




系列论文研读目录
文章目录
摘要
产品检索(PR)和产品定位(PG),旨在分别根据文本查询寻找图像和对象级的产品,为了更好的购物体验近年来引起了极大的兴趣。由于相关数据集的缺乏,我们从淘宝商城和Live两个领域收集了两个大规模的基准数据集,分别包含约474 k和101 k的图像-查询对用于PR,并为PG手动标注每个图像中的对象边界框。由于标注框昂贵且耗时,我们尝试将知识从标注的领域转移到PG的未标注领域,以实现无监督的领域自适应(PG-DA)。提出了一个领域自适应产品搜索框架,将PR和PG看作不同层次的产品搜索问题,以辅助产品的查询。具体而言,我们首先为每一个模态设计一个语义聚合的特征提取器,以获得集中和全面的特征,为后续的高效检索和细粒度的接地任务。然后,我们提出了两个合作的搜索者,同时搜索PR和PG的产品定位的图像。此外,我们设计了一个域对齐PG-DA,以减轻单峰边缘和多模态的条件分布之间的源域和目标域的移动,并设计了一个伪框生成器,以动态地选择可靠的实例,并生成边界框进一步的知识转移。大量的实验表明,我们的数据在完全监督的PR,PG和无监督的PG-DA中取得了令人满意的性能。我们的脱敏数据集将在这里公开https://github.com/Taobao-live/Product-Seeking。
1.引言
如今,随着电子商务和直播的快速发展,消费者可以在电子商城或各种直播平台上享受购物。虽然可以在屏幕上展示和购买各种产品的事实给我们带来了方便,但我们沉浸在这个繁杂的产品世界中。因此,针对产品(PR)的跨模态检索[1,3,15,21,41,43,55],旨在基于文本查询寻找对应的图像,对于提升整体产品搜索引擎和提升消费者的购物体验具有重要意义。
此外,如果对象级产品可以根据查询定位在目标产品图像或直播间图像上,这将有助于消费者关注所需的产品,也有利于下游的视觉到视觉检索。我们将这个有趣的任务命名为产品定位(PG),就像视觉定位一样[29,36,40,45,56]。通常,PR和PG被看作是两个独立的任务,但我们考虑挖掘PR和PG的共性,并将它们分别视为图像级和对象级的产品搜索。同时设计了一个统一的架构来同时解决PR和PG,这比单独的方法更节省时间和内存。
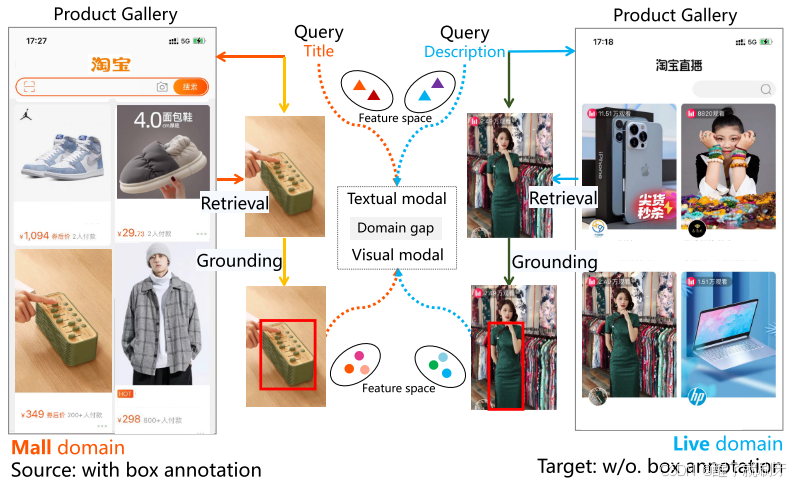
图1.从淘宝商城和Live收集的两个数据集上的产品检索(PR)和接地(PG)问题的图示。(1)给定一个文本查询(即产品的中文标题或描述),PR是从图库中查找对应的图像级产品,而PG是从图像中查找对象级产品。(2)进一步研究了PG-DA算法,该算法在多模态领域间隙的影响下,将知识从标注的源领域转移到未标注的目标领域,从而实现无监督的PG.
