 Product1M与CAPTURE助力弱监督产品检索
Product1M与CAPTURE助力弱监督产品检索





系列论文研读目录
文章目录
摘要
随着电子商务时代顾客需求的多样化,给产品检索行业带来了更多的复杂性。以前的方法要么受到单模态输入或执行有监督图像级产品检索,从而无法适应存在巨大的弱注释的多模态数据的现实生活的情况。在本文中,我们研究了一个更现实的设置,旨在细粒度的产品类别之间进行弱监督的多模态实例级产品检索。为了促进这一具有挑战性的任务的研究,我们贡献了Product1M,一个最大的多模态化妆品数据集为了真实世界的实例级检索。值得注意的是,产品1M包含超过100万个图像捕获对,并且由两种样本类型组成,即,单产品和多产品样品,其中包括各种化妆品品牌。除了多样性之外,Product1M还具有一些吸引人的特性,包括细粒度的类别,复杂的组合和模糊的对应关系,这些都很好地模仿了现实世界的场景。此外,我们提出了一种新的模型命名为跨模态对比产品Transformer的实例级产品检索(Cross-modal contrAstive Product Transformer for instance-level prodUct REtrieval,CAPTURE),善于捕捉多模态输入之间的潜在协同作用,通过一个混合流Transformer,在自我监督的方式下。CAPTURE通过掩码多模态学习和跨模态对比预训练生成有区别的实例特征,并且它优于几个SOTA跨模态基线。大量的消融研究很好地证明了我们的模型的有效性和泛化能力。数据集和代码可在https://github.com/zhanxlin/Product1M上获得。
1.引言
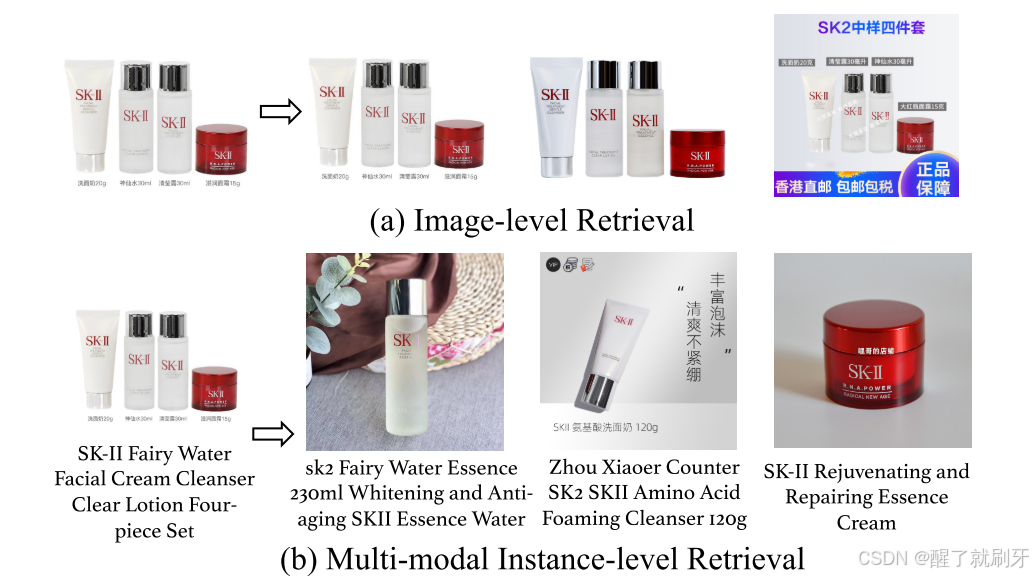
图1.我们提出的任务是在多模态数据中执行实例级检索。
在过去的二十年里,电子商务的商品种类高度丰富,网上消费者的需求多样化。一方面,在线商品具有越来越多样化的类别,并且其中很大一部分被展示为产品组合,其中不同产品的多个实例存在于一个图像中。另一方面,在线客户或商家可能希望检索组合中的单个产品以进行价格比较[42]或在线商品推荐[34]。此外,随着多媒体生成的异构数据的不断加速积累,算法如何处理大规模且弱注释的数据[45]来执行多模式检索仍然是一个问题。
在本文中,我们探讨了一个现实的问题:如何在给定的大规模弱标注的多模态数据上执行实例级细粒度的产品检索?我们在图1中比较了不同的检索范式。可以看出,图像级检索往往返回琐碎的结果,因为它不区分不同的实例,而多模态实例级检索更有利于在多模态数据中搜索各种产品。尽管这个问题有普遍性和实用价值,它并没有得到很好的研究,由于缺乏真实世界的数据集和一个明确的问题定义。在产品检索的文献中,模态内检索[32,1,31,30]和跨模态检索[43,12,48,4,44,8]将单模态信息作为输入,例如,图像或一段文本,并在分离的数据点之间执行匹配搜索。不幸的是,在许多情况下这样的检索计划显着限制其使用,多模态信息存在于查询和目标。更重要的是,以前的工作集中在相对简单的情况下。比如,图像级产品检索单一产品的图像[24,13]和检索的实例级性质这两项是未经探索的。
