






索引
主键索引
-
b+树的叶子结点包括整棵树所有的元素
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QLIU2KiN-1595061149424)(/Users/yuanhuiliang/Library/Application Support/typora-user-images/image-20200718132041210.png)]](https://i-blog.csdnimg.cn/blog_migrate/1762d1cdc4e5d69d4cf421ec45259e6c.png)
-
主键索引,默认从小到大排序,跟插入顺序无关
-
页–内存跟磁盘进行交互的最小单元
-
页—局部性原理 —4kb(操作系统)—减少磁盘io—两次指令可以只用一次io
-
inndb里边—>页–>16kb
-
插入的时候,会根据主键id默认升序排列;如果没有主键索引,inndb会默认生成一列rowId当作主键索引,默认自增;
-
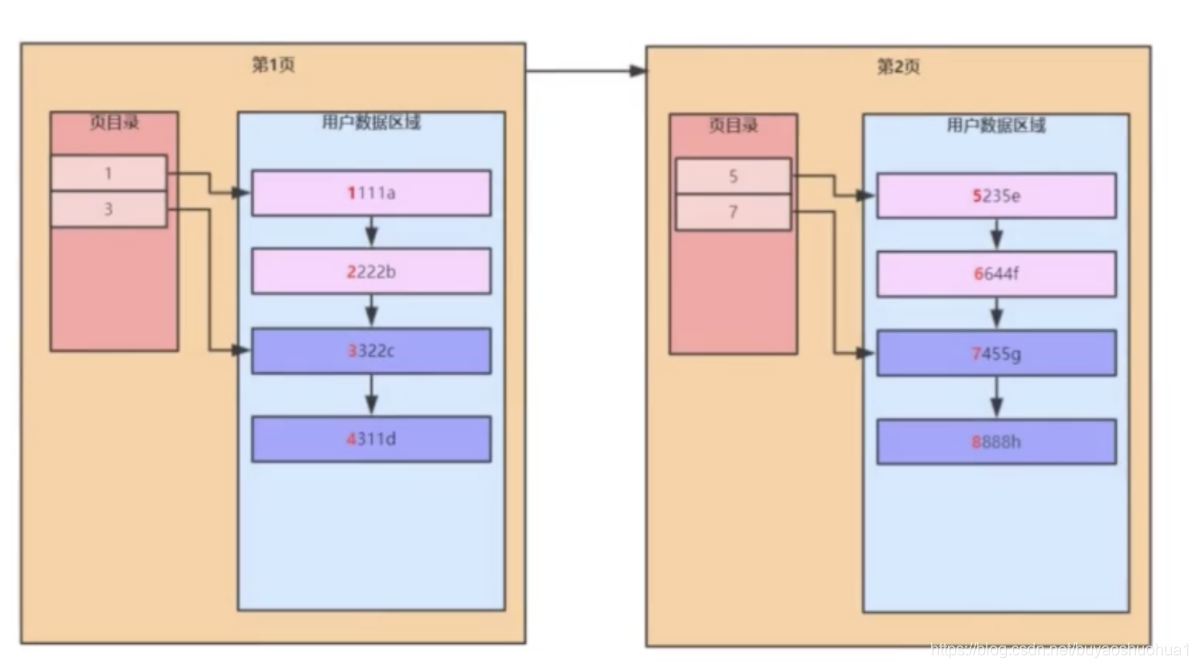
当链表数据非常长的时候,inndb内部会进行分组,默认是6行为一组,跟页目录进行挂钩关联;链表查询本来就比较慢,查询数据时候,先根据页目录进行判断;
- 页目录的作用就是以空间去换时间;,页目录存放该页**最小**的索引值;
- 当第一页满的时候,需要再扩展出第二页,
-
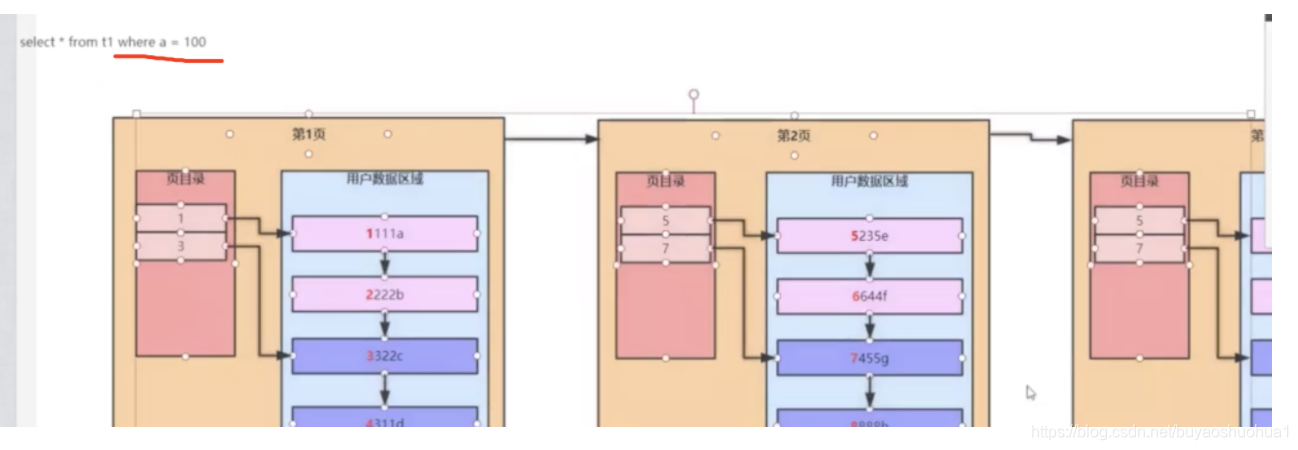
思考:(当数据链表很长,数据很多的时候,会出现页目录,那如果页的数量很多的话,岂不是跟数据链表性质一样的,也是要根据链表指针挨着遍历去查询)
-
-
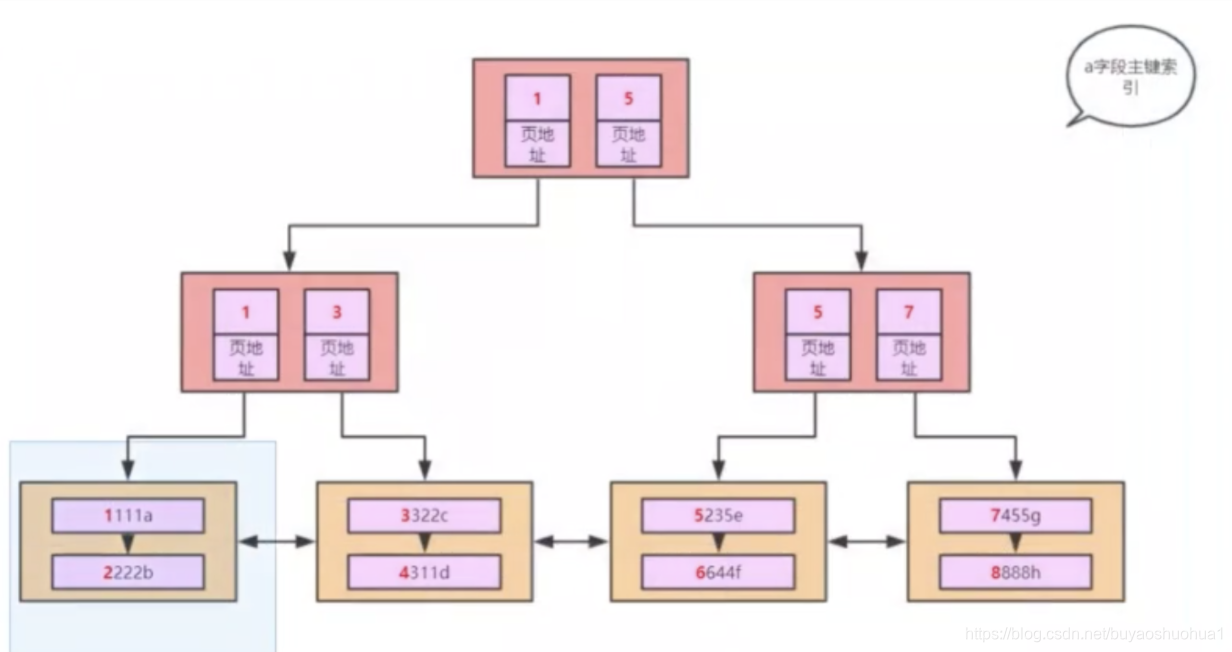
继续空间换时间
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KaTpM38P-1595061149431)(/Users/yuanhuiliang/Library/Application Support/typora-user-images/image-20200718141620840.png)]](https://i-blog.csdnimg.cn/blog_migrate/c53d428d79b2e9a48103bcadc399cda6.png)
-
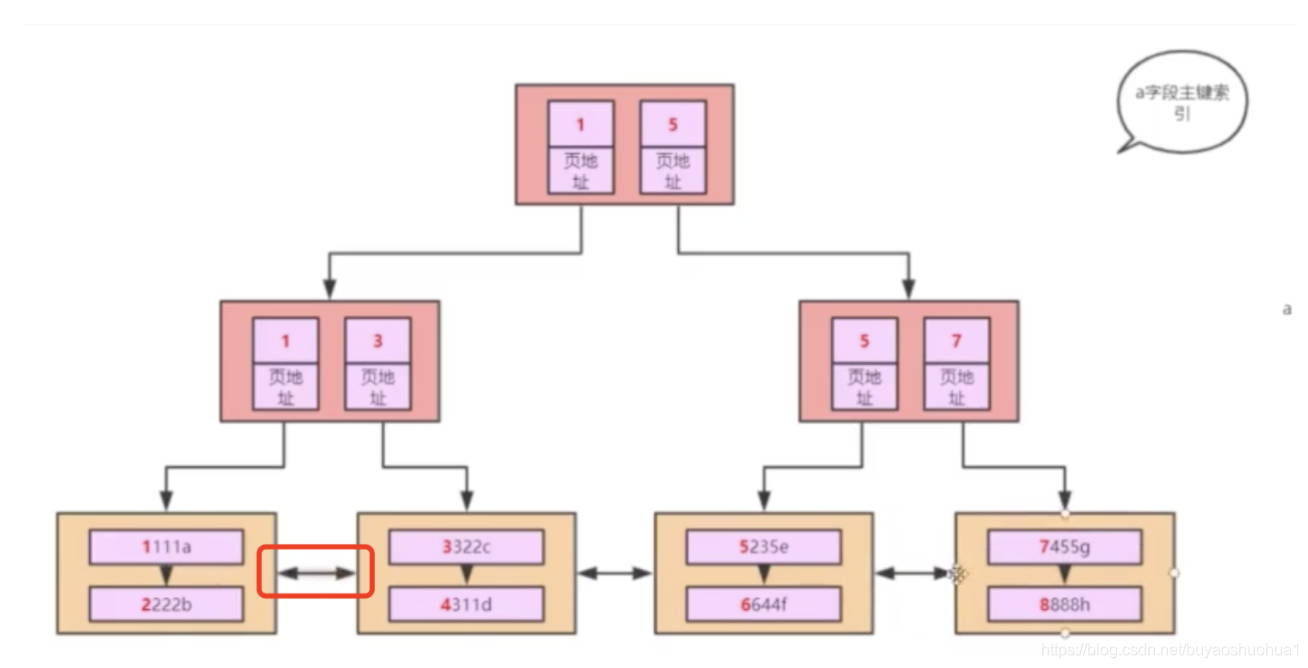
好看一点(索引数据+真实数据)
-
注意双向指针,当查询a>8或者a<5的时候,双向指针就用到了,会根据该指针把前边或者后边所有的数据都查询出来;
联合索引
- 上边主键索引a, 叶子结点是按照主键去排序的,那么创建联合索引(b,c,d),叶子结点是按照什么去排序的??
- 为啥是最左原则,根据*cd,去查询,根据按照bcd索引,根本匹配不出来,只会进行全表扫描;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hbXlDyyF-1595061149435)(/Users/yuanhuiliang/Library/Application Support/typora-user-images/image-20200718145503926.png)]](https://i-blog.csdnimg.cn/blog_migrate/2fb345ea12aadb26e362701fc55d1818.png)
-
上边的索引结构会有一个问题,因为我们主键索引的叶子结点已经存储了所有的数据信息,这里再存储一份,会造成资源和内存的浪费,所以inndb内部的联合索引会是下边的方式:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-heg85rmy-1595061149436)(/Users/yuanhuiliang/Library/Application Support/typora-user-images/image-20200718150139274.png)]](https://i-blog.csdnimg.cn/blog_migrate/64f36a64e09049ced2e02a8537586175.png)
-
存储的主键id的作用,一个词来说就是回表;如果要查询该数据所有字段的话,会根据主键id再去查询整条数据信息
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Pb5r8Yp5-1595061149438)(/Users/yuanhuiliang/Library/Application Support/typora-user-images/image-20200718151011906.png)]](https://i-blog.csdnimg.cn/blog_migrate/de7dab758aaa05c1ead2904b50379a5e.png)
-
如果是根据b*d去查询呢,where b=1 and d=2;注意回表的时间点;
