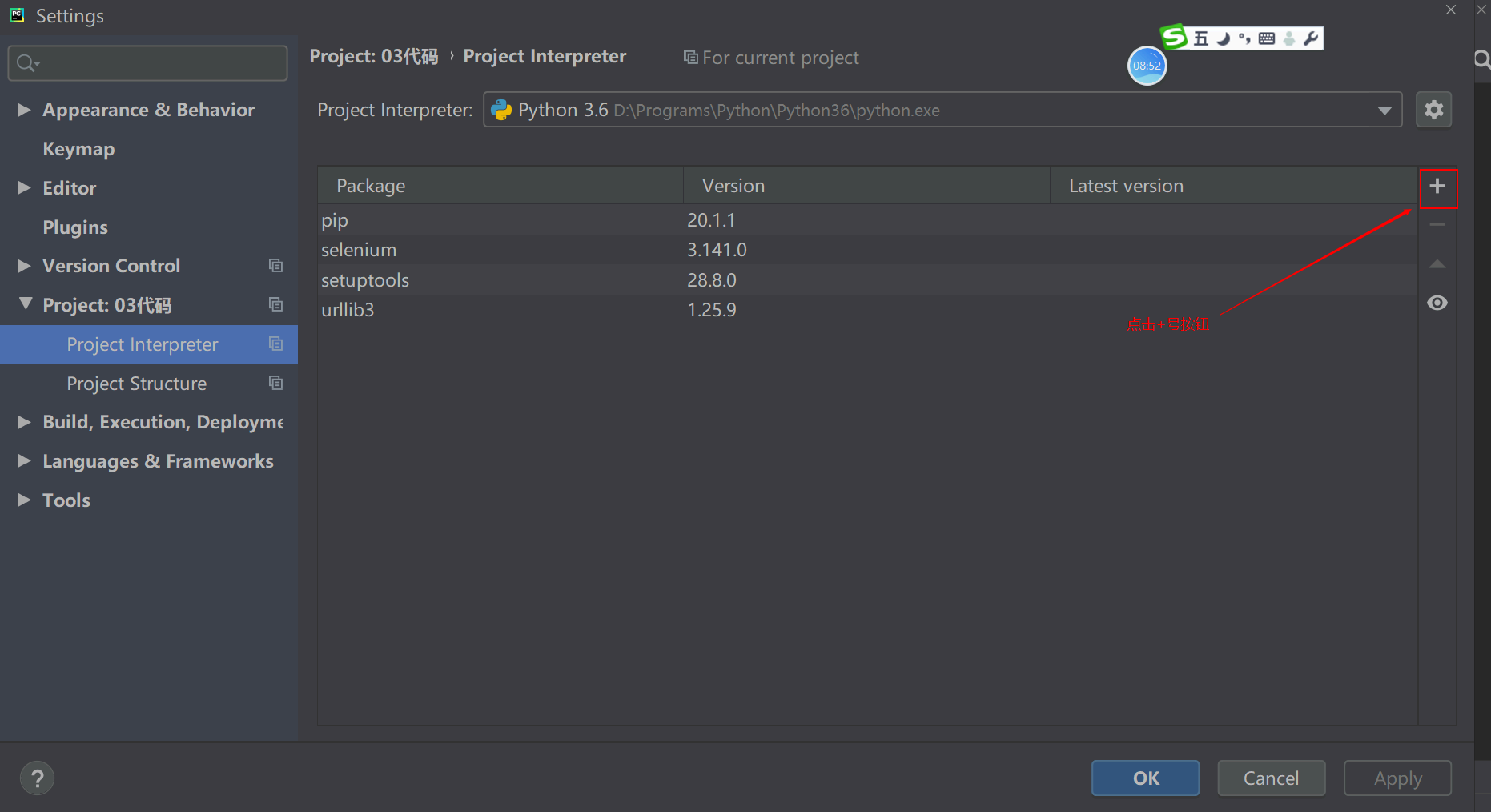
- pycharm进行安装
- 在file(文件)菜单中选择setting(设置),然后选择“projecr-interpreter”
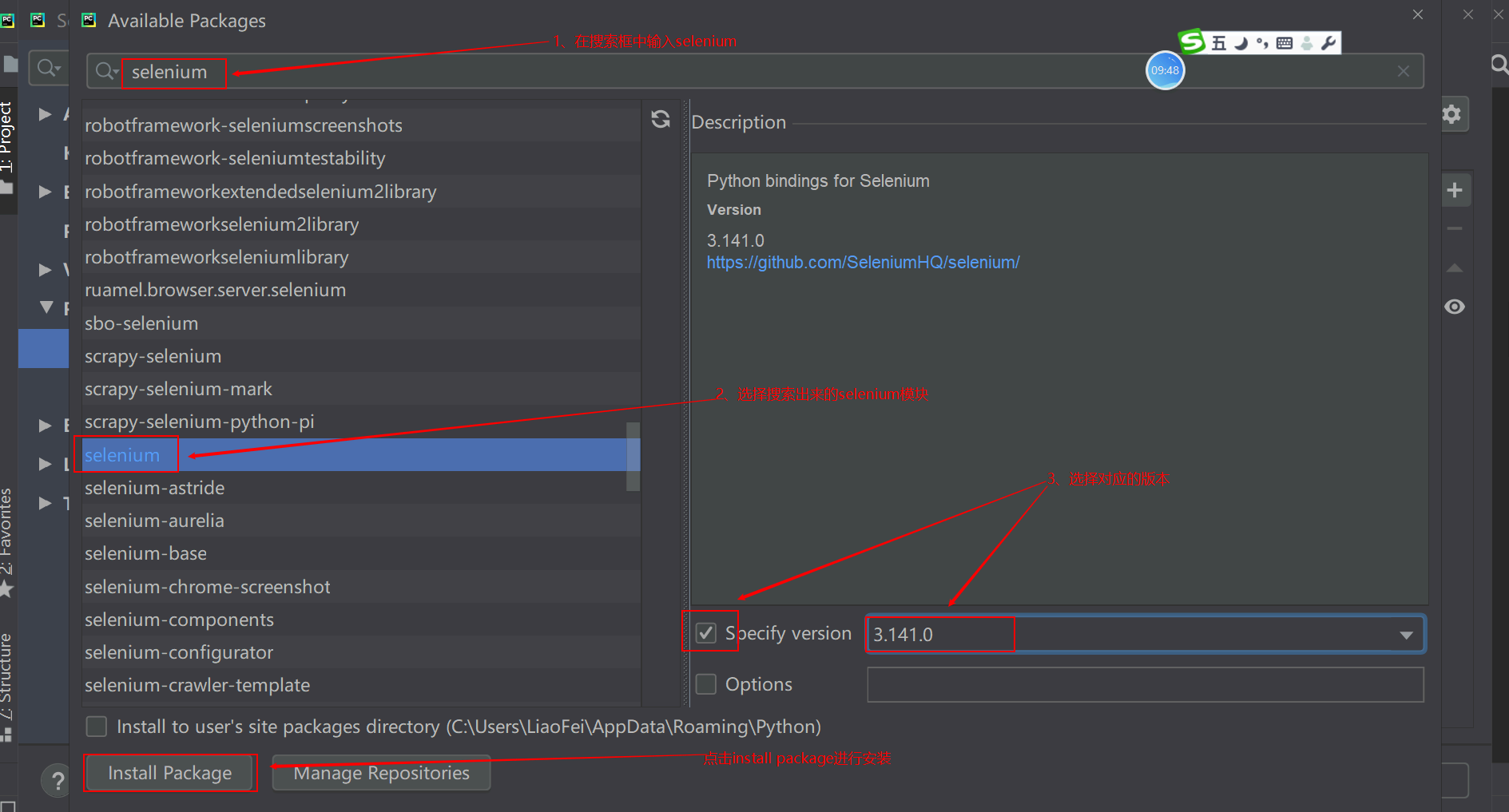
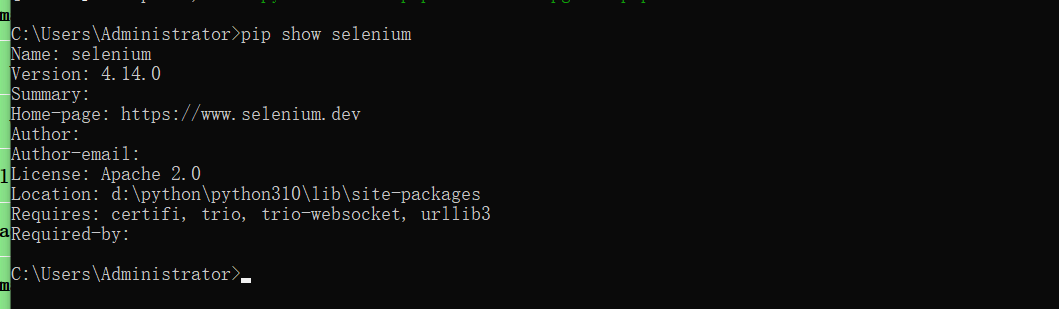
如何确认selenium安装完成:可以通过pip show selenium进行查看
3.4浏览器驱动安装
- 安装浏览器驱动之前,一定要知道自己浏览器的版本
- 通过https://npm.taobao.org/mirrors/chromedriver/ 获取对应的浏览器驱动
- 通过https://googlechromelabs.github.io/chrome-for-testing/ 下载最新的谷歌浏览器驱动
- 解压浏览器驱动文件,并将驱动文件复制到python的根目录就行了。
3.5入门示例(浏览器直接驱动)
