




 本文详细介绍了无监督学习中的聚类算法,重点讲解了K均值聚类及其改进版二分K-均值聚类。通过实例演示了算法的实现过程,并对比了两种算法的效果。
本文详细介绍了无监督学习中的聚类算法,重点讲解了K均值聚类及其改进版二分K-均值聚类。通过实例演示了算法的实现过程,并对比了两种算法的效果。
一、无监督学习
无监督学习是机器学习算法中的一种。监督学习的目的主要是对数据进行分类和回归预测,它主要是通过已知推测未知,大部分监督学习算法有一个训练模型的过程;相对于监督学习,无监督学习则是主要着重于数据的分布特点,与有监督学习不同,无监督学习并没有训练的过程。
二、 聚类
针对给定的样本数据,聚类算法会根据它们的特征相似度或距离,把相似的数据划分为若干个簇中。相似的样本划分到相同的簇中, 不相似的样本划分到不同的簇。聚类处理数据的过程也是从未知到已知的过程,因为聚类算法在事先并不知道聚类得到的簇的特点和样本的分布。
k-means属于无监督学习中聚类算法的一种。
三、 k均值聚类算法
3.1 k-means
k均值聚类算法将样本集划分为k个簇,把每个样本数据划分到距离最近的簇中,且每个样本仅属于一个类,此为k均值聚类算法。k-mean算法属于硬聚类,即每个样本只能属于一个簇。
聚合聚类需要预先考虑以下几个要素:
- 距离或相似度;
- 合并规则;
- 停止条件。
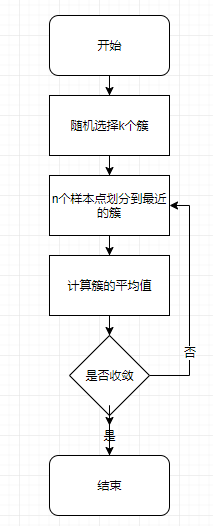
3.2 步骤
- 随机选择k个簇作为质心(需要保证这k个簇的特征值在样本集特征值的范围之内);
- 把n个样本点划分到距离最近的簇中;
- 计算每个簇的平均值。
- 判断是否收敛,如果没有收敛,则从步骤2开始。
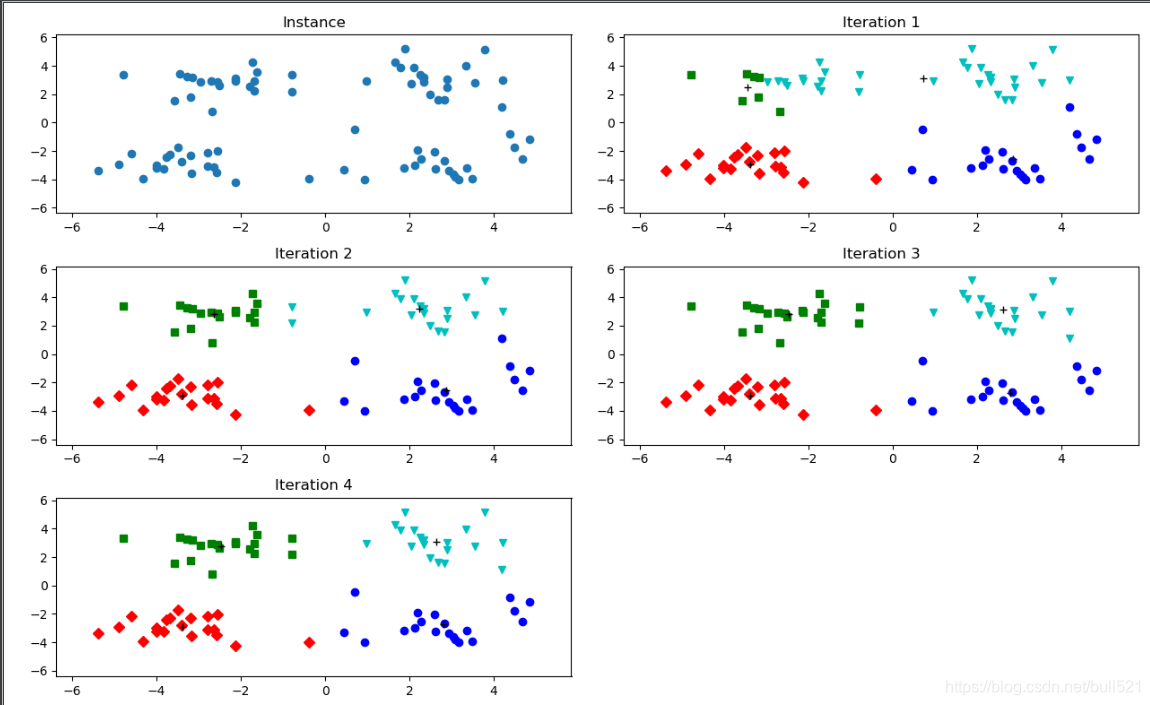
通过图2可以了解到,由于第三张图和第四张图未发生变化,则表示此时的簇已经收敛。
3.3 实现
from numpy import *
from matplotlib import pyplot as plt
import matplotlib
def load_data_set(filename):
data_matrix = []
with open(filename) as fp:
for line in fp.readlines():
# 多个浮点型的列
data = line.strip().split('\t')
float_data = [float(datum) for datum in data]
data_matrix.append(float_data)
return data_matrixload_data_set函数用于将文本文件导入成一个列表中。
def euclidean_distance(vec_a, vec_b):
"""计算两个向量的欧式距离"""
return sqrt(sum(power(vec_a - vec_b, 2)))距离的计算有很多种选择,比如闵可夫斯基距离、马氏距离等,不同的距离选择会使得计算
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









