




今天,PPIO 上线 Qwen3-VL,这是迄今为止 Qwen 系列中最强大的视觉理解模型。
Qwen3-VL 提供 Dense 和 MoE 两种架构,可从边缘设备扩展到云端部署,并配备 Instruct 版本和推理增强的 Thinking 版本,以实现灵活的按需部署。
在线体验地址:
https://ppio.com/llm/qwen-qwen3-vl-235b-a22b-instruct
https://ppio.com/llm/qwen-qwen3-vl-235b-a22b-thinking
Qwen3-VL:
“看懂、理解并响应世界”的视觉理解模型
Qwen3-VL 是一款真正实现“看懂世界、理解事件、做出行动”的视觉理解模型,支持 2 小时视频精确定位(如“第 15 分钟穿红衣者做了什么”),OCR 语言从 19 种扩展至 32 种,生僻字、古籍、倾斜文本识别率显著提升。
这一代产品在各个方面都实现了全面升级:卓越的文本理解与生成能力、更深层的视觉感知与推理能力、扩展的上下文长度、增强的空间和视频动态理解能力,以及更强的智能体交互能力。
该模型原生支持 256K 上下文,可扩展至 100 万 token,适配超长视频与文档分析。
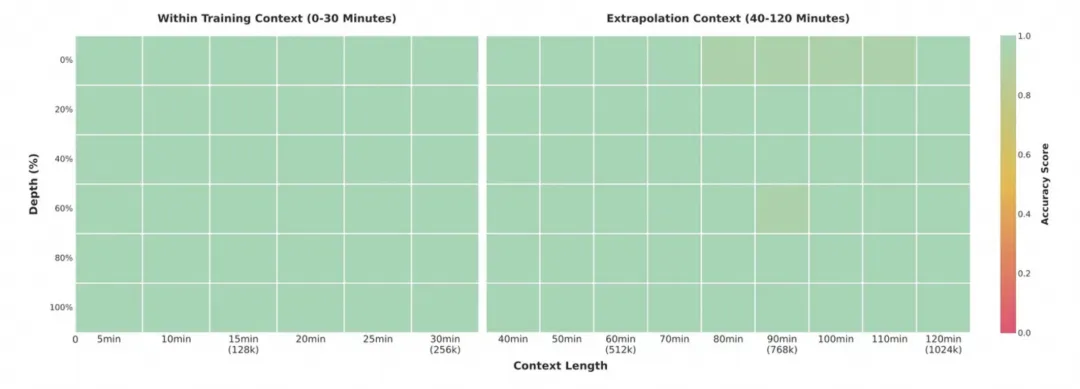
2小时“视频大海捞针”测试 ,256K 内定位准确率100%,1M仍达99.5%。
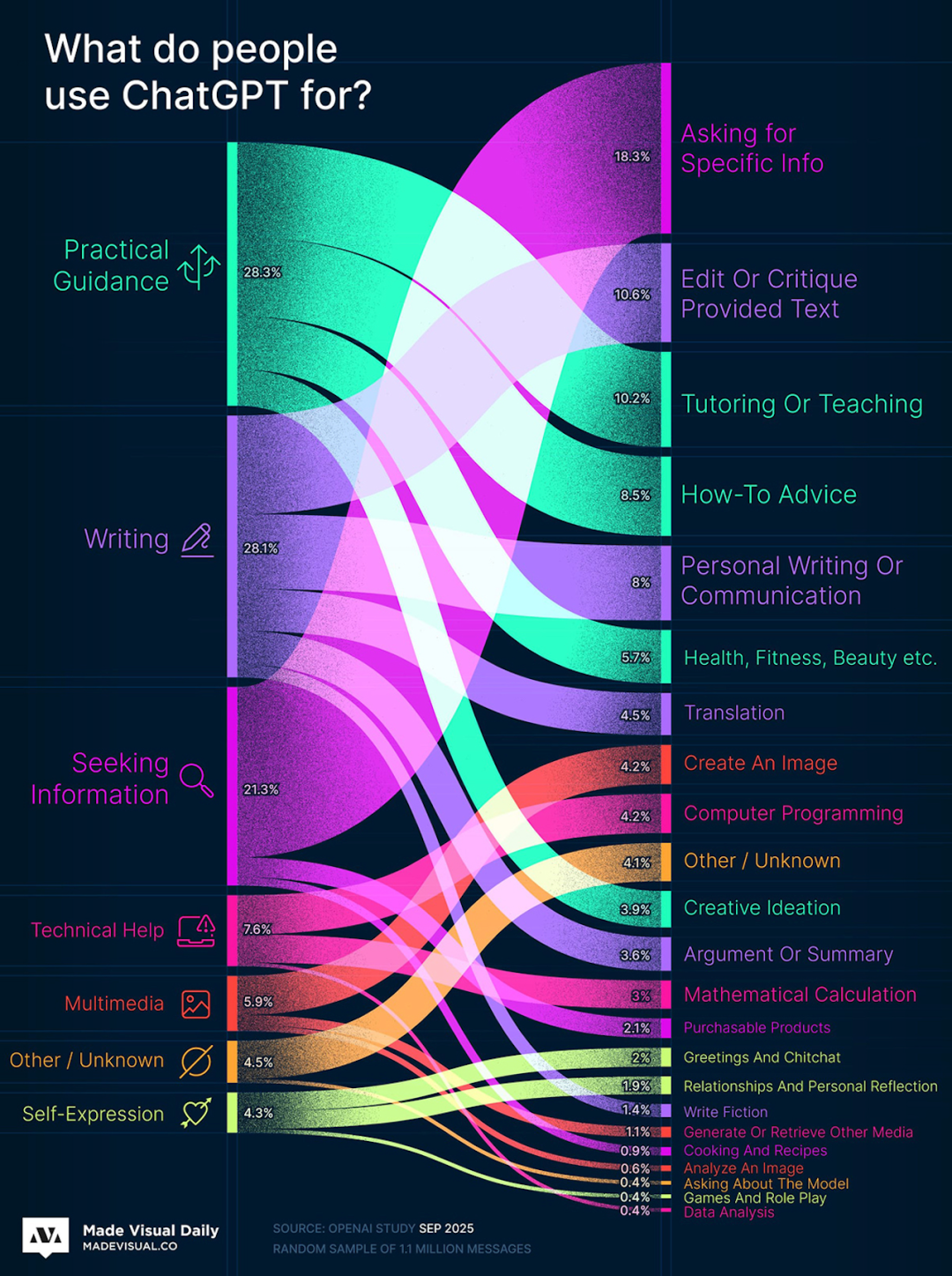
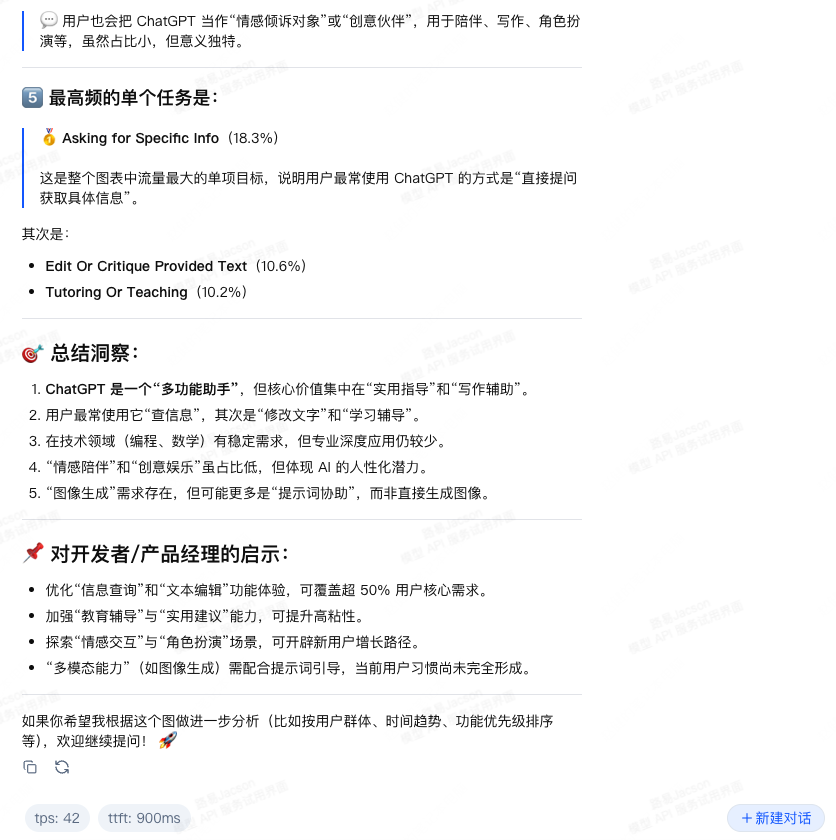
我将一张“人们用 ChatGPT 做什么”的可视化图表发给 Qwen3-VL 让其解读,结果如下:


现在,你可以到 PPIO 官网在线体验 Qwen3-VL 了。如果你是新用户,在点击阅读原文填写邀请码【LYYQD1】注册,可得 15 元代金券。
最后,我们整理了 20 余篇 Agent 相关的报告资料,可扫下图二维码下载,以及加入社群交流。




















 499
499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









