




文章汉化系列目录
文章目录
摘要
多模态基于方面的情感分析(Multimodal Aspect-Based Sentiment Analysis, MABSA)结合文本和图像信息进行情感分析,但通常会因无关或误导性的视觉信息而面临困难。现有的方法通常单独处理句子-图像去噪或方面-图像去噪的问题,但无法全面解决这两类噪声的干扰。为了解决这些局限性,我们提出了一种名为 DualDe 的新方法,该方法包含两个独立的模块:混合课程去噪模块(Hybrid Curriculum Denoising Module, HCD) 和 方面增强去噪模块(Aspect-Enhance Denoising Module, AED)。
- HCD 模块通过引入灵活的课程学习策略,优先在干净的数据上进行训练,从而提升了句子-图像去噪的效果。
- 同时,AED 模块通过基于方面引导的注意力机制(aspect-guided attention mechanism)过滤掉与特定方面无关的噪声视觉区域,从而缓解了方面-图像噪声的问题。
我们的方法在应对句子-图像噪声和方面-图像噪声方面均表现出显著的效果,并通过基准数据集的实验评估验证了其有效性。
1 引言
情感分析(Sentiment Analysis)是自然语言处理(NLP)中的一项基础任务(Zhang 和 Liu,2012),旨在发现并解读用户生成内容中蕴含的观点、态度和情感。多模态基于方面的情感分析(Multimodal Aspect-Based Sentiment Analysis, MABSA) 通过结合文本和视觉模态,将情感分析扩展到更深层次,从而实现对情感更全面的理解。
MABSA 通常被划分为三个主要子任务:
- 多模态方面术语提取(Multimodal Aspect Term Extraction, MATE):
- 该子任务聚焦于从文本中识别并提取与具体方面相关的术语(Wu 等,2020a)。
- 多模态方面导向情感分类(Multimodal Aspect-Oriented Sentiment Classification, MASC):
- 该任务涉及对每个方面术语相关的情感进行分类,分类类别通常包括“正面”、“中性”或“负面”(Yu 和 Jiang,2019)。
- 联合多模态方面-情感分析(Joint Multimodal Aspect-Sentiment Analysis, JMASA):
- 该任务同时处理方面提取和情感分类,从而为方面和情感提供统一的分析(Ju 等,2021)。
在实际场景中,并非所有图像都与伴随的文本相关;有些图像甚至会误导句子的语境和情感理解。即使是与文本相关的图像,其中并非所有的视觉块都与该方面紧密相关,实际上,图像中常常存在引入噪声的视觉块。为了解决这些问题,现有的方法主要集中于句子-图像或方面-图像的去噪。例如,(Ju et al., 2021)和(Sun et al., 2021)通过检测文本-图像关系来过滤掉不相关的视觉信息,但可能会错过被认为不相关的图像中的重要细节。(Zhao et al., 2023)采用课程学习的方法,逐步向模型暴露噪声图像;然而,他们固定的噪声度量限制了灵活性。另一方面,(Zhang et al., 2021)和(Yu et al., 2022)方法则专注于视觉对象与特定词汇之间的互动,而(Zhou et al., 2023)使用了一个方面感知的注意力模块进行细粒度对齐。尽管这些方法有其优点,但它们往往忽略了句子-图像去噪的重要性,正如图1所示。

