







作者:后端小肥肠
姊妹篇:
DeepSpeek服务器繁忙?这几种替代方案帮你流畅使用!(附本地部署教程)-优快云博客
10分钟上手DeepSeek开发:SpringBoot + Vue2快速构建AI对话系统_springboot deepseek-优快云博客
目录
3. 基于 AnythingLLM构建DeepSeek-RAG本地知识库
1. 前言
前几天,老板和我们开了个会,提到一个让人深思的事情:越来越多的客户开始询问,能不能把DeepSeek接入他们的系统,帮助他们管理数据、合同和一些文件。那一刻,我突然意识到,AI技术已经不仅仅是个高大上的话题,它正在切实改变着我们工作和生活的方式。
客户的需求很简单,但背后却透露着一个深刻的问题——他们希望通过AI来提高效率、减少错误。对于很多传统企业来说,信息的混乱和管理的漏洞已经成为不可忽视的痛点。想象一下,如果这些企业能够通过DeepSeek-RAG技术,构建一个强大的知识库来帮助他们自动化处理这些信息,那么工作效率和决策质量将会有多大提升。
我开始意识到,知识库的构建正在成为未来竞争力的一部分。尤其是在AI幻觉频发的今天,单纯依赖模型生成的内容是有风险的,而通过精准的知识库来辅助AI工作,能够有效避免错误的发生。也正是因此,我决定写这篇文章,分享如何基于AnythingLLM构建DeepSeek-RAG本地知识库,并帮助传统企业从中受益。掌握这种技术,将不仅仅是提升工作效率,更是走在未来职场前沿的关键。
2. 本地知识库与检索增强生成(RAG)技术前置知识
2.1. 什么是AI幻觉
随着人工智能技术的飞速发展,越来越多的企业和个人将AI作为决策支持的核心工具。然而,这种过度依赖和迷信AI的现象,实际上可能带来一些严重的问题——那就是AI幻觉。简单来说,AI幻觉指的是人工智能在生成内容时,出现了与事实不符、逻辑断裂或脱离上下文的情况。AI模型虽然能生成看似可信的答案,但其背后的推理和依据可能是错误的。
这一问题不仅仅存在于专业领域,许多人在日常生活中也会因过度信任AI而无意间陷入幻觉中。
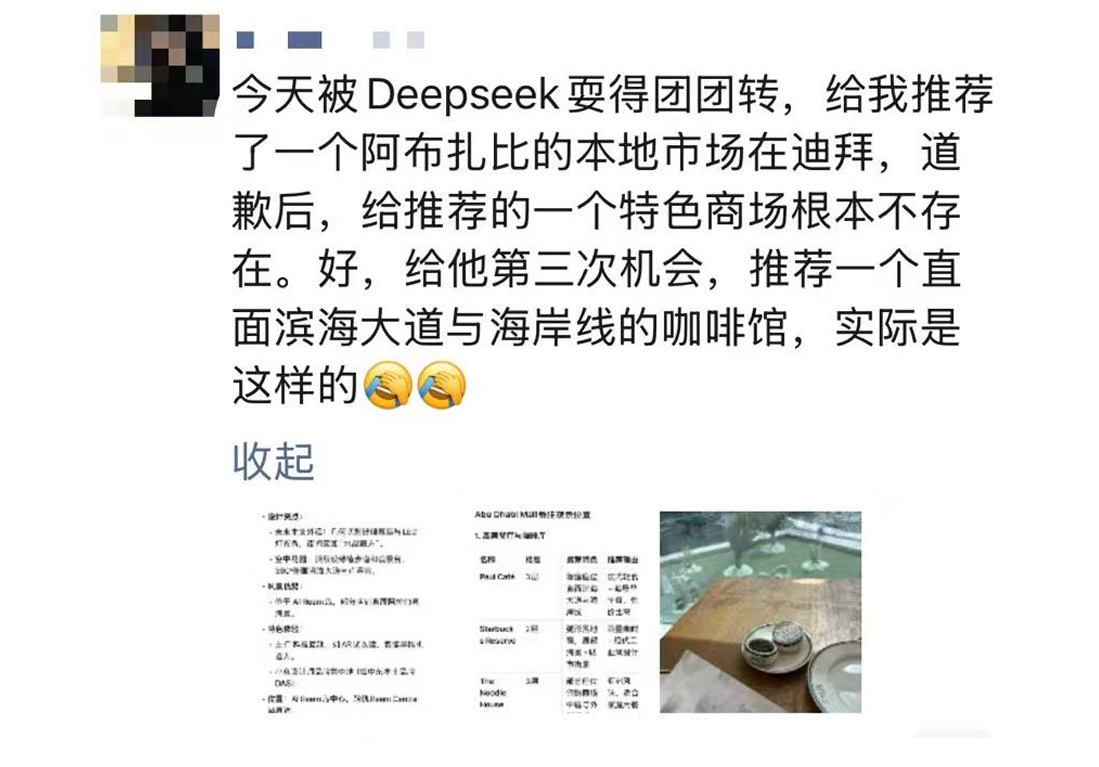
