




 本文介绍了数据预处理的方法,包括StandardScaler、MinMaxScaler、RobustScaler和Normalizer。通过实例展示它们如何改变数据分布,并指出预处理对于提高模型准确率的重要性。在未预处理的数据集上,MLP模型得分仅为0.31,但经过MinMaxScaler预处理后,模型准确率提升至0.96。
本文介绍了数据预处理的方法,包括StandardScaler、MinMaxScaler、RobustScaler和Normalizer。通过实例展示它们如何改变数据分布,并指出预处理对于提高模型准确率的重要性。在未预处理的数据集上,MLP模型得分仅为0.31,但经过MinMaxScaler预处理后,模型准确率提升至0.96。
1、预处理方法
1.1 StandardScaler
StandardScaler方法的原理是将所有数据的特征值转换为均值为0,方差为1的状态,也就是标准正态分布。这样可以确保数据的“大小”是一致的,更有利于模型的训练。
使用方法如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.preprocessing import StandardScaler
#创造数据
X,y = make_blobs(n_samples=40,centers=2,random_state=50,cluster_std=2)
scaler = StandardScaler()
X_scalered = scaler.fit_transform(X)
#作图
plt.scatter(X_scalered[:,0],X_scalered[:,1],c=y,cmap=plt.cm.cool)
plt.title("StandardScaler")
plt.show()
运行结果如下:

从上图可以看到所有的数据的特征值1的值都在-2到3之间,而特征值2的值都在-3到2之间了。
1.2MinMaxScaler
MinMaxScaler对数据的缩放主要在于将所有数据的特征值都转换到0到1之间。可以想象成将数据都压进了一个长和宽都是1的 方格子当中,这样也会让模型训练的速度更快并且准确率更高。
用法如下:
from sklearn.preprocessing import MinMaxScaler
X_2 = MinMaxScaler().fit_transform(X)
plt.scatter(X_2[:,