- 项目创建
- 项目名称不要与第三方模块同名
- 文件名也不要与第三方的模块名或者是类名同名
- 项目创建时不要使用虚拟环境
import time
from selenium import webdriver
# 实例化浏览器驱动对象(创建浏览器驱动对象)
driver = webdriver.Chrome() # 创建的是谷歌浏览器驱动对象 chrome后面有括号,而且第一个字母要大写
# driver = webdriver.Firefox() # 创建火狐浏览器驱动对象
# 打开百度网站
driver.get("http://www.baidu.com")
# 等待3s(代表业务操作)
time.sleep(3) # 通过快捷导包的方式导入time模块, 光标要在time后面再按alt+enter
# 退出浏览器驱动(释放系统资源)
driver.quit()
3.6在项目中添加浏览器驱动(3.4下载)
根目录下的driver
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 第一步 先创建一个浏览器驱动对象
driver_path='../driver/chromedriver.exe' #注意路径
service=Service(executable_path=driver_path) #创建服务对象
driver = webdriver.Chrome(service= service) #创建浏览器驱动对象
print(driver.service.path)#获取驱动器的路径
# 2 打开测试的网页
driver.get("http://localhost:8081/regA.html")
# 3 对浏览器进行操作, 比如输入值, 点击等操作
driver.find_element(By.TAG_NAME,"input").send_keys("dzyxA")
# 4 关闭浏览器驱动对象
time.sleep(10)
driver.quit()
三、元素定位
1.如何进行元素定位?