实例级产品检索是指对产品组合图像中存在的所有单个产品进行检索。
图像级产品检索是指识别单个产品图像中的特定产品实例。

表1.不同数据集之间的比较。“-”表示不适用。Product 1 M的#instances和#obj/img用斜体表示,因为训练集没有实例标签,我们只统计验证集和test集中的实例。Product 1 M是最大的多模态数据集之一,也是第一个专门为真实世界的实例级检索场景定制的数据集。
为了填补这一空白,推进相关研究,我们收集了一个大规模的数据集Product 1 M,提出了一种多模态实例级检索方法。Product 1 M包含超过100万个图像-字幕对,并由两种类型的样本组成,即:单一产品和多产品样品。每个单一产品样本都属于一个细粒度的类别,类别间的差异很小。多产品样本具有很大的多样性,导致了复杂的组合和模糊的对应关系,很好地模拟了现实世界的场景。据我们所知,Product 1 M是最大的多模态数据集之一,也是第一个专门为真实世界的多模态实例级检索场景定制的数据集.
除了构造的数据集,我们还提出了一种新的自监督训练框架,从大规模弱注释数据中提取代表性的实例级特征。具体来说,我们首先通过结合一个简单而有效的数据增强方案,从伪标签中训练一个多产品检测器。然后,CAPTURE被提出来通过几个代理任务来捕获图像和文本的潜在协同作用。我们展示了一些流行的跨模态预训练方法[27,25,6,38]可能由于网络架构的设计缺陷或不适当的代理任务而在多实例设置下存在缺陷。相比之下,CAPTURE利用混合流架构,该架构分别对不同模态的数据进行编码,并以统一的方式将其融合,实验表明这对我们提出的任务是有益的。此外,我们引入跨模态对比损失来强制CAPTURE实现图像和文本之间的对齐,从而避免了不适当的代理任务所引起的不匹配问题。
至关重要的是,CAPTURE在所有主要指标方面都大大超过了SOTA的跨模态基线。我们进一步进行了广泛的消融实验来证明CAPTURE的泛化能力,并探索我们提出的任务的几个关键因素。我们希望所提出的 Product1M、CAPTURE 以及稳健的基线能够推动未来在现实世界检索方面的研究进展。
2.相关工作