为了研究具有实际应用价值的PR和PG,我们收集了淘宝商城和淘宝直播两个大规模的Product Seeking基准数据集TMPS和TLPS,分别包含约47.4万个图像-标题对和10.1万个框架-描述对,并对图像中对象级产品的位置进行了人工标注。针对标注产品边界框耗时且代价高昂的问题,探讨如何将标注领域的知识转移到未标注领域,实现领域自适应环境下的无监督PG(PG-DA)。因此,我们提出了Domain Adaptive Product Seeker(DATE,领域自适应产品搜索器),以解决具有挑战性的PR,PG和PG-DA问题的以下方面。
首先,由于商场和现场场景的复杂性,图像和查询的区分表示是准确定位对象的先决条件。考虑到传统的CNN难以实现长距离关系推理和全面理解,我们利用并改进了Swin-TF [37]来提取分层和全面的特征。由于大规模图像搜索对PR的要求很高,因此确保搜索推理的成本很低至关重要。因此,我们将[REP]令牌注入SwinTF以吸收加权的全局语义,并将它们压缩到单个向量中,该向量将具有区分性和集中性,以便进行高效的图像查找。我们执行相同的语义聚合技术的查询特征提取。
其次,PR和PG都需要具有宏观图像搜索和微观细粒度目标搜索的能力。因此,我们提出了两种协作搜索器,其中图像搜索器计算PR的视觉和文本集中特征之间的余弦相似度,和目标搜索器基于交叉-模态交互Transformer通过对PG的综合特征直接预测产品的坐标,验证了这种方法的合理性合作策略。
第三,由于图1所示的两个数据集之间的域间隙,直接将模型应用于目标域测试将导致PG-DA的性能严重退化。据我们所知,这是第一个在域适应设置中考虑无监督视觉基础的工作,大多数单模态DA [8,34,38]和多模态DA [5,7]方法不直接适用于我们复杂的目标搜索。为此,设计了一种基于最大平均离散度的领域对齐器,通过最小化源领域和目标领域之间的单峰边缘分布和多峰条件分布差异来对齐领域,并设计了一个动态的伪包围盒生成器来选择目标领域中的相似实例,生成可靠的知识传递框。
综上所述,本文的主要贡献如下:(1) 我们收集并人工标注了PR和PG两个大规模的基准数据集,具有很大的实际应用价值。(2) 我们提出了一个统一的框架,语义聚合的特征提取器和合作的搜索者,同时解决全监督PR和PG。(3) 我们探索了领域自适应设置中的无监督PG,并设计了多模态领域对齐器和动态框生成器来传递知识。(4) 我们进行了大量的实验,结果表明,我们的方法在全监督PR,PG和无监督PG-DA中取得了令人满意的性能。
2.相关工作
2.1.视觉检索