元素:由标签头+标签尾+标签头和标签尾包括的文本内容< >
元素的信息就是指元素的标签名以及元素的属性
元素的层级结构就是指元素之间相互嵌套的层级结构
元素定位最终就是通过元素的信息或者元素的层级结构来进行元素定位。
2.浏览器开发者工具介绍
- 浏览器开发者工具主要用来查看元素的信息,同时也可以查看接口的相关信息。
- 浏览器开发者工具不需要安装,浏览器自带
- 浏览器开发者工具的启动
- 直接按F12不区分浏览器
- 通过右键的方式来启动浏览器开发者工具(谷歌浏览器右键选择“检查”,火狐浏览器右键选择“检查元素”)
- 浏览器开发者工具使用
- 点击浏览器开发者工具左上角的 元素查看器按钮
- 再点击想要查看的元素
3.元素定位
- id定位
- name定位
- class_name定位
- tag_name定位
- partail_link_text定位
- xpath定位
- css定位
| 选择器名称 | 使用方法 |
| id | driver.find_elements(By.ID,"id") |
| name | driver.find_elements(By.NAME,”name") |
| class name | driver.find_elements(By.CLASS_NAME,"class_name") |
| tag name | driver.find_elements(By.TAG_NAME,"tag_name") |
| partail link text | driver.find_elements(By.LINK_TEXT,"link_text") |
|
xpath | driver.find_elements(By.XPATH,"xpath") |
| css selector | driver.find_elements(By.CSS_SELECTOR,"css_selector") |
| driver.find_elements(By,) |
3.1步骤
- 打开谷歌浏览器或者edge浏览器
- 输入url
- 找元素及操作
- 关闭浏览器
使用浏览器驱动,第一次打开速度较慢,因为浏览器网站都在外国
import time
from selenium import webdriver
# 第一步 先创建一个浏览器驱动对象
driver = webdriver.Chrome()
# 2 打开测试的网页
driver.get("https://www.baidu.com/")
# print(driver.service.path) # 打印驱动的绝对路径
# 3 对浏览器进行操作, 比如输入值, 点击等操作
# 略操作,
# 4 关闭浏览器驱动对象
time.sleep(10)
driver.quit()
使用本地驱动(本篇文章3.6)
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 第一步 先创建一个浏览器驱动对象
driver_path='../driver/chromedriver.exe' #注意路径
service=Service(executable_path=driver_path) #创建服务对象
driver = webdriver.Chrome(service= service) #创建浏览器驱动对象
print(driver.service.path)#获取驱动器的路径
# 2 打开测试的网页
driver.get("http://localhost:8081/regA.html")
# 3 对浏览器进行操作, 比如输入值, 点击等操作
driver.find_element(By.TAG_NAME,"input").send_keys("dzyxA")
# 4 关闭浏览器驱动对象
time.sleep(10)
driver.quit()
3.2ID定位
- 通过元素的ID属性来进行元素定位,在html标准规范中ID值是唯一的。
- 说明:元素要有ID属性
- 定位方法:driver.find_elements(By.ID,"id") #id参数表示的是id的属性值
- 前置:标签必须由id属性
- 输入方法:元素.send_keys("内容")
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# 第一步 先创建一个浏览器驱动对象
driver = webdriver.Chrome()
# 2 打开测试的网页
driver.get("http://localhost:8081/regA.html")
# 3 对浏览器进行操作, 比如输入值, 点击等操作
#id定位 用户名
driver.find_element(By.ID,"userA").send_keys("admin")
# 密码
driver.find_element(By.ID,"passwordA").send_keys('123456')
# 手机号码
driver.find_element(By.ID,"telA").send_keys('15515631249')
# 4 关闭浏览器驱动对象
time.sleep(10)
driver.quit()
3.3name定位
- 通过元素的name属性值为进行元素定位,name属性值在HTML页面中,特点:时可以重复的。
- 前置:元素要有name属性
- 定位方法:driver.find_elements(By.NAME,“name") #name参数表示的是name的属性值
- 提示:由于name属性值可以重复,所以使用时需要查看是否为唯一
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# 第一步 先创建一个浏览器驱动对象
driver = webdriver.Chrome()
# 2 打开测试的网页
driver.get("http://localhost:8081/regA.html")
# 3 对浏览器进行操作, 比如输入值, 点击等操作
#id定位 用户名 输入值
#name定位 在页面中,name的属性在input输入框(表单)这个元素是唯一的,其它的元素这个属性可以不唯一