模态内和跨模态检索。模态内检索[32,1]在基于关键字的Web文档检索[11],基于内容的图像检索[29]和产品推荐[19,20]中得到了广泛的研究。跨模态检索[43,12,48,4,44,8]作为在具有不同模态的大规模数据中进行有效索引和搜索的有希望的途径而出现,并且广泛用于搜索引擎[2,14],电子商务[18,7],仅举几例。然而,这些方法[30,26,7,47,46]通常受到单一模态输入的影响,这使得它们难以应用于许多现实世界的场景,其中查询和目标中都存在多模态信息。
WSOD:弱监督目标检测。WSOD [39,36,50]通过从更便宜或免费提供的数据中学习,减少了对细粒度标签的过度依赖。PCL [39]迭代地生成建议聚类,以促进实例分类器的学习。从图像标签[36]和非结构化文本描述(如标题[50])生成的伪标签也有利于提高WSOD的性能。然而,WSOD通常依赖于预定义类的固定大小的集合,并且不容易适用于我们提出的任务,其中类标签不可用(我理解为不知道类标签)并且类别可以动态更新。
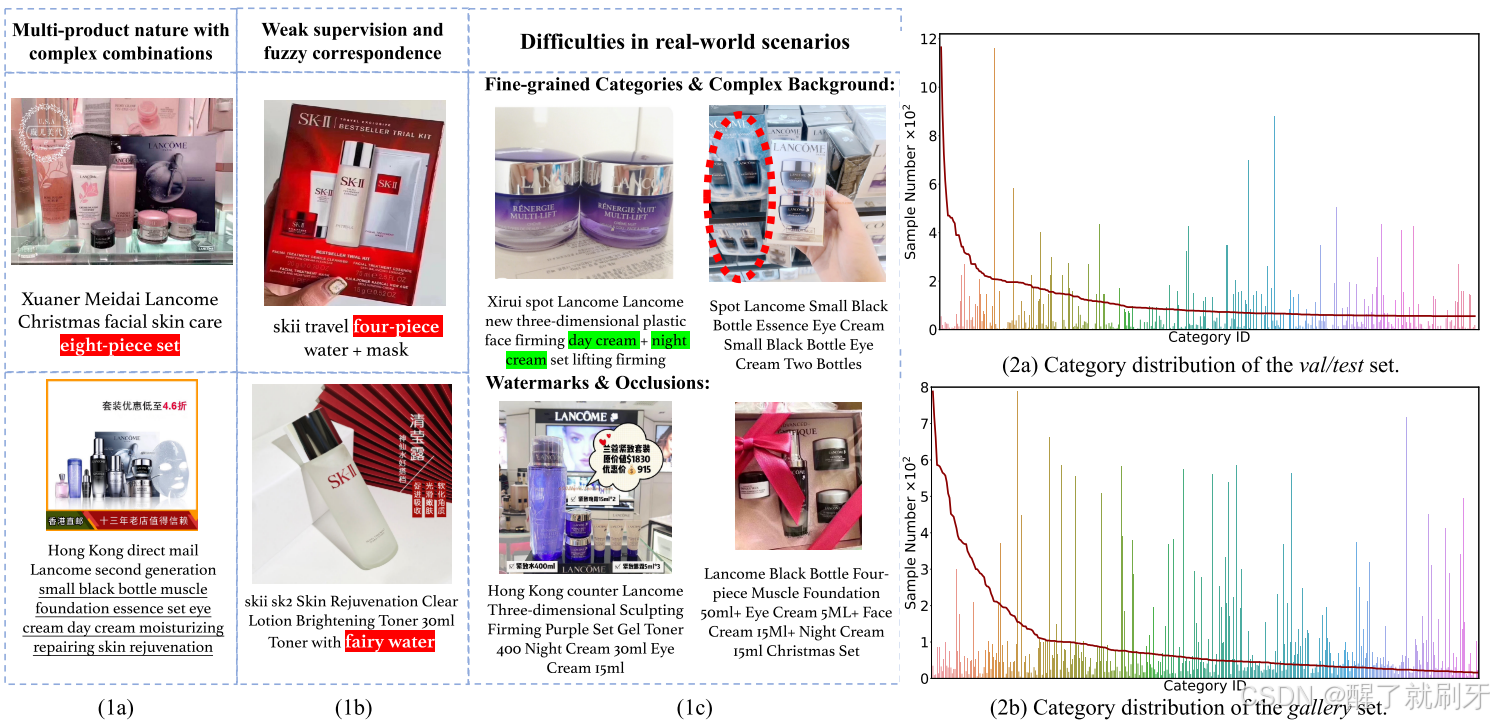
图2.Product 1 M的特征和统计:(1a)单个产品的复杂组合;(1b)弱监督和模糊对应;(1c)在现实场景中的困难;(2)Product 1 M的长尾类别分布。该行以降序显示每个类别的样本编号。Product 1 M包含各种各样的类别,并且长尾类分布与实际场景非常一致。
跨模态自我监督学习。现有的视觉语言预训练模型通常使用多层Transformer [41]架构,如BERT [9]来学习多模态数据上的图像-文本语义对齐。单流模型[25,37,6]在统一架构中对组合的多模态特征进行编码,而其他双流模型[27,38]则对不同模态的输入使用不同的编码器。这些方法不是为实例级检索量身定制的,我们展示了它们可能由于网络架构中的设计缺陷和不适当的代理任务而存在缺陷。
3.Product1M上的实例级检索
3.1.任务定义
产品样本 ( I , C ) (I,C) (I,C)是一个图像-文本对,其中 I I I是产品图像, C C C是标题。给定单个产品样本的图库集合 S = { S i ∣ S i = ( I S i , C S i ) } {\cal S}=\{S_{i}|{\cal S}_{i}=(I_{\cal S}^{i},C_{\cal S}^{i})\} S={ Si∣Si=(ISi,CSi)}和多产品样本的图库集合 P = { P i ∣ P i = ( I P i , C P i ) } {\cal P}=\{\cal P_{i}|{\cal P}_{i}=(I_{\cal P}^{i},C_{\cal P}^{i})\} P={ Pi∣Pi=(I
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1019
1019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