给定一个文本查询,视觉检索(VR)[1,3,21,41,43,55]的目的是在库中找到相应的图像/视频。基于公共潜在空间的方法[1,55]已经证明了它们的有效性,该方法首先提取视觉和文本特征并将其映射到公共潜在空间中以直接测量视觉语言相似性。典型地,[16]应用CNN和RNN分别对图像和句子进行编码,并基于排名损失学习图像-标题匹配。[55]提出了一种语义图,以生成多层次的视觉嵌入和聚合结果的层次结构的整体跨模态相似性。最近,Transformer [46]在自然语言处理[12,20],计算机视觉[4,13,25,26,28]和多模态区域[23,24,27,33,48,50-52]方面表现出比以前的架构更好的性能,特别是对于全局信息理解。毫不奇怪,人们越来越多地将这些强大的模型重新用于VR [1,17,31,57]。他们使用Transformer学习联合多模态表示,并对详细的跨模态关系建模,取得了令人满意的性能。
2.2.视觉定位
视觉定位(VG)[29,36,40,45]的研究范式与视觉检索(VR)类似,都是根据文本查询在视觉信号中寻找最佳匹配部分。与VR相比,对图像的细粒度内部关系进行建模对于VG来说更有意义。在早期的工作中,两阶段方法[6,22,53]被广泛使用,首先生成候选对象建议,然后利用语言描述来选择最相关的对象,通过利用现成的检测器或建议生成器来确保召回。然而,计算密集型的建议生成是耗时的,并且也限制了这些方法的性能,一阶段方法[32,49]集中于直接定位所引用的对象。具体来说,[49]将语言特征融合到视觉特征映射中,并以滑动窗口的方式直接预测边界框。最近,[10]将VG重新表述为坐标回归问题,并应用Transformer来解决它。
通常将VR和VG视为两个独立的问题。本文挖掘了这两个问题的共性,设计了一个基于协同搜索的统一架构,有效地解决虚拟现实和虚拟样机问题。
2.3.无监督域自适应
无监督领域自适应(UDA)的目标是将知识从标注的源领域转移到未标注的目标领域,其难点在于如何克服领域间隙的影响。在单模态任务应用中,已经探索了几种UDA技术,包括对准跨域特征分布[18,34]、应用对抗学习策略[2,38]或重构方法[8]以获得域不变特征。并且[9]使用最优传输来估计两个分布之间的差异,并利用来自源域的标签。与上述工作不同,我们的任务本质上是跨模态的,由于不同模态之间的异质性差距,这更具挑战性。在多模态领域,很少有研究工作考虑到UDA,[5]研究了面向视觉问答的跨数据集自适应,[7]研究了基于伪标记算法的视频文本检索。据我们所知,这是第一次在领域适应设置中考虑无监督视觉定位的工作。
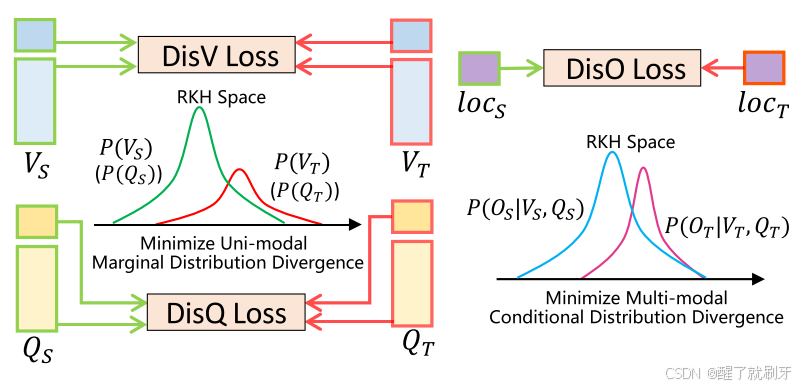
图3.多模态域校准器。
3.提出Date
3.1.问题公式化
本文研究了全监督的PR和PG,以及无监督的PG-DA在域自适应环境中的应用(设置)。接下来,我们将对它们进行阐述。
PR和PG。我们收集一个完全注释的数据集 { V , Q , O } \{V,Q,O\} {
V,Q,O},给定查询集 Q Q Q中的文本查询 Q i Q_i Qi,PR和PG旨在从整个图像库 V V V中寻找图像级产品 V Q i V_{Q_i} VQi,并从匹配的图像 V Q i V_{Q_i} VQi中寻找对象级产品 O Q i O_{Q_i} OQi。 O O O是边界框注释。