图1:句子-图像去噪和方面-图像去噪的示意图。句子-图像去噪将与整个句子意义相关的图像分类为干净图像。方面-图像去噪则在图像中识别出缺乏与任何特定方面强相关性的区域为噪声(例如模糊区域)。
在本文中,我们提出了DualDe,一种先进的方法,旨在全面解决句子-图像和方面-图像的噪声问题。DualDe集成了两个主要组件:混合课程去噪模块(HCD)和方面增强去噪模块(AED)。混合课程去噪模块通过实施灵活的课程学习方法,动态调整噪声度量,基于模型表现和预定义标准,从而提升了适应性,推动了句子-图像去噪的进展。方面增强去噪模块(AED)利用方面引导的注意力机制,选择性地过滤掉与每个特定方面无关的视觉区域和文本标记,从而提高图像-文本的对齐性。我们的贡献总结如下:
据我们所知,我们是首个提出DualDe模型的研究,该模型同时解决了句子-图像和方面-图像的噪声问题。
• 我们引入了混合课程去噪模块(HCD),该模块在训练框架中有效地平衡了泛化能力和适应性。
• 通过在Twitter-15和Twitter-17数据集上的广泛实验,我们展示了我们方法的有效性。
2 相关工作
2.1 多模态基于方面的情感分析
随着社交媒体的普及,用户发布的内容通常包含文本和图像等多种模态,因此,利用多模态方法分析用户生成内容中的方面和情感受到了广泛关注(Cai et al., 2019)。多模态基于方面的情感分析(MABSA)任务通常分为三个核心子任务:多模态方面词汇提取(MATE)(Wu et al., 2020a),该任务专注于识别文本中的方面词汇;多模态方面导向情感分类(MASC)(Yu and Jiang, 2019),该任务对与每个方面词汇相关的情感进行分类;联合多模态方面-情感分析(JMASA)(Ju et al., 2021),该任务通过同时提取方面词汇并预测其相关情感来整合MATE和MASC。
由于多模态数据中图像的噪声问题,已经提出了若干方法来解决这一问题。Ju et al.(2021)和Sun et al.(2021)通过引入辅助的跨模态关系检测模块来解决噪声图像问题,该模块过滤并仅保留那些真正有助于文本意义的图像。Ling et al.(2022)提出了一种专门用于MABSA的视觉-语言预训练架构,通过增强文本与视觉元素之间的跨模态对齐,减轻了噪声视觉块的影响。与此同时,Zhang et al.(2021)和Yu et al.(2022)通过忽略没有视觉对象的图像区域并专注于包含相关视觉元素的区域及其与文本的互动来消除噪声。Zhou et al.(2023)提出了一种方面感知的注意力模块,通过根据与方面的相关性加权标记,增强了图像-文本的对齐,从而有效地减少了方面-图像噪声。
2.2 课程学习 (Curriculum Learning)