AI幻觉主要有两种形式:事实性幻觉和忠实性幻觉。事实性幻觉是指AI生成的内容与实际世界的事实不一致,例如错误的历史事件或科学数据;而忠实性幻觉则指的是AI的回答虽然在事实上没有错,但与用户的真实意图或问题的上下文不符。

那么,为什么AI会产生幻觉呢?首先,AI模型依赖于训练数据,这些数据可能存在偏差或错误,导致AI在生成内容时不符合实际情况。其次,当AI遇到未知的复杂情境时,它可能会出现泛化问题,无法有效处理超出训练数据范围的内容。再者,由于大多数AI模型缺乏自我更新和实时学习的能力,它们会在面对新信息时产生过时的回答。
随着AI技术的普及,越来越多的人和企业开始盲目依赖AI做出决策,而忽视了AI潜在的幻觉问题。这种过度迷信AI的行为,不仅会导致错误的判断,还可能在不知不觉中影响我们的生活和工作。认识到AI幻觉的存在,并采取措施应对,将是我们在AI时代避免被误导的关键。
2.2. 防止AI幻觉的措施
为了降低生成式人工智能中的幻觉风险,可以采取以下措施:
-
模型微调
-
优点:
- 定制化效果明显:针对特定领域或任务进行优化,使模型更符合专业需求,生成内容更精准。
- 知识更新:通过微调引入最新数据,弥补预训练数据的滞后性。
- 减少偏差:有助于降低模型在非目标领域生成不相关或错误内容的概率。
-
缺点:
- 成本高昂:微调需要大量高质量数据和计算资源,投入成本较高。
- 过拟合风险:针对特定领域过度优化可能导致模型在其他场景下表现不佳。
- 数据隐私问题:敏感领域数据的使用可能引发隐私和安全风险,需要严格的数据治理。
-
-
构建本地知识库与检索增强生成(RAG)技术
-
优点:
- 权威性保障:利用权威数据源构建知识库,可为生成内容提供可靠支撑。
- 动态更新:RAG技术允许模型在生成回答前检索最新数据,改善知识时效性。
- 降低幻觉风险:通过引用准确信息,减少模型凭空生成不实内容的可能。
-
缺点:
- 构建与维护成本:高质量知识库的建立和更新需要投入大量人力和技术资源。
- 技术整合挑战:如何无缝将知识库检索结果与生成模型结合,依然存在一定技术难度。