PG-DA. 我们可以访问完全注释的源域 S = { V S , Q S , O S } S =\{ V^S,Q^S,O^S\} S={
VS,QS,OS},以及没有框注释 O T O^T OT的未注释的目标域 T = { V T , Q T } \mathcal{T}=\left\{V^{T},Q^{T}\right\} T={
VT,QT}。PG-DA的目标是将知识从 S S S转移到 T \mathcal{T} T,并在 T \mathcal{T} T上寻求对象级产品。
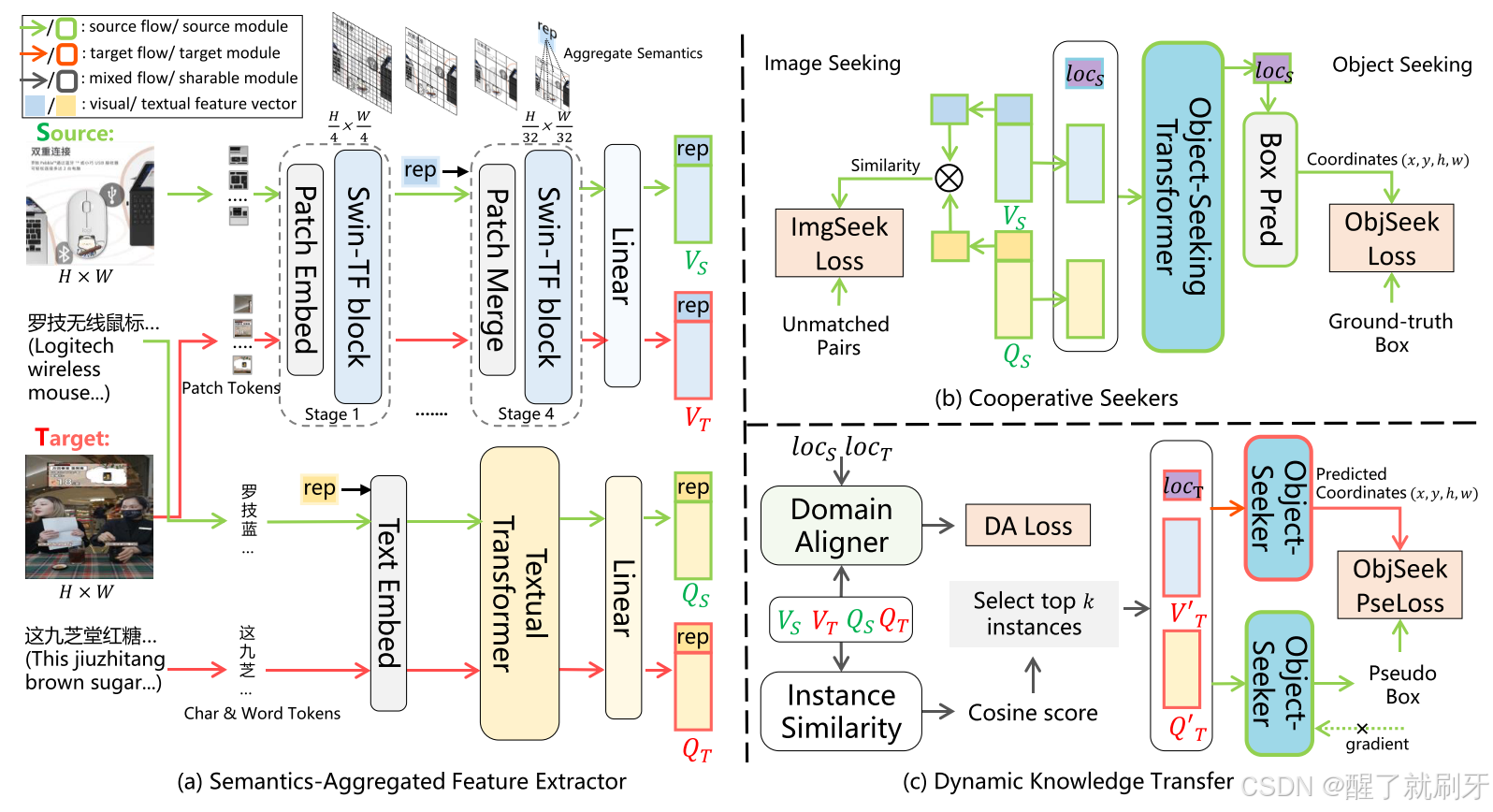
图2.DATE概述。(a)是特征提取器,应用语义聚合transformers来获得图像和查询特征。(b)为合作的搜索者,通过计算相似度为PR寻找图像,通过预测坐标以寻找PG的对象。©包括用于最小化源域和目标域之间的分布发散的域对齐器和用于选择可靠实例并生成用于PG-DA中的知识转移的边界框的伪框生成器。
3.2.语义聚合特征提取器
如图2(a)所示,对于这两种设置,我们共享特征提取器,该特征提取器可以聚合用于图像搜索的每个模态的全局语义,以及捕获用于对象搜索的全面和上下文感知的特征。
图像流。给定RGB图像 v v v,我们首先将其分割成不重叠的块,然后我们参考Swin-TF [37]进行分层特征提取。Swin主要通过面片合并模块和Swin Transformer模块的堆栈实现4级编码,每级分辨率减半,获得层次化特征。原始Swin-TF算法利用平均池来获取图像表示向量,忽略了每个特征点在语义提取中重要性的差异。为了提高算法的性能,在第四阶段,在视觉标记序列的前面添加一个可学习的[REP]标记,它参与了自注意的计算,并吸收了加权后的全局图像特征。在第四阶段之后,我们得到了语义聚合的视觉特征,并将这种视觉编码器命名为SA-Swin。然后应用线性层将它们投影到d维得到 V S A = [ V r e p , V ] ∈ R d × ( 1 + N v ) \bm{V}_{SA} = [V_{rep},\bm{V}] ∈ R^{d×(1+N_v)} VSA=[Vrep,V]∈Rd×(1+Nv),其中 N v N_v Nv是视觉标记的数目, V r e p V_{rep} Vrep和 V \bm{V} V分别是集中和综合的特征。
查询数据流。给定一个文本查询 q q q,我们首先将其拆分为字符级序列,并将每个字符转换
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 860
860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