driver.find_element(By.NAME,"userA").send_keys("admin")
# 4 关闭浏览器驱动对象
time.sleep(10)
driver.quit()
3.4class_name定位
- 通过元素的class属性值进行定位 class属性值是可重复的
- 说明:元素必须要有class属性
- 定位方法:driver.find_elements(By.CLASS_NAME,"class_name") #class_name参数表示的是class的其中一个属性值
- 说明:如果标签由多个class值,使用任何一个都可以。
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# 第一步 先创建一个浏览器驱动对象
driver = webdriver.Chrome()
# 2 打开测试的网页
driver.get("http://localhost:8081/regA.html")
#class_name 定位 html里面 类属性 页面内不唯一 在我们后面很少用
#class_name 如果有多个值,只选择其中一个
#因为 class_name重复值,只定位第一个
#如果你给的定位值,在页面不唯一,只定位第一个元素
driver.find_element(By.CLASS_NAME,"telA").send_keys("123456789")
#邮箱
# 4 关闭浏览器驱动对象
time.sleep(10)
driver.quit()
3.5 tag_name定位
- 通过元素的标签名称进行定位,在同一个html页面当中,相同标签元素会有很多。这种定位元素的方式不建议大家在工作中使用。
- 定位方法:driver.find_elements(By.TAG_NAME,"tag_name")
- 提示:如果有重复的元素,定位道德元素默认都是第一个元素
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
# 第一步 先创建一个浏览器驱动对象
driver = webdriver.Chrome()
# 2 打开测试的网页
driver.get("http://localhost:8081/regA.html")
# tag_name 按照元素标签名进行定位 页面重复太多,所以工作中不用
# driver.find_element(By.TAG_NAME,"input").send_keys("dzyxA")
#邮箱
# 4 关闭浏览器驱动对象
time.sleep(10)
driver.quit()
3.6link_text定位
- 说明:根据链接文本(a标签)定位
- 定位方法:driver.find_elements(By.LINK_TEXT,"link_text") #link_text是标签文本
- 特点:link_text为传入的链接文本,必须全部匹配,不能模糊匹配
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 第一步 先创建一个浏览器驱动对象
driver_path='../driver/chromedriver.exe' #注意路径
service=Service(executable_path=driver_path)
driver = webdriver.Chrome(service= service)
print(driver.service.path)
# 2 打开测试的网页
driver.get("http://localhost:8081/regA.html")
#link_text 通过连接(a标签)文本进行定位 全匹配 必须跟文本值一摸一样
#.click() 点击------->元素自己点击自己
driver.find_element(By.LINK_TEXT,"新浪").click()
# 4 关闭浏览器驱动对象
time.sleep(10)
driver.quit()
3.7 partail_link_text定位
- 说明:根据链接文本(a标签)定位
- 定位方法:driver.find_elements(By.LINK_TEXT,"link_text") #link_text是局部文字
- 特点:传入的链接文本,支持模糊匹配(传入局部文字)
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
# 第一步 先创建一个浏览器驱动对象
driver_path='../driver/chromedriver.exe' #注意路径
service=Service(executable_path=driver_path)
driver = webdriver.Chrome(service= service)
print(driver.service.path)
# 2 打开测试的网页
driver.get("http://localhost:8081/regA.html")
#partial_link_text 通过连接(a标签)文本进行定位 模糊匹配 like “%新%”
# 元素的重复率太高了,工作中,不怎么使用
#.click() 点击------->元素自己点击自己
driver.find_element(By.PARTIAL_LINK_TEXT,"新浪").click()
# 4 关闭浏览器驱动对象
time.sleep(10)
driver.quit()
3.8拓展定位一组元素
- 说明:返回列表格式,要使用需要添加下表或遍历
- 定位一组元素的方法:element加s
drive.find_elements(BY. )
- 八大元素定位方法,都可以使用一组元素定位,如果没有搜索到符合标签,返回空列表。
- 定位一组元素返回的值是一个列表
- 可以通过 下标来使用列表中的元素
- 下标是从0开始


















 1869
1869

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