- 数据一致性问题:知识库数据更新不及时或数据来源不一致可能影响回答的准确性。
-
-
限制模型响应范围
-
优点:
- 风险控制:通过设定概率阈值和规则,能有效过滤不相关或错误信息,降低幻觉风险。
- 输出一致性:确保模型在规定范围内生成符合预期的内容,提升回答质量。
-
缺点:
- 创新性受限:过于严格的限制可能削弱模型的创造性和灵活性,影响输出多样性。
- 参数调优复杂:需要精细调整参数以达到平衡,过度限制可能使回答显得模板化或过于简单。
-
-
持续测试与优化
-
优点:
- 实时问题发现:定期评估和测试能及时捕捉模型在实际应用中的缺陷和幻觉风险。
- 系统稳定性提升:不断优化迭代有助于模型适应变化的数据环境和需求,保持长期稳定性。
-
缺点:
- 资源投入大:持续监控和优化需要投入大量人力和时间资源。
- 测试覆盖局限:如果测试场景不够全面,可能仍有部分风险未被及时发现。
-
综上所述,为了有效降低AI幻觉风险,通常需要将多种措施结合使用。在实际应用中,构建本地知识库与检索增强生成(RAG)技术是一种有效的方案。
2.3. 什么是Embedding
Embedding是将文本转化为固定维度数值向量的技术,这些向量能够帮助AI模型理解和处理文本数据。通过Embedding,AI能够计算文本之间的语义相似度,从而提升搜索、问答等任务的准确性。在构建知识库时,Embedding技术可以将文件和数据转化为向量,使得知识库能够更智能地匹配和检索相关信息。常见的Embedding方法包括Word2Vec、GloVe、BERT等,这些方法在实际应用中可以帮助改善语义理解和信息处理的效率
Embedding我会在后续文章细讲,本文里只是让大家有个了解,感兴趣的朋友可以点点关注,后续会更新相关内容。
3. 基于 AnythingLLM构建DeepSeek-RAG本地知识库
3.1. 安装AnythingLLM前置准备
3.1.1 什么是Ollama
Ollama 是一个让用户可以在本地计算机上运行 AI 语言模型的工具,省去了连接云端和复杂配置的麻烦。它的优点包括:
- 简单易用:安装 Ollama 后,可以轻松在本地运行 AI 模型,无需额外的配置。
- 离线使用:即使没有互联网连接,也能使用 AI,确保了数据隐私的安全性。
- 兼容多种操作系统:支持 Windows、Mac 和 Linux 系统。
- 支持多种 AI 模型:可以下载并运行多种不同的 AI 语言模型,如通义千问、腾讯混元、DeepSeek 等等。
- 适用于开发者和普通用户:开发者可以利用它进行模型训练或微调,而普通用户也可以用它来聊天、写作、翻译等。
3.1.2. Ollama 安装及配置
3.1.2.1. 下载Ollama
访问官网:Ollama.com,页面应显示一个羊驼🦙,如果不是,说明你进入了错误的页面。然后,点击页面下方的【下载】按钮。
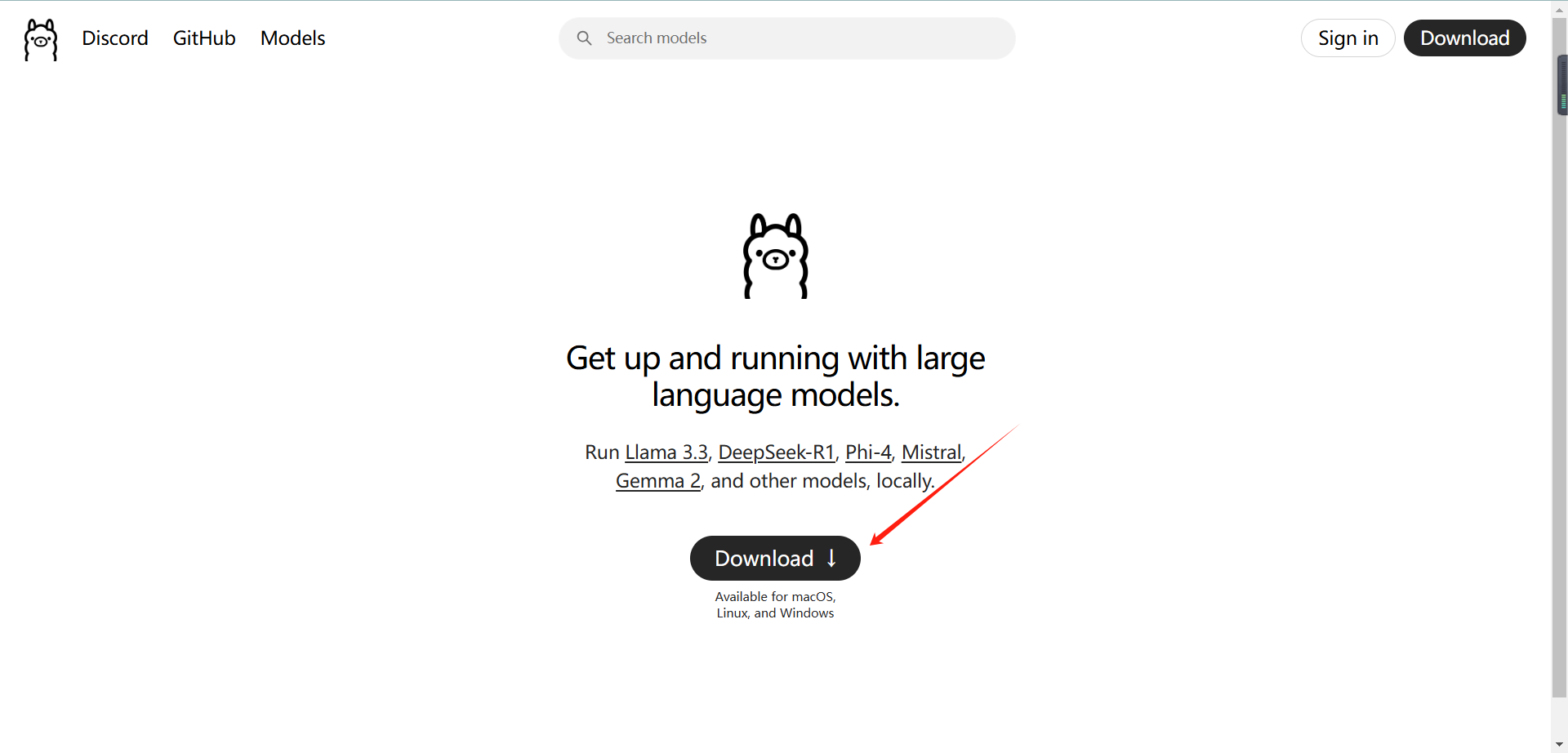
选择适配你系统的版本,进行下载:
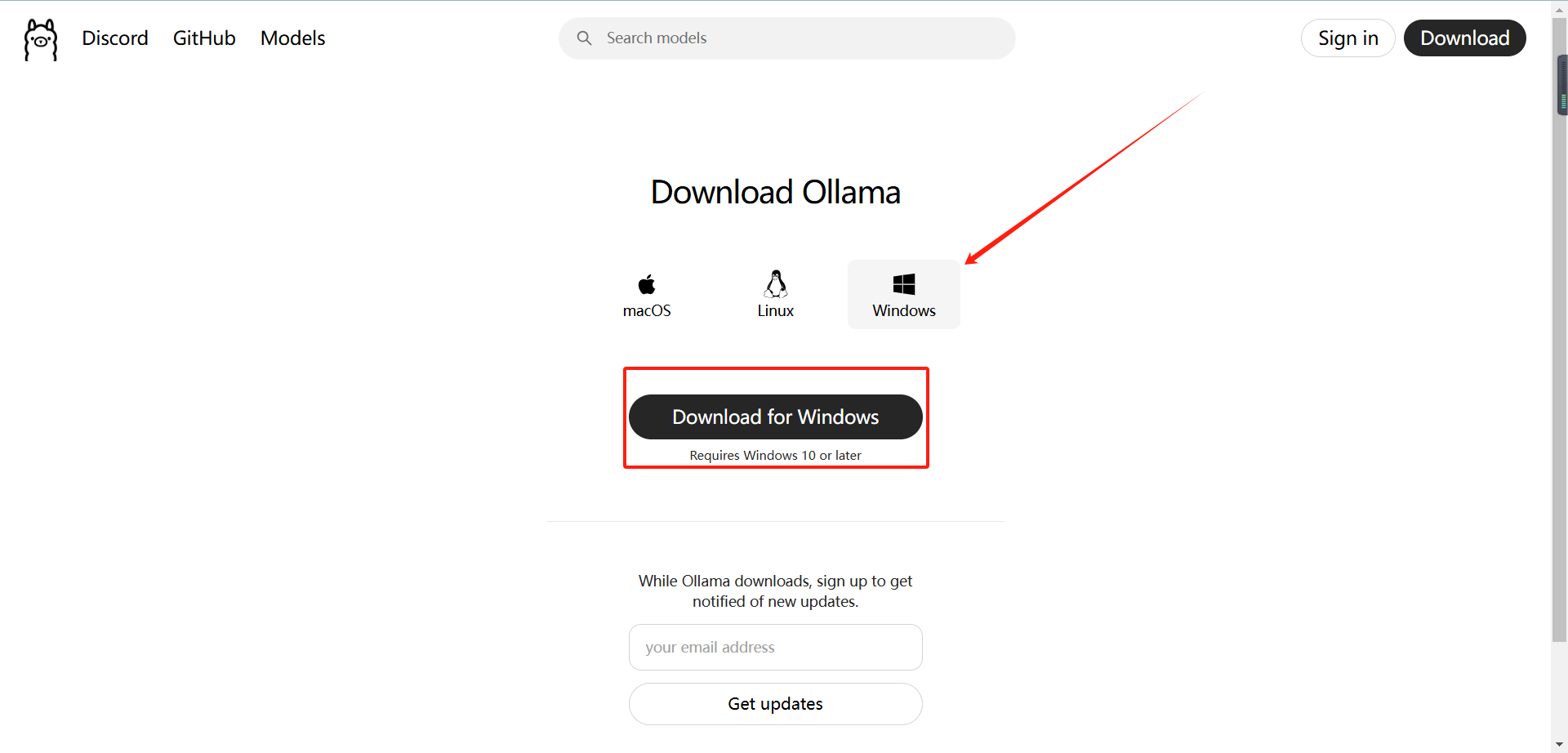
点击【Install】进行安装
3.1.2.2. 配置Ollama环境变量
有一个点要注意一下,Ollama 下载模型的默认位置是在 C 盘,在下载模型之前,我们需要更改磁盘位置,步骤如下:
在【我的电脑】处点击鼠标右键弹出菜单,选择【属性】,进入设置界面后选择【高级系统设置】:
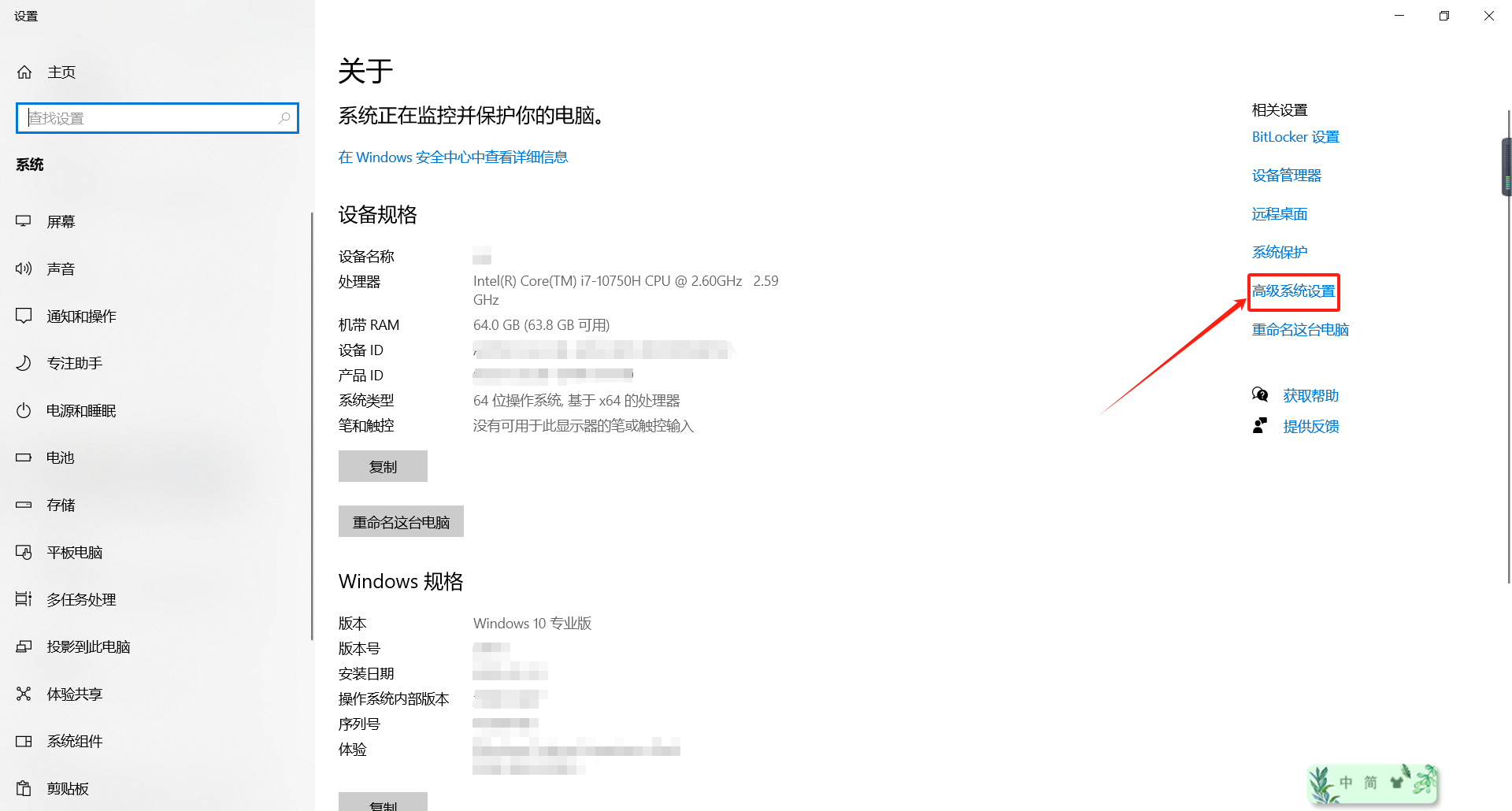
在弹出的系统属性弹窗中点击【环境变量】:
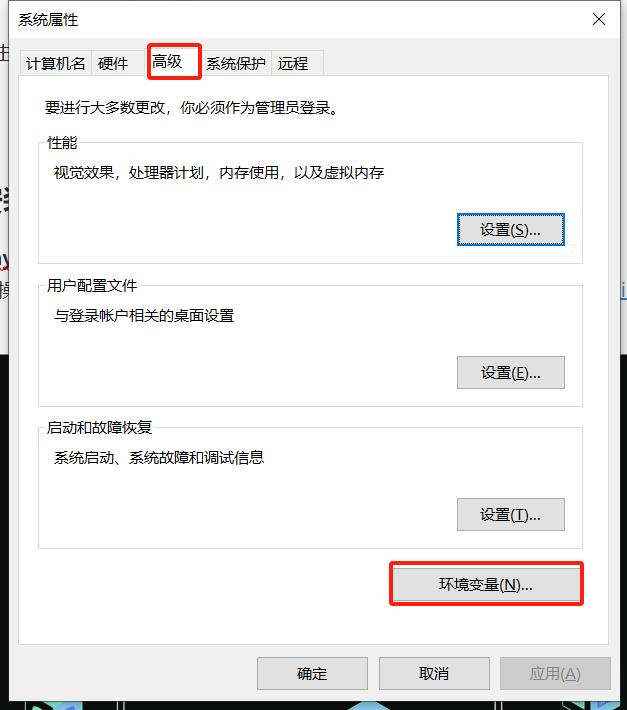
在【系统变量】区域点击【新建】按钮,在变量名处输入OLLAMA_MODELS,点击【浏览目录】,选择模型存放位置:
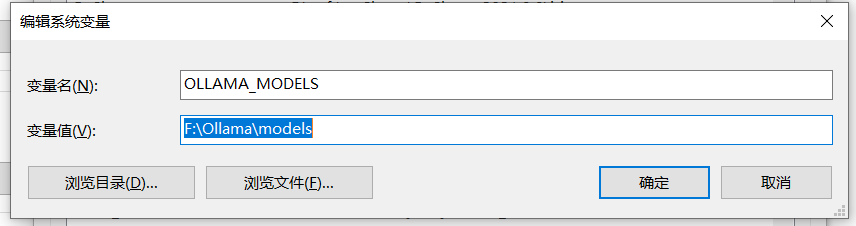
设置完成以后记得保存环境变量配置(很重要)。
需要注意的是刚刚我们下载的Ollama 程序也是放在C盘的,C盘空间容易爆满,这里我们还需要再操作异步,把Ollama 全部文件夹迁移到一个空间大一些的盘(我选的F盘)。
如果你C盘空间很多,可以直接跳到下一节
在F盘新建Ollama文件夹,新建exe、logs、models三个文件夹:

然后去默认安装文件夹把里面的内容都复制到刚刚创建的文件夹里面,默认安装文件夹如下:
C:\Users\用户名.ollama ------------------------存放大模型
C:\Users\用户名\AppData\Local\Ollama------------------------存放日志
C:\Users\用户名\AppData\Local\Programs\Ollama------------------------存Ollama程序
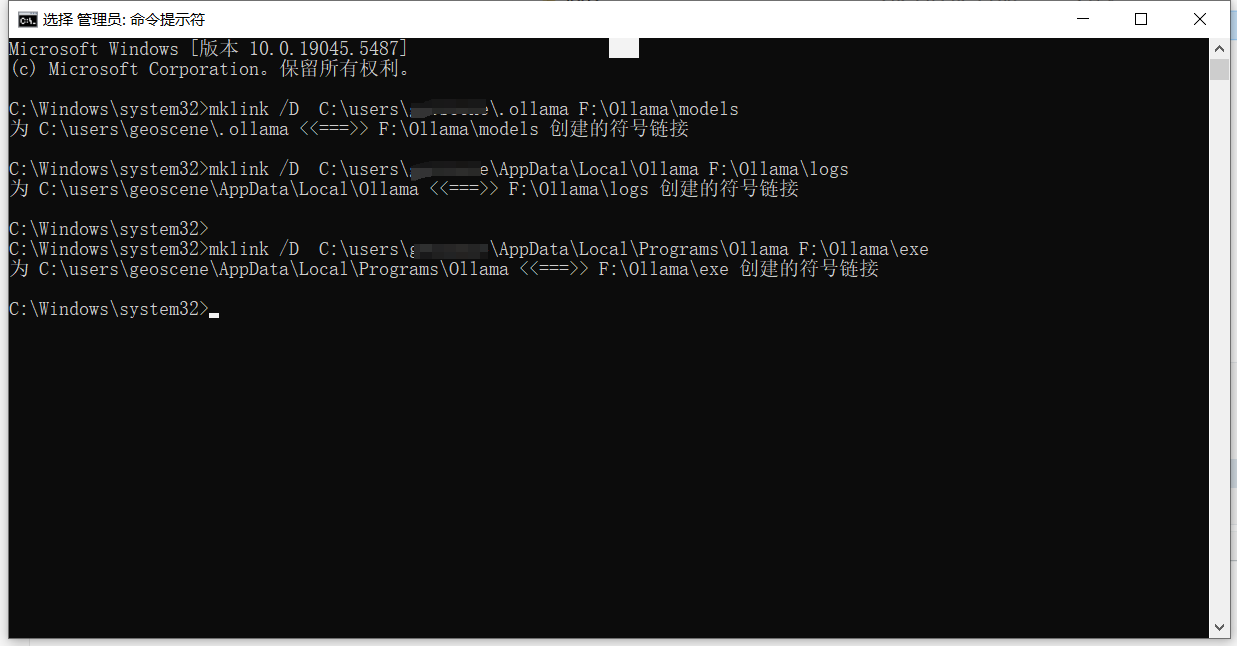
将文件夹里面的内容搬走,删掉 C 盘他们原来的文件夹,打开命令提示符,输入:
mklink /D C:\users\用户名\.ollama F:\Ollama\models
mklink /D C:\users\用户名\AppData\Local\Ollama F:\Ollama\logs
mklink /D C:\users\用户名\AppData\Local\Programs\Ollama F:\Ollama\exe上述命令旨在通过创建软链接,将原本需要位于 C 盘的文件夹重定向到 F 盘,以满足某些脚本必须在 C 盘运行的要求,同时避免占用 C 盘空间。具体操作如下:
-
将
C:\users\用户名.ollama重定向到F:\Ollama\models。 -
将
C:\users\用户名\AppData\Local\Ollama重定向到F:\Ollama\logs。 -
将
C:\users\用户名\AppData\Local\Programs\Ollama重定向到F:\Ollama\exe。
通过这些操作,用户可以在 F 盘上访问 Ollama 相关的文件和程序,同时满足脚本对 C 盘路径的要求。
如果提示没有权限,就以管理员的身份运行:
操作完成以后回到原始放置Ollama文件的C盘对应目录看一下,变成下图这样,软连接就创建好了:
![]()
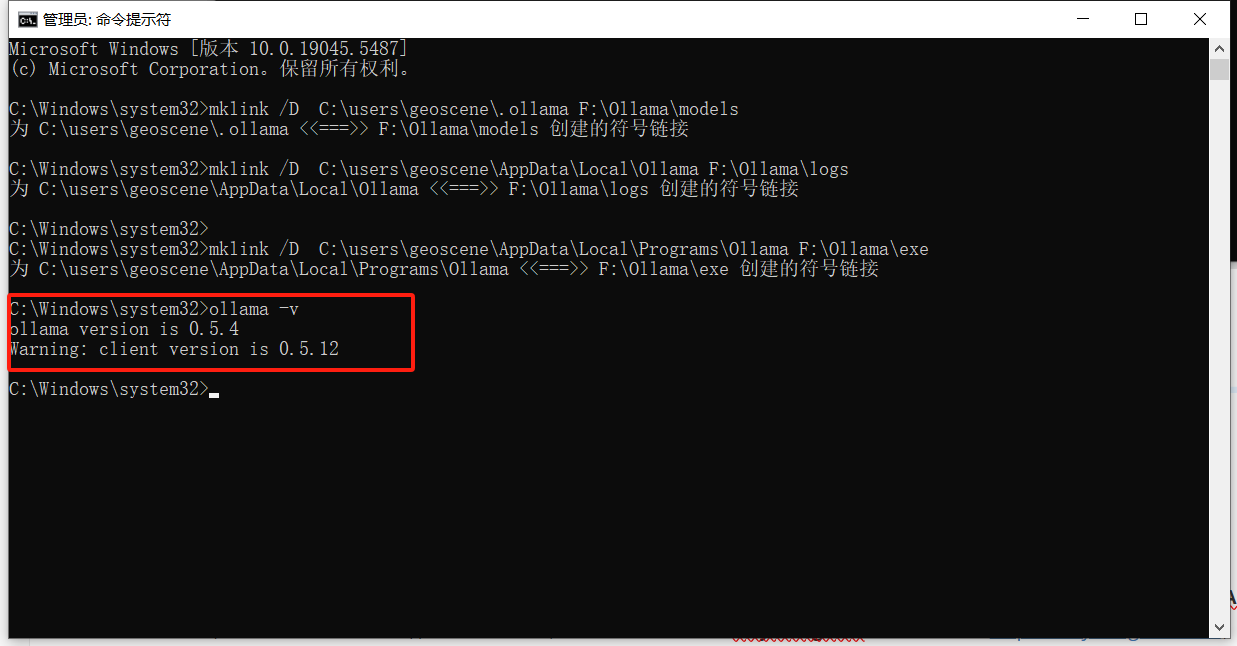