课程学习(CL)由Bengio等人于2009年提出,是一种模仿人类学习的机器学习策略,首先从简单的概念入手,然后逐步处理更复杂的概念。CL在各种任务中显示出了显著的优势(Wang等人,2019;Lu和Zhang,2021;Platanios等人,2019;Nguyen等人,2024),并且在多模态基于方面的情感分析(MABSA)任务中,已被证明在减少噪声图像方面具有良好的效果(Zhao等人,2023)。虽然Zhao等人(2023)利用CL逐步将模型暴露于噪声图像,从较干净的数据开始,以应对句子-图像噪声问题,但他们并未考虑方面-图像噪声。在本文中,我们扩展了这一概念,提出了混合课程去噪模块(HCD),该模块专门设计用于减少句子-图像噪声并提升整体性能。
3 方法论
我们的模型包括两个主要模块:(1)混合课程去噪模块(HCD)和(2)方面增强去噪模块(AED)。方面增强去噪模块(AED)建立在基于BART的架构上,并包含两个位于编码器和解码器之间的子组件:基于方面的增强情感注意力(AESA)和图卷积网络(GCN)。该架构的概述如图2所示。
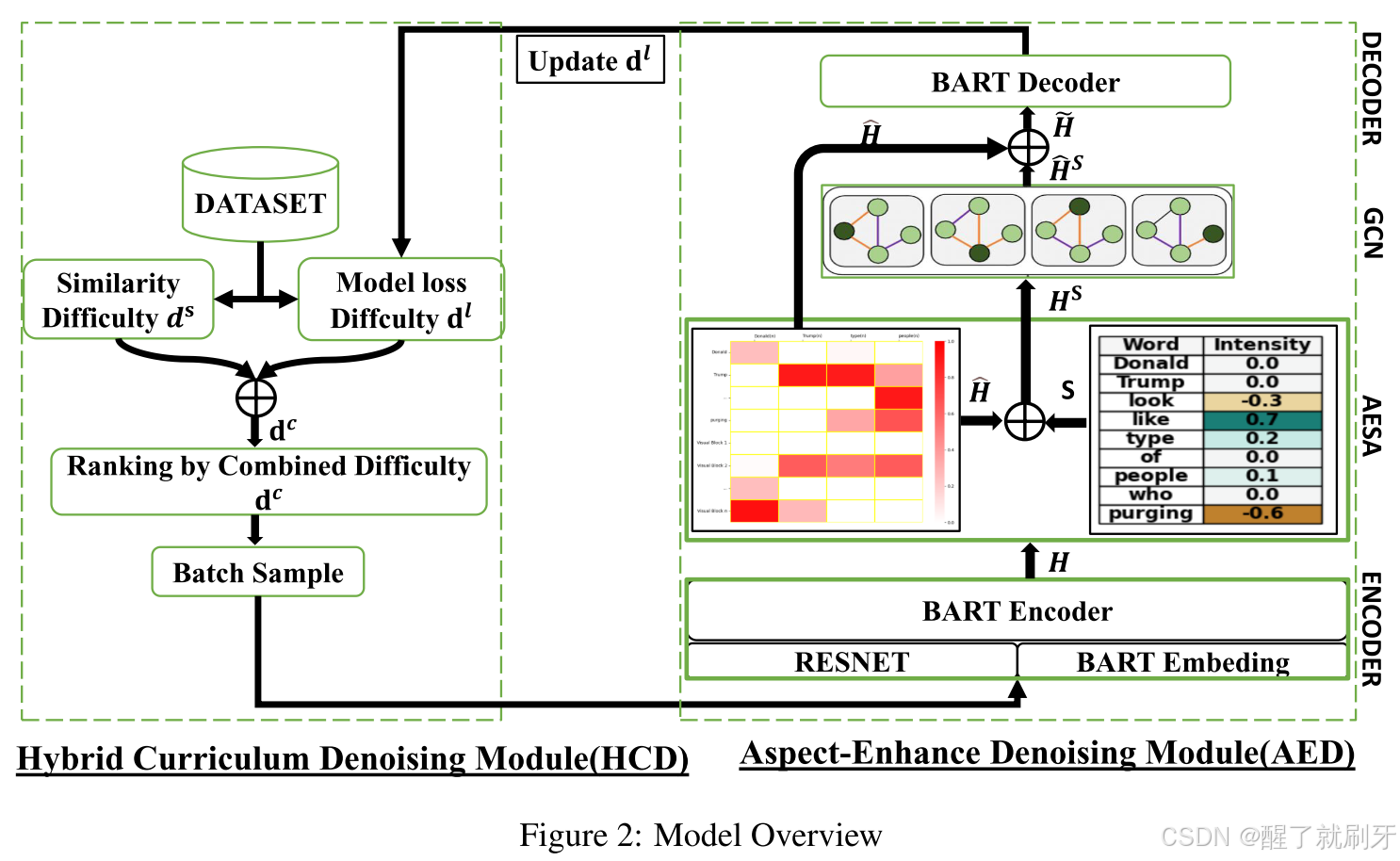
任务定义
在本任务中,给定一个带有图像 I I I 和一个由 m m m 个单词组成的句子 T = { t 1 , t 2 , … , t m } T = \{t_1, t_2, \dots, t_m\} T={ t1,t2,…,tm},目标是生成一个输出序列 Z = [ b 1 begin , b 1 end , p 1 , … , b m begin , b m end , p m ] Z = [b_1^{\text{begin}}, b_1^{\text{end}}, p_1, \dots, b_m^{\text{begin}}, b_m^{\text{end}}, p_m] Z=[b1begin,b1end,p1,…,bmbegin,bmend,pm]。每个元组 [ b i begin , b i end , p i ] [b_i^{\text{begin}}, b_i^{\text{end}}, p_i] [bibegin,biend,pi] 表示第 i i i 个方面,其中 b i begin b_i^{\text{begin}} bibegin 和 b i end b_i^{\text{end}} biend 表示该方面的起始和结束位置, p i p_i pi 表示其情感极性(正面、负面或中性)。方面可以跨越多个单词,且一个句子可能包含多个方面,每个方面可能具有不同的情感极性。
特征提取器
我们使用预训练的 BART (Lewis et al., 2019) 模型来嵌入单词,使用 ResNet (Chen et al., 2014) 来嵌入图像。格式化的输出为 I = { < img > i 1 < / img > , … , < img > i m < / img > } I = \{<\text{img}>i_1</\text{img}>, \dots, <\text{img}>i_m</\text{img}>\} I={ <img>i1</img>,…,<img>im</img>} 和 T = { < bos > t 1 < eos > , … , < bos > t n < eos > } T = \{<\text{bos}>t_1<\text{eos}>, \dots, <\text{bos}>t_n<\text{eos}>\} T={ <bos>t1<eos>,…,<bos>tn<eos>},其中 m m m 是由 ResNet 提取的图像特征数量(由 < img > . . . < / img > <\text{img}>...