-
Mysql5.7 之前,会根据b找到符合条件的主键id, 然后回表去查询到结果,然后根据d=2这个条件去匹配到数据;然后再进行回表,因为条件是select *,需要所有的字段;extra是Using where
-
Mysql5.7 现在是根据b找到符合条件之后,直接再根据d=2这个条件进行过滤,得到过滤后的结果再进行回表,相当于减少回表的次数;extra是Using index condition
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gVMw1ZoR-1595061149439)(/Users/yuanhuiliang/Library/Application Support/typora-user-images/image-20200718153256677.png)]](https://i-blog.csdnimg.cn/blog_migrate/fe0d095e63ba3ad1ea229d9a2a224225.png)
-
-
查询优化器,是走全表扫描快还说走索引快,注意回表的影响,如果回表次数多的话,会考虑全表扫描;
-
注意下边的两点:
SELECT 1=‘1’;-------1
SELECT ‘a’=1;------0
- 主键a是int类型,where a=‘1’,会使用到索引
- 字段e是Varcher类型,创建了索引,但是 where e=1;不会使用到索引
-
复合索引的非叶子节点,也会把对应的主键存储在一起,如果是这样的条件:where b=1 and c=1 and d=3 where a>1;这样的话,存储在非叶子节点的主键id索引就参与了比较;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-plaj3cRq-1595061149440)(/Users/yuanhuiliang/Library/Application Support/typora-user-images/image-20200718163215937.png)]](https://i-blog.csdnimg.cn/blog_migrate/80f03b449f78b313ac651411106a8fa6.png)

















 1614
1614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