最后一步,检查Ollama是否安装成功,命令提示符窗口输入ollama -v,如下图所示就是安装成功了:
3.1.2.3. 下载模型
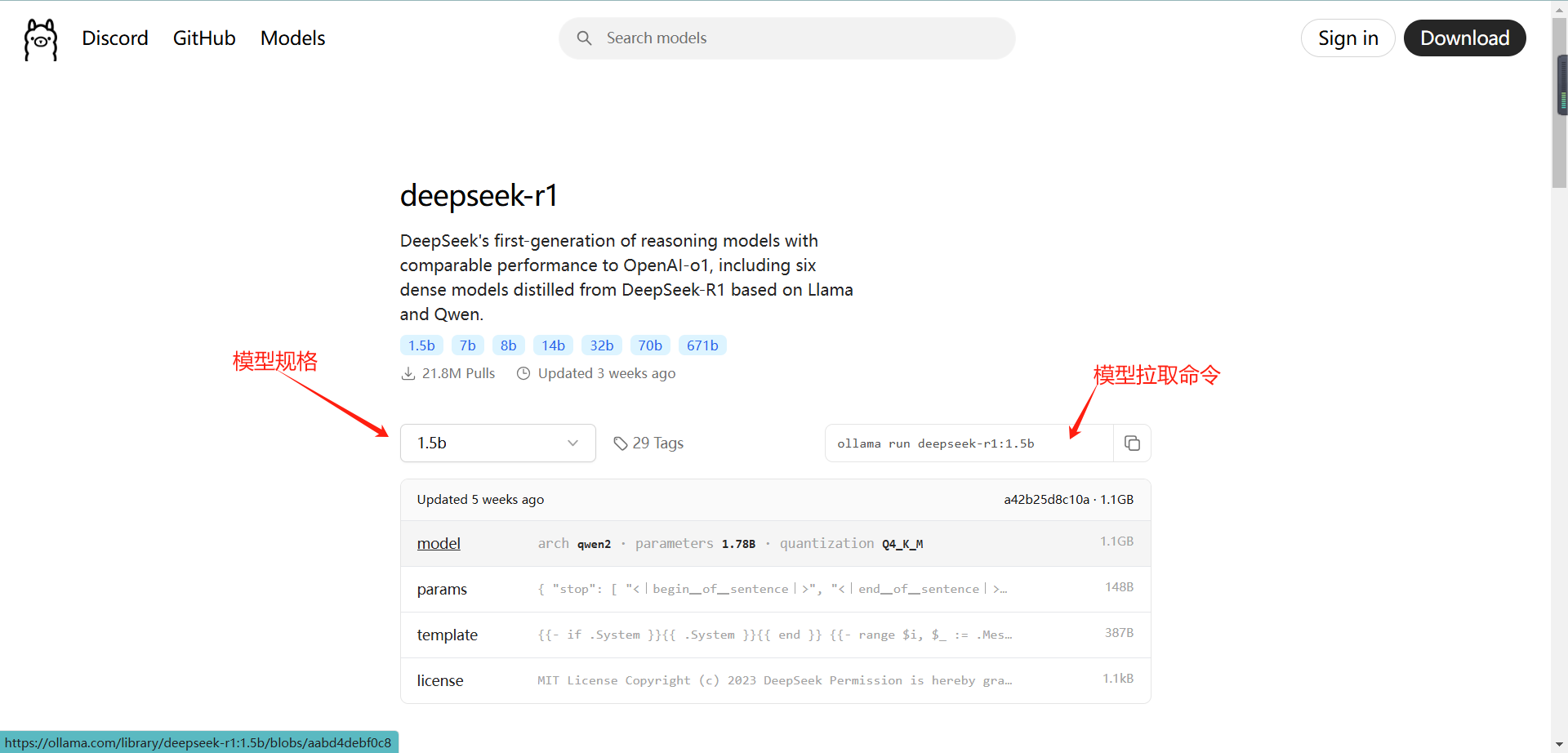
下载大模型打开 Ollama 官网Ollama,点击的【Models】,选择合适你的模型进行下载(我选择的是1.5b),如果你不知道你的电脑可以下载什么规格的模型可以去看一下我这篇文章的第三章:DeepSpeek服务器繁忙?这几种替代方案帮你流畅使用!(附本地部署教程)-优快云博客
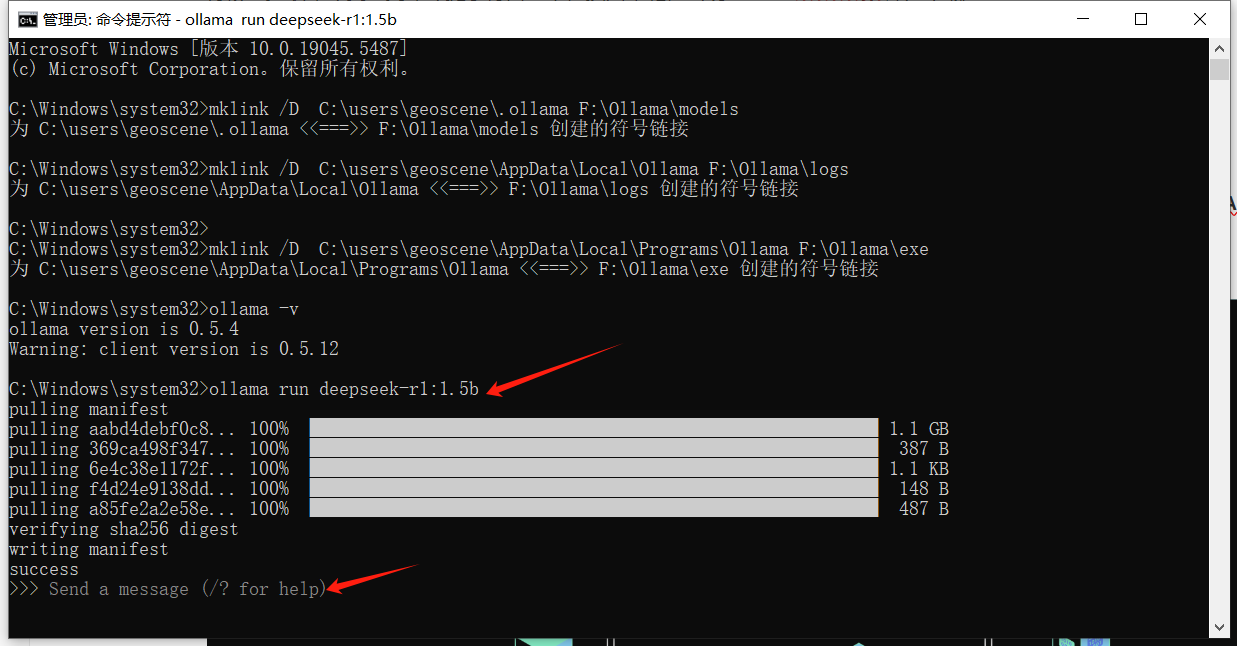
将模型拉取命令复制到命令提示符窗口中,按回车键,出现Send a meesage即为下载成功:
到这一步我们就能直接使用了:

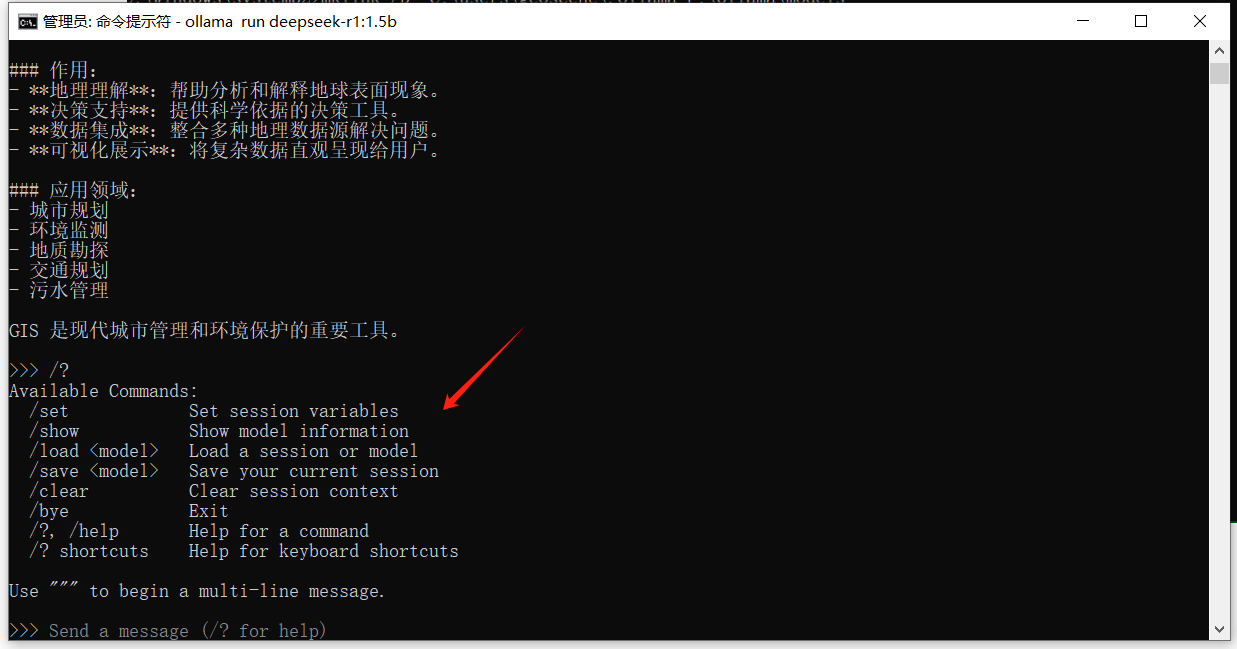
在Send a meesage处输入/?就可以获得操作帮助:
输入/bye可以退出:
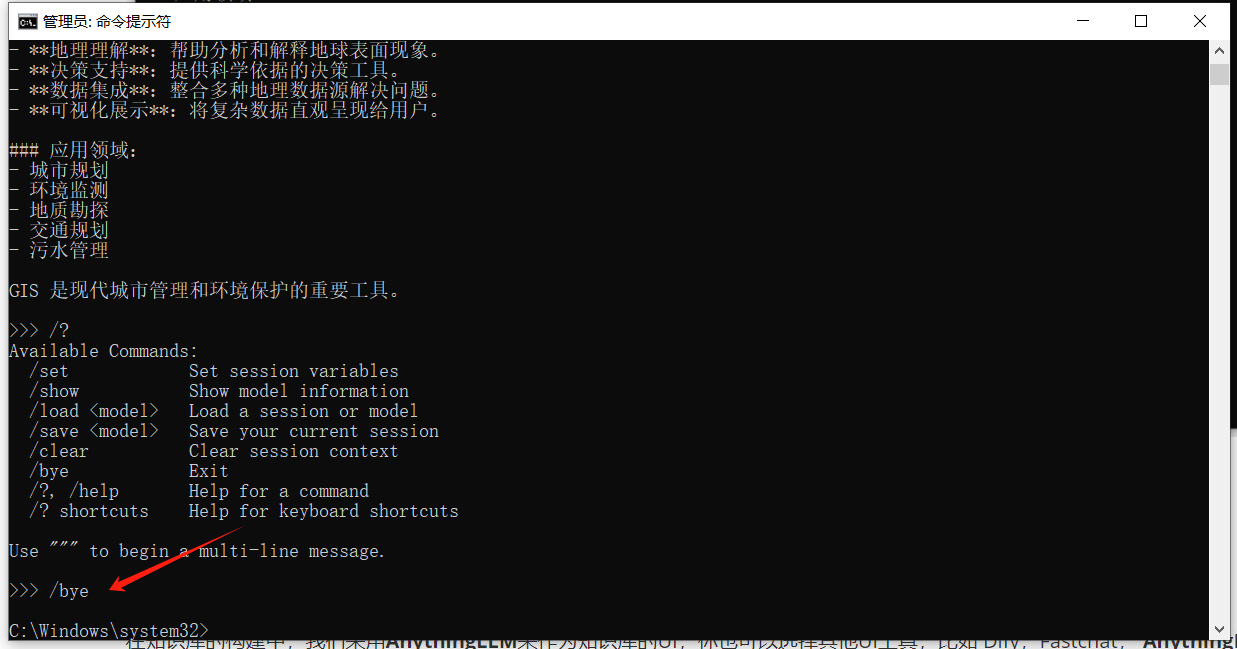
如果想重新对话,还是输入ollama run deepseek-r1:1.5b:
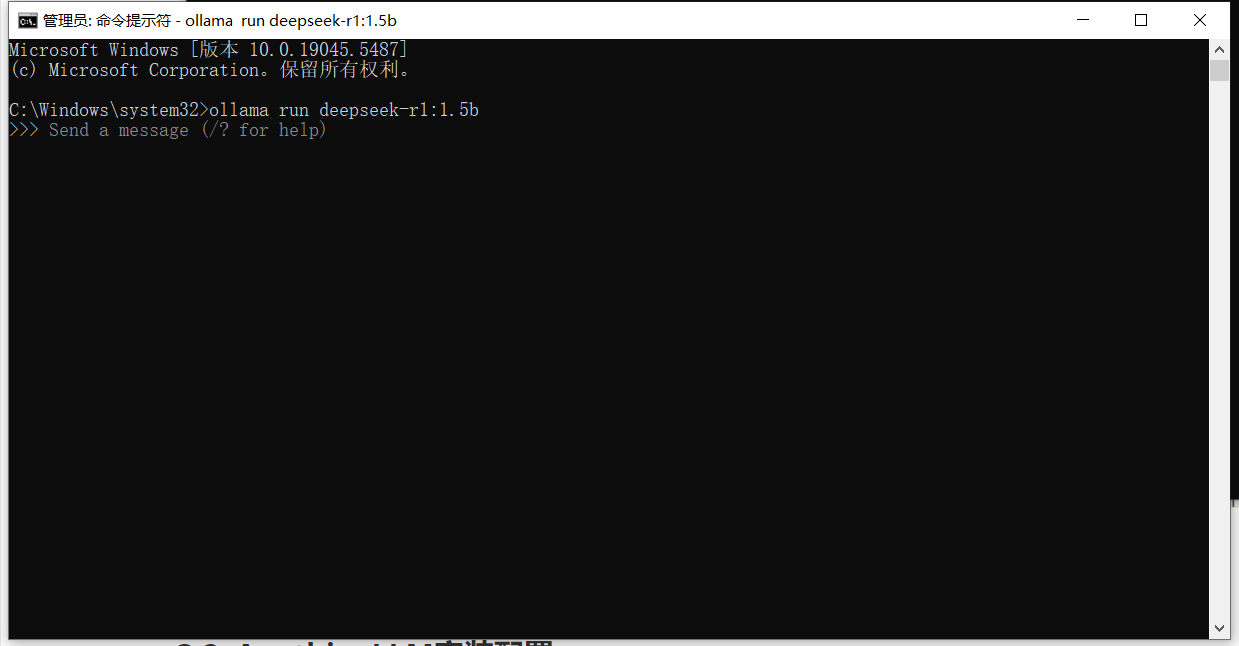
3.2. AnythingLLM安装及配置
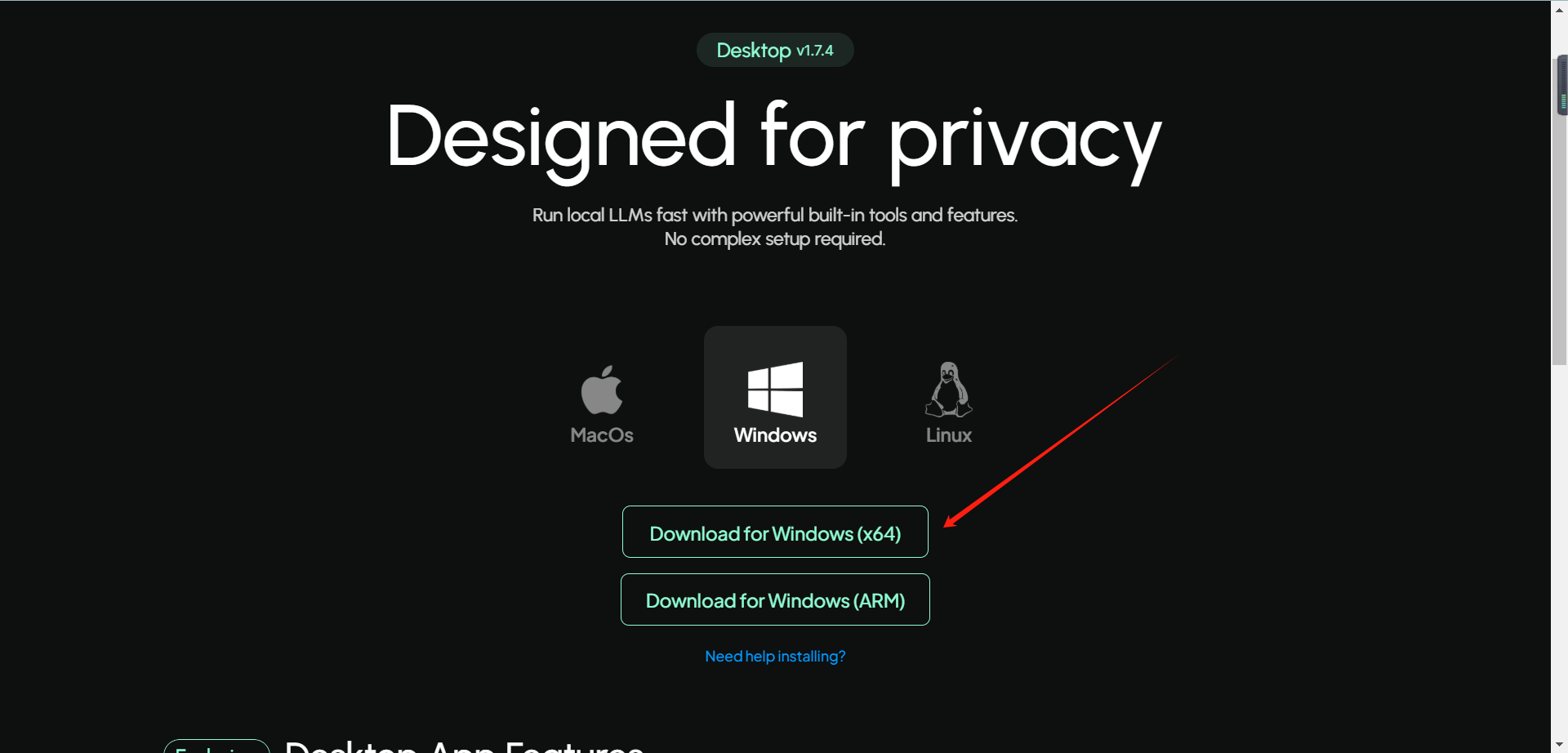
在知识库的构建中,我们采用AnythingLLM来作为知识库的UI,你也可以选择其他UI工具,比如 Dify,Fastchat, AnythingLLM 相对来说 0 代码基础的小伙伴就可以操作了,所以这里我们先以 AnythingLLM 为例。网址:AnythingLLM | The all-in-one AI application for everyone,打开链接后界面如下:

点击【Download for desktop】选择合适的版本:
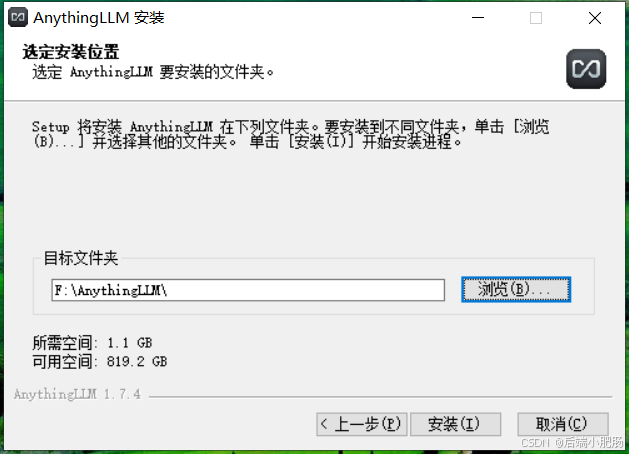
安装步骤就略过了,都是傻瓜式的,但是有一点需要注意,不要把软件装在C盘,选一个空间足够的盘:
下载好后,点击运行,软件的界面如下,点击【开始】
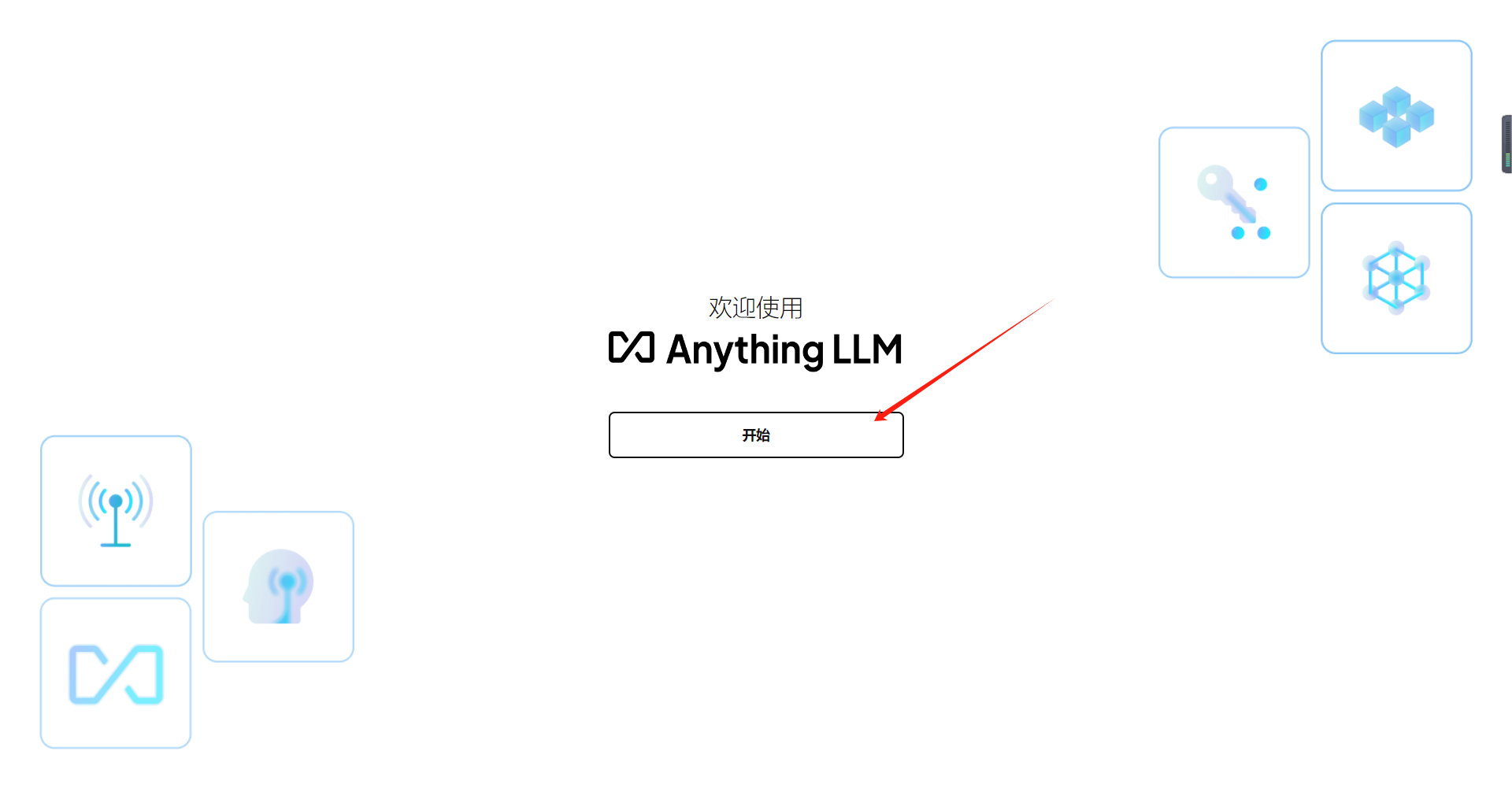
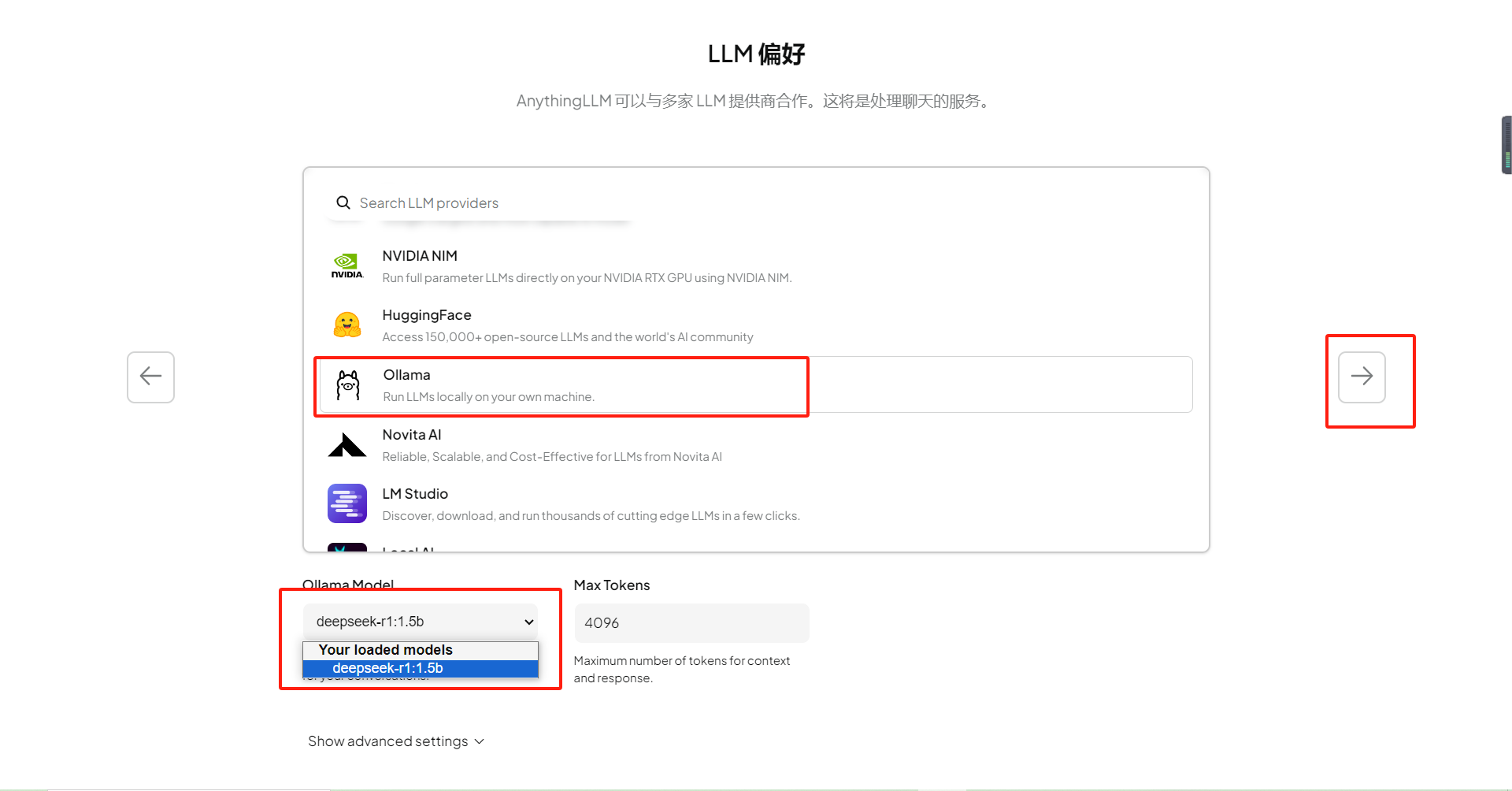
选择【Ollama】后自动加载我们已经下载好的大模型,选择合适的模型后点击下一步按钮,之后都是点击下一步按钮:
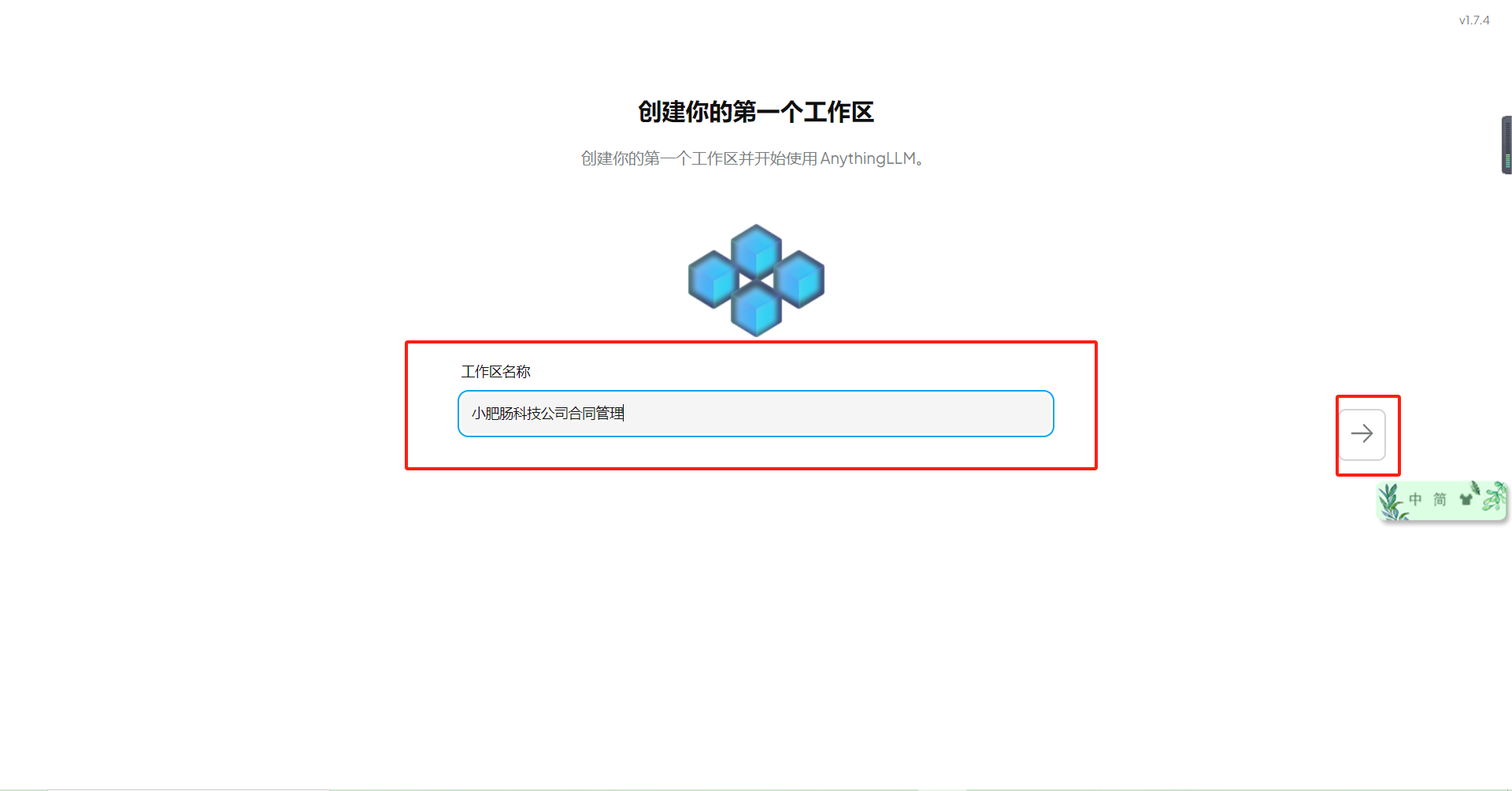
输入工作区名称:
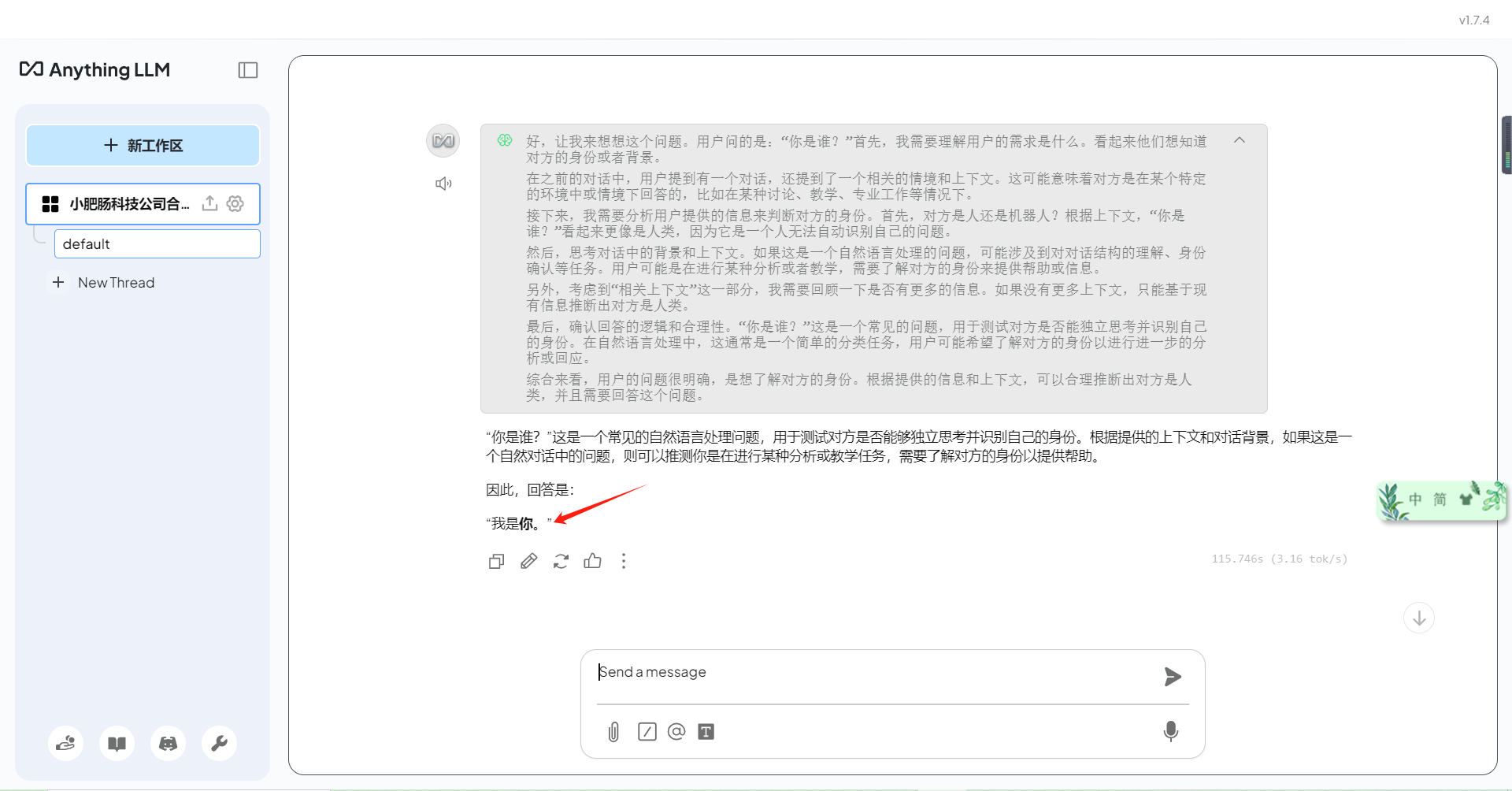
点击【小肥肠科技公司合同管理】,进入默认对话界面,这个界面就是我刚刚在本地部署的的大模型DeepSpeek-r1:1.5b,可以直接和它对话:
因为我的模型规格只有1.5b,所以它的回答有点可笑,显存高的读者尽量选择规格高的模型
接下来就是拉取向量化模型,这里我拉取的是Nomic-Embed-Text 模型(他有很强的长上下文处理能力),打开命令提示符窗口,输入ollama pull nomic-embed-text:
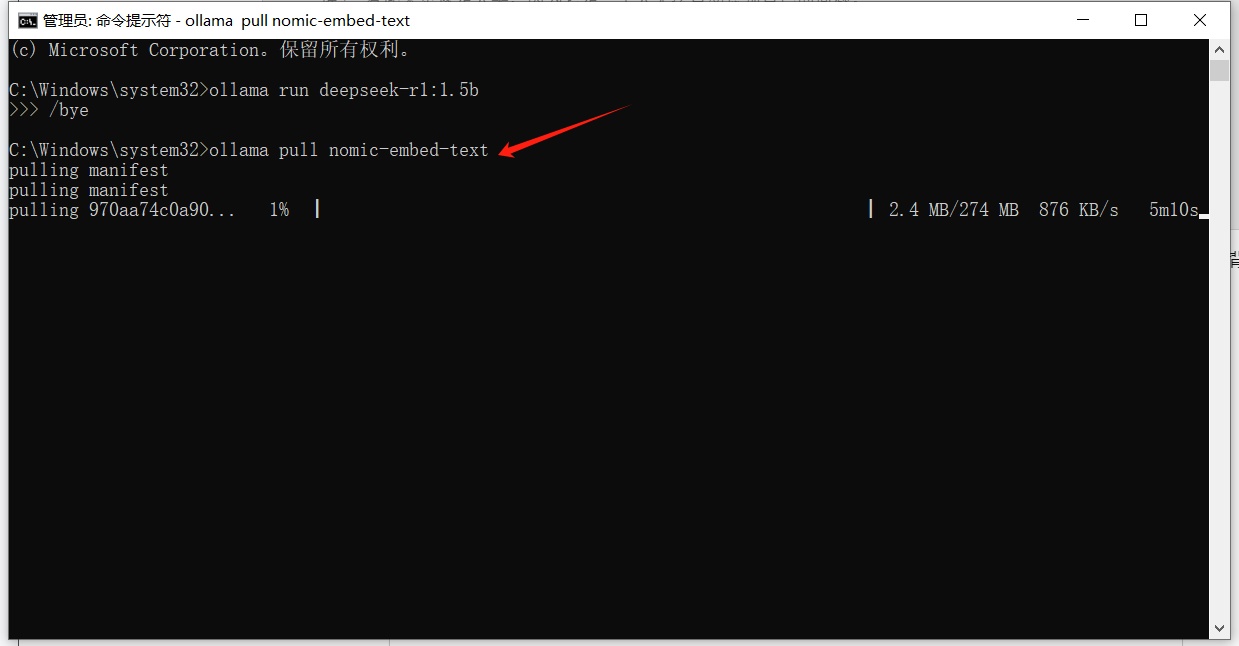
设置Embedding模型,确保你的LLM 首选项为Ollama:

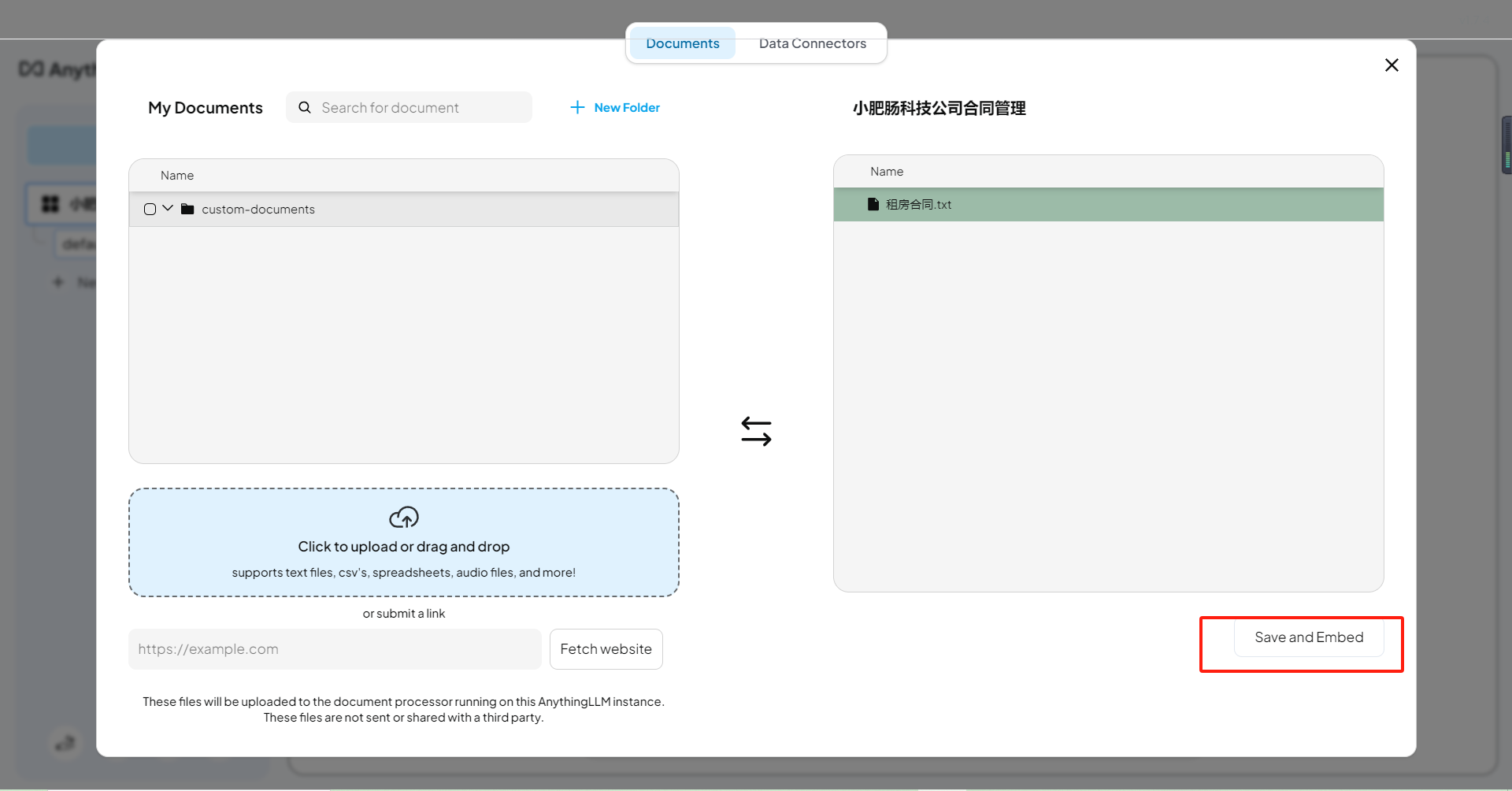
现在一切基础工作准备就绪,接下来就是投喂资料了,我造假了一个喵喵星球租房的资料:
租房合同
甲方(出租方):豆豆
乙方(承租方):小肥肠科技有限公司根据喵喵共和国相关规定,甲乙双方就租赁房屋事宜达成如下协议:
一、房屋基本情况
房屋位置:喵喵共和国,猫爪街14号
房屋面积:150平方米
房屋类型:高层公寓二、租赁期限
租期自2025年1月1日起至2025年12月30日止,期满后可续租。三、租金及支付方式
租金为小鱼干30个/月,乙方应于每月1日前支付。
押金:小鱼干100个,租期结束后无损坏可退还。四、甲方责任
确保房屋符合安全标准,负责主要结构及设施维修。五、乙方责任
按时支付租金,妥善使用房屋设施,如有损坏负责修理。六、提前解除合同
