




 本文指导如何根据预测建模问题选择合适的神经网络,探讨多层感知器(MLP)、卷积神经网络(CNN)及递归神经网络(RNN)的应用场景,包括分类、回归、图像、文本和时间序列数据,同时提出混合网络模型的概念。
本文指导如何根据预测建模问题选择合适的神经网络,探讨多层感知器(MLP)、卷积神经网络(CNN)及递归神经网络(RNN)的应用场景,包括分类、回归、图像、文本和时间序列数据,同时提出混合网络模型的概念。
什么神经网络适合你的预测建模问题?
对于深层学习领域的初学者来说,知道使用哪种类型的网络可能是困难的。每天都有那么多类型的网络可供选择,并且有新的方法被公布和讨论。更糟糕的是,大多数神经网络足够灵活,即使用于错误的数据类型或预测问题,它们也能够工作(进行预测)。
在这篇文章中,你将发现三种主要人工神经网络的建议用途。
读完这篇文章,你会知道:
- 在处理预测建模问题时,需要关注哪种类型的神经网络。
- 何时使用、不使用,以及可能的尝试在项目中使用MLP、CNN和RNN。
- 在选择模型之前,要考虑使用混合模型,并清楚地了解项目目标。
我们开始吧。
概述
这篇文章分为五个部分,它们是:
- 要关注什么神经网络?
- 何时使用多层感知器?
- 何时使用卷积神经网络?
- 何时使用递归神经网络?
- 混合网络模型
要关注什么神经网络?
深度学习是使用现代硬件的人工神经网络的应用。
它允许开发、训练和使用比先前认为可能更大(更多层)的神经网络。
研究人员提出了成千上万种特定的神经网络作为对现有模型的修改或调整。有时完全是新的方法。
作为一名实践者,我建议等到模型变得普遍适用时再进行操作。从每天或每周发布的大量出版物的噪音中,很难弄清楚什么工作正常。
一般来说,我建议您关注三类人工神经网络。他们是:
多层感知器(MLP)
卷积神经网络(CNN)
递归神经网络(RNN)
这三类网络提供了很大的灵活性,并且经过几十年的实践证明,它们在广泛的问题中是有用的和可靠的。它们也有许多子类型来帮助专门针对预测问题的不同框架和不同数据集的特性。
现在我们已经知道了应该关注哪些网络,让我们看看何时可以使用每类神经网络。
何时使用多层感知器?
多层感知器,简称MLP,是神经网络的经典类型。
它们由一层或多层神经元组成。数据被馈送到输入层,可能存在一个或多个提供抽象级别的隐藏层,并且在输出层(也称为可见层)上进行预测。
有关MLP的更多细节,请参阅帖子:
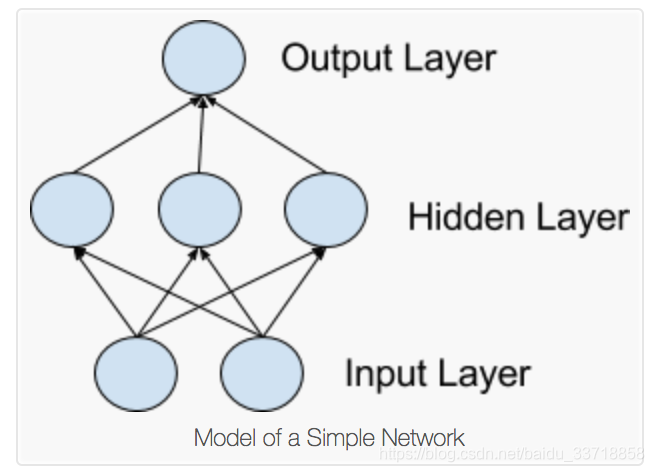
MLP适用于分类预测问题,其中输入被分配一个类或标签。
它们也适用于回归预测问题,其中给定一组输入对实值量进行预测。数据通常以表格格式提供,如您在CSV文件或电子表格中看到的那样。
使用MLP用于:
表格式数据集
分类预测问题
回归预测问题
它们非常灵活,通常可用于学习从输入到输出的映射。
这种灵活性允许将它们应用于其他类型的数据。例如,可以将图像的像素减少到一长行数据,并将其输入给MLP。文档的单词也可以减少为一长行数据,并输入给MLP。即使时间序列预测问题的滞后观测值也可以减少为长数据行并输入给MLP。
因此,如果您的数据不是表格式数据集,例如图像、文档或时间序列,那么我建议至少测试一个MLP。这些结果可以用作比较基准点,以确认其他可能看起来更适合增值的模型。
尝试MLPs 在:
图像数据
文本数据
时间序列数据
其他类型的数据
何时使用卷积神经网络?