</\text{img}> <img>...</img> 包围), n n n 是文本特征的数量(由 < bos > . . . < / eos > <\text{bos}>...</\text{eos}> <bos>...</eos> 包围)。这些特征被组合成一个序列 X X X,然后作为 BART 编码器的输入。编码器生成多模态隐藏状态 H = { h 0 I , h 1 I , … , h m I , h 0 T , h 1 T , … , h n T } H = \{h^I_0, h^I_1, \dots, h^I_m, h^T_0, h^T_1, \dots, h^T_n\} H={ h0I,h1I,…,hmI,h0T,h1T,…,hnT},其中 h i I h^I_i hiI 表示来自图像 I I I 的第 i i i 个视觉块的特征, h j T h^T_j hjT 表示来自句子 T T T 的第 j j j 个单词的特征,总共有 m m m 个视觉块和 n n n 个单词。
3.1 混合课程去噪模块 (HCD)
该 HCD 模块采用一种灵活的训练策略,能够适应不同程度的图像噪声,从较干净的数据开始,逐步引入噪声更大的示例。通过整合来自模型预测和预定义标准的动态噪声指标,该模块增强了模型有效减轻句子-图像噪声的能力。
3.1.1 相似度难度度量
如图1所示,当一个句子与与其内容高度一致的图像配对时,可以增强对句子意义和情感的理解。因此,文本与配对图像之间的相似度可以视为学习难度的一个指标:相似度越高,学习过程越容易;相似度越低,学习难度越大。相似度得分计算公式如下:
S ( X T i , Y I i ) = cos ( X T i , Y I i ) (1) S(X_T^i, Y_I^i) = \cos(X_T^i, Y_I^i) \tag{1} S(XTi,YIi)=cos(XTi,YIi)(1)
其中, S S S 是通过余弦函数 cos ( ⋅ ) \cos(\cdot) cos(⋅) 计算的相似度得分, X T i X_T^i XTi 和 Y I i Y_I^i YIi 分别表示通过预训练的 CLIP 模型(Radford et al., 2021)的文本和图像编码器获得的文本特征和视觉特征。随后,我们定义并规范化第 i i i 个样本在句子级别的难度如下:
d s i = 1.0 − S ( X T i , Y I i ) / max 1 ≤ k ≤ N S ( X T k , Y I k ) (2) d_s^i = 1.0 - S(X_T^i, Y_I^i) \Big/ \max_{1 \leq k \leq N} S(X_T^k, Y_I^k) \tag{2} dsi=1.0−S(XTi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2101
2101

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