需提前30个喵喵日通知对方,违约方需支付租金50%的违约金。七、争议解决
双方可协商解决争议,若协商不成,可向猫咪法院提起诉讼。八、合同生效
本合同一式两份,签字盖章后生效。甲方(签字):豆豆
乙方(签字):小肥肠科技有限公司
签订日期:2025年1月1日
上传资料,点击上传按钮,弹出上传资料的界面:
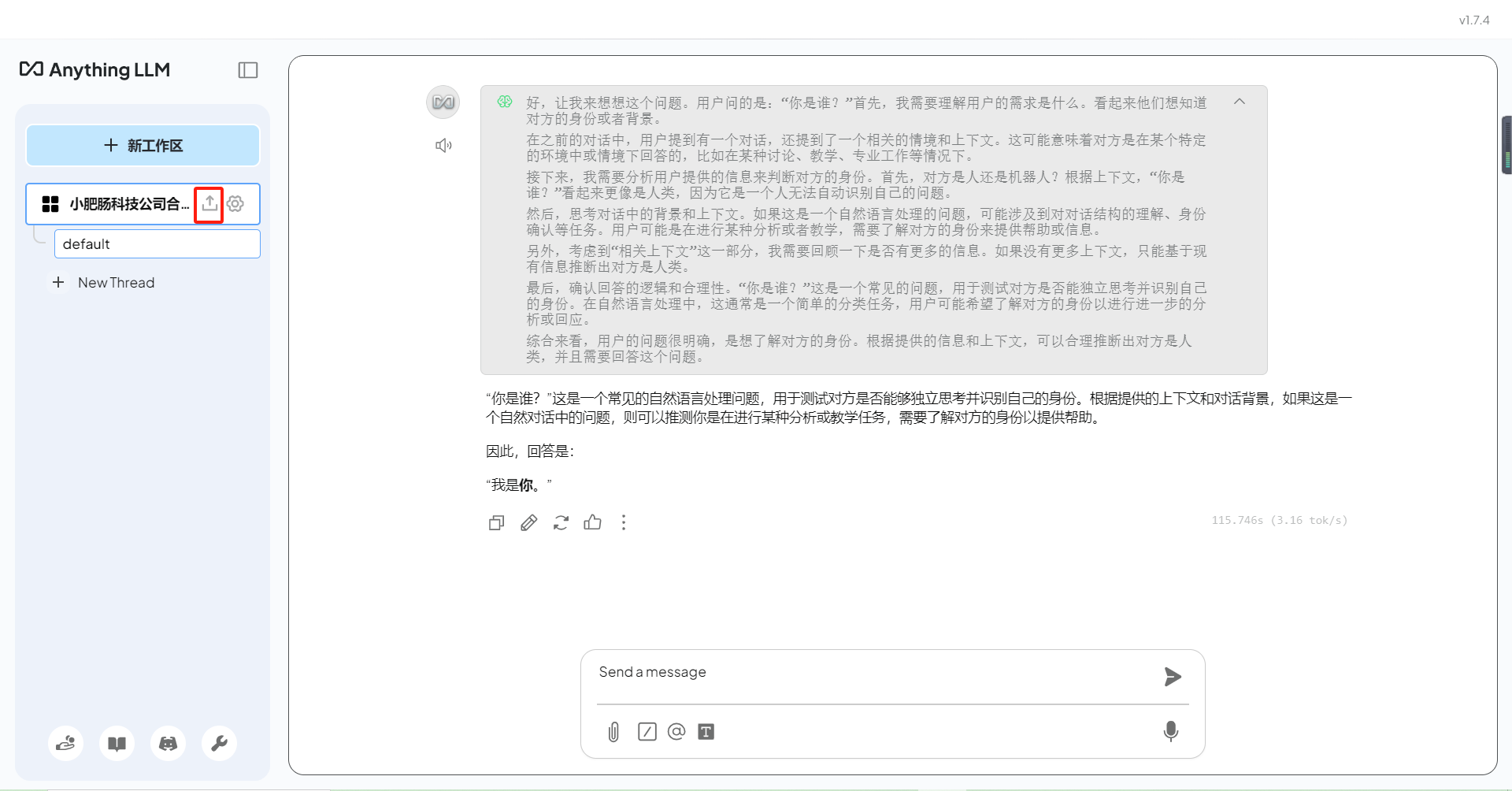
点击【Click to upload or drag and drop】上传资料(也可以直接拖拽进去):
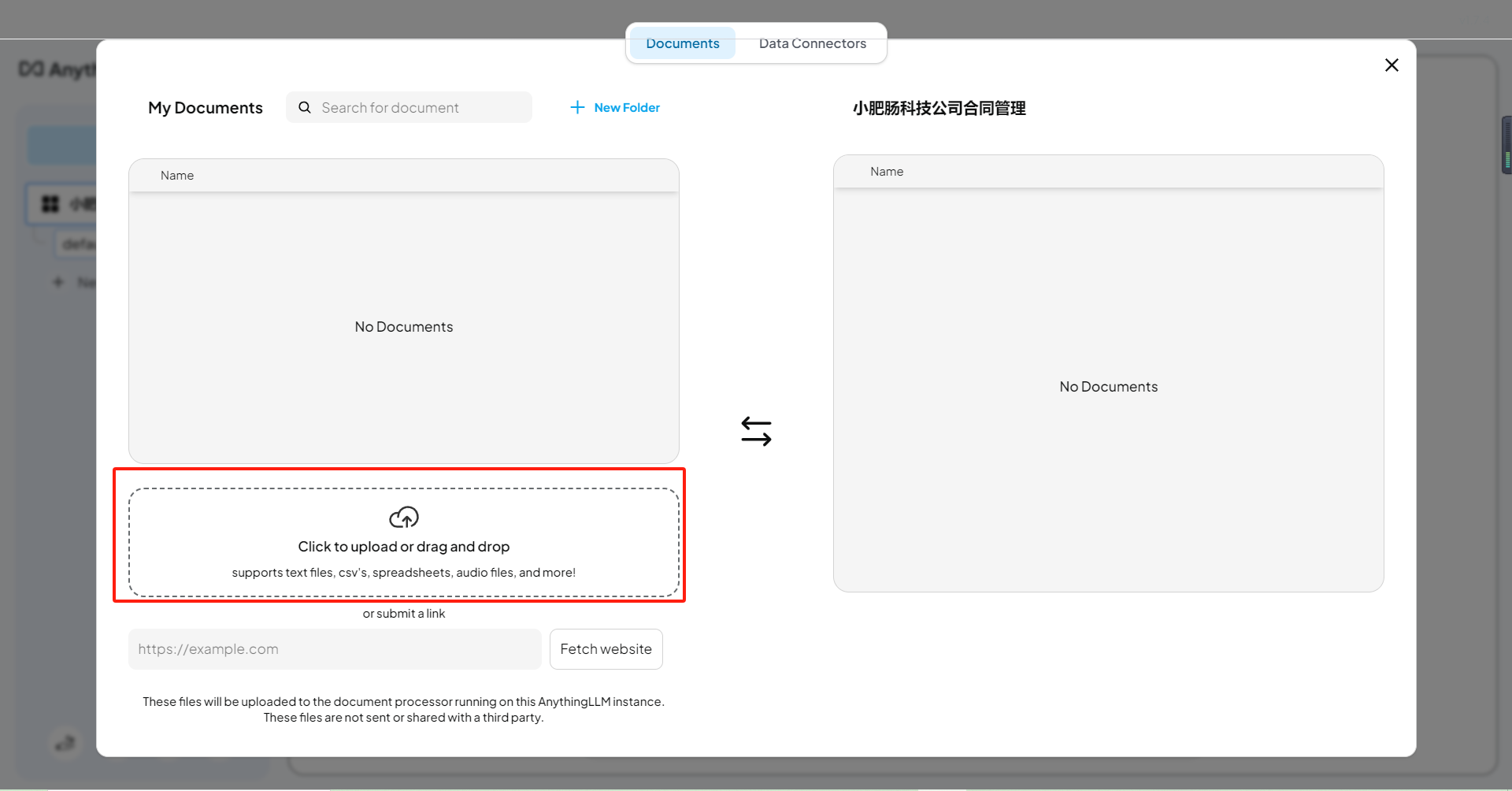
上传完成后点击【Move to Workspace】:
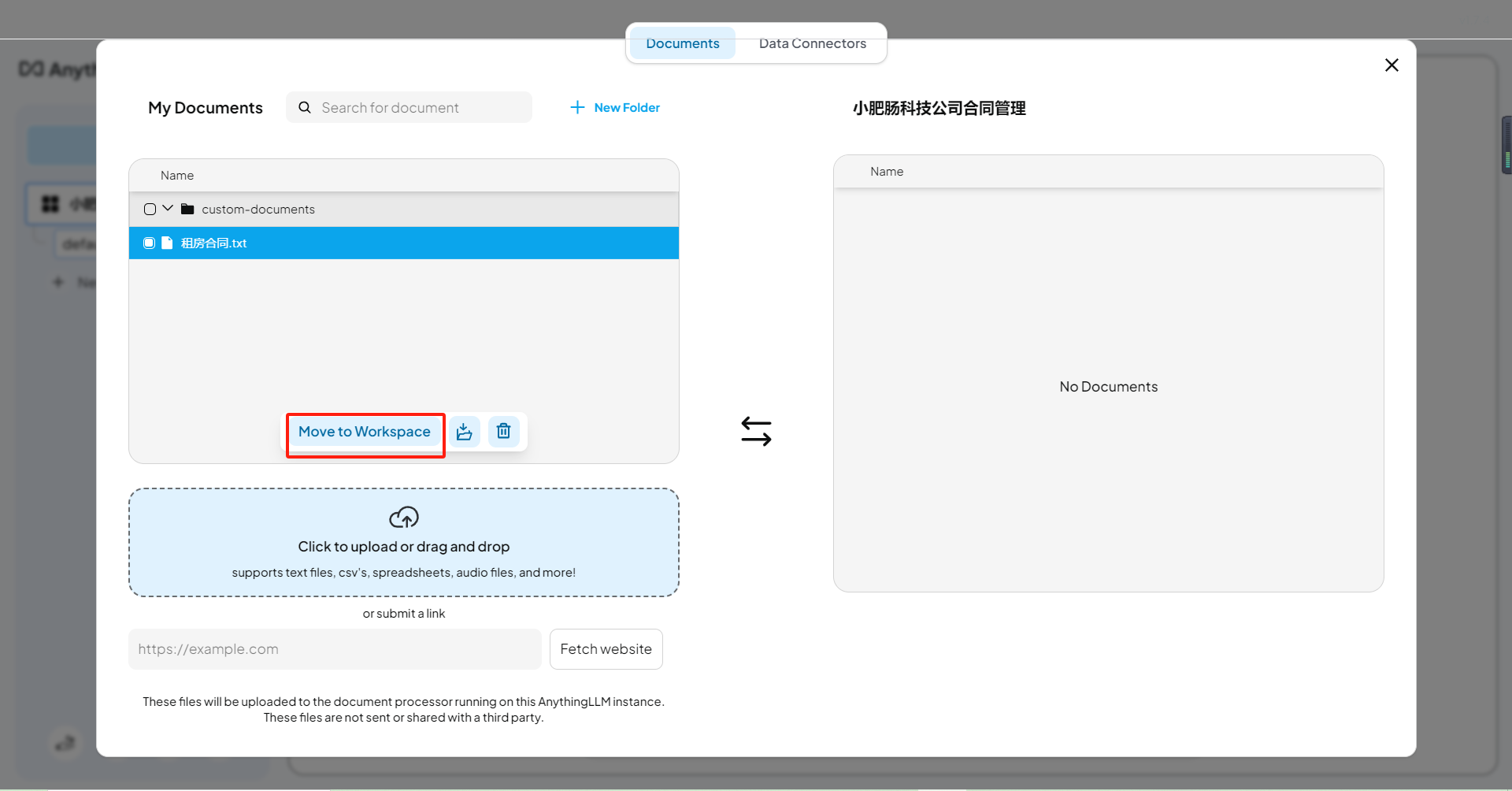
点击【Save and Embed】:
3.3. 效果测试
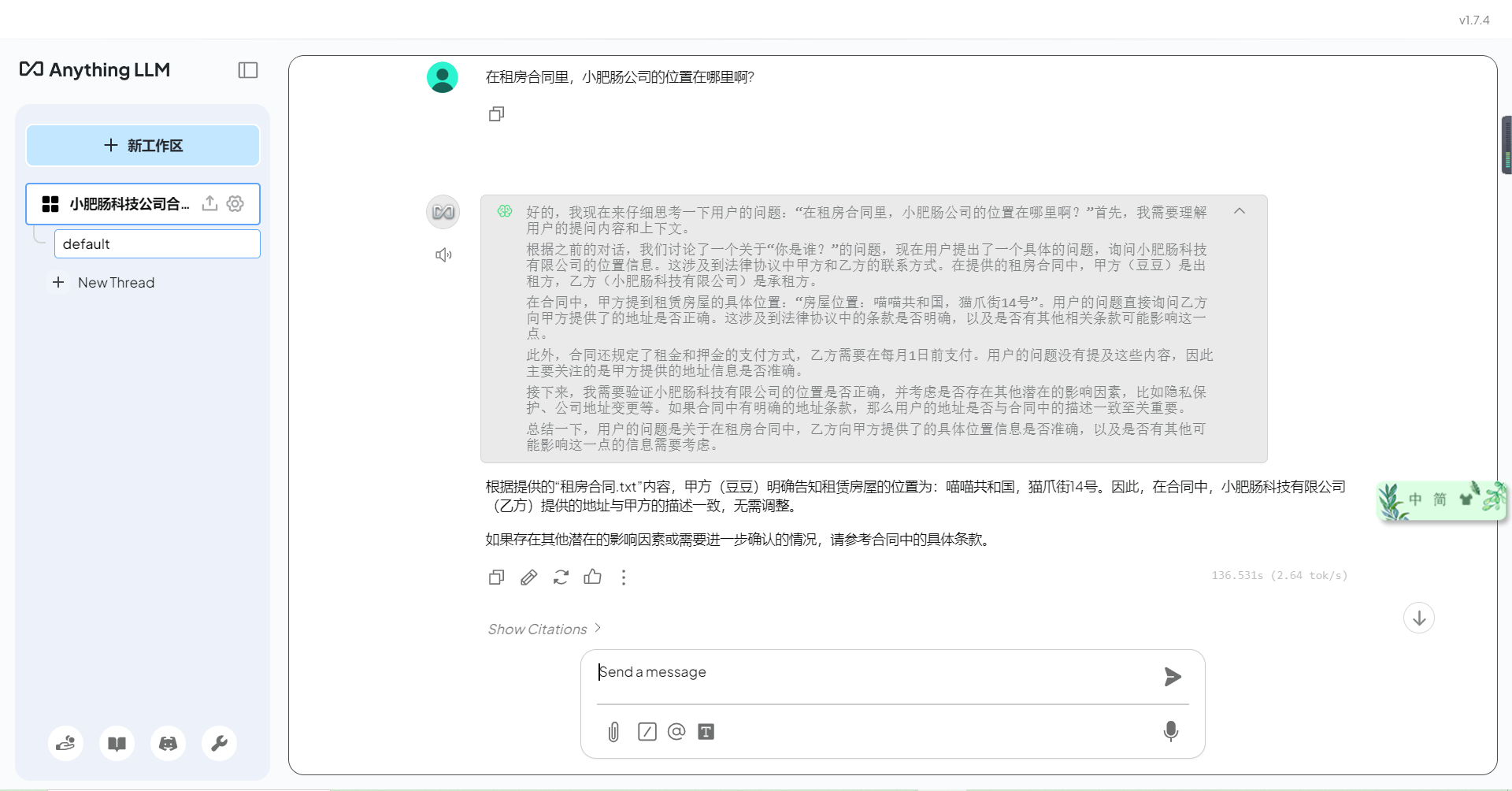
到此DeepSeek-RAG和本地知识库的构建内容完结,需要注意的是本地部署很吃电脑配置,尽量选配置高一点的电脑,如果电脑配置实在不给力也可以选择联网版本的RAG(后续更新的智能体文章会讲)。
4. 资料获取
如果你对DeepSpeek的相关知识还不熟悉,可以关注gzh后端小肥肠,点击底部【资源】菜单获取DeepSpeek相关教程。
5. 结语
随着人工智能的不断发展,AI已经不仅仅是一个技术工具,它正在深入改变我们的工作和生活方式。在信息处理、数据管理等领域,AI的应用已经成为提升效率、减少错误的关键。DeepSeek-RAG和本地知识库的构建,是确保AI高效、可靠运作的核心所在。掌握这些技术,不仅能让你走在技术前沿,更能帮助你在未来的职场竞争中占据先机。如果本文对你有帮助,请给小肥肠点点关注,小肥肠将持续更新更多AI领域干货内容,你的关注是小肥肠最大更新动力哦~




















 2302
2302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