卷积神经网络(CNN)被设计成将图像数据映射到输出变量。
它们被证明是如此的有效,以至于对于涉及图像数据作为输入的任何类型的预测问题,它们都是可行的方法。
有关CNN的更多详细信息,请参阅帖子:
使用CNN的好处是它们开发二维图像的内部表示的能力。这允许模型学习数据中不同结构中的位置和比例,这对于处理图像非常重要。
使用CNN用于:
图像数据
分类预测问题
回归预测问题
更一般地,CNN能够很好地处理具有空间关系的数据。
CNN输入传统上是二维的,字段或矩阵,但也可以改变为一维,允许它开发一维序列的内部表示。
这允许CNN更一般地用于具有空间关系的其他类型的数据。例如,文本文档中的单词之间存在顺序关系。时间序列的时间步长是有序的关系。
尽管没有专门针对非图像数据开发,CNN在诸如情感分析中使用的文档分类和相关问题方面取得了最先进的结果。
试试CNN:
文本数据
时间序列数据
序列输入数据
何时使用递归神经网络?
递归神经网络(RNNs)被设计成处理序列预测问题。
序列预测问题有多种形式,最好用所支持的输入和输出类型来描述。
序列预测问题的一些示例包括:
一对多:作为输入的观察映射到多个步骤的输出序列。(也就是用一步观测值往后预测多步)
多对一:作为输入映射到类或数量预测的多个步骤的序列。(多步观测值预测一个类别或一步)
多对多:作为输入的多个步骤的序列,映射到具有多个步骤作为输出的序列。(多步观测值预测多步)
多对多问题通常被称为序列对序列,或简称seq2seq。
有关序列预测问题类型的详细信息,请参阅后文:
传统上,递归神经网络很难训练。
长短期记忆网络,或者LSTM,网络可能是最成功的RNN,因为它克服了训练循环网络的问题,并且反过来已经在广泛的应用中使用。
有关RNN的详细信息,请参阅帖子:
一般来说,RNN和LSTM在处理单词和段落序列(通常称为自然语言处理)时获得了最大的成功。
这包括文本序列和以时间序列表示的口语序列。它们也被用作需要序列输出的生成模型,不仅用于文本,还用于生成手写等应用程序。
使用RNN用于:
文本数据
语音数据
分类预测问题
回归预测问题
生成模型
如您在CSV文件或电子表格中看到的,递归神经网络不适合于表格式数据集。它们也不适合于图像数据输入。
不要使用RNN用于:
表格数据
图像数据
RNN和LSTM已经在时间序列预测问题上进行了测试,但至少可以说结果很差。自回归方法,甚至线性方法通常表现得更好。LSTM常常被应用于相同数据的简单MLP所超越。
有关此主题的更多信息,请参阅帖子:
然而,它仍然是一个活跃的领域。
也许试试RNNs:
时间序列数据
混合网络模型
CNN或RNN模型很少单独使用。
这些类型的网络在更广泛的模型中用作层,该模型还具有一个或多个MLP层。从技术上讲,这是一种混合型的神经网络结构。
也许最有趣的工作来自于将不同类型的网络混合到混合模型中。
例如,考虑一个模型,该模型使用一个层堆栈,在输入端有一个CNN,在中间有一个LSTM,在输出端有一个MLP。这样的模型可以读取图像输入序列,例如视频,并生成预测。这叫做CNN LSTM architecture.
网络类型还可以堆叠在特定的体系结构中以解锁新功能,例如使用非常深的CNN和MLP网络的可重用图像识别模型,这些网络可以添加到新的LSTM模型中,并用于照片的标题。此外,编码器-解码器LSTM网络,可用于具有不同长度的输入和输出序列。
首先要清楚地考虑您和您的团队从项目中需要什么,然后寻找满足您特定项目需求的网络体系结构(或开发网络体系结构)。
要获得帮助您思考数据和预测问题的良好框架,请参阅帖子:
进一步阅读
如果您希望深入研究,本节将提供关于这个主题的更多资源。
- What Is Deep Learning?
- Crash Course On Multi-Layer Perceptron Neural Networks
- Crash Course in Convolutional Neural Networks for Machine Learning
- Crash Course in Recurrent Neural Networks for Deep Learning
- Gentle Introduction to Models for Sequence Prediction with Recurrent Neural Networks
- How to Define Your Machine Learning Problem
总结
在这篇文章中,您发现了三种主要人工神经网络的建议用途。
具体来说,你学到了:
在处理预测建模问题时,需要关注哪种类型的神经网络。
何时使用、不使用,以及可能的尝试在项目中使用MLP、CNN和RNN。
在选择模型之前,要考虑使用混合模型,并清楚地了解项目目标。



















 1694
1694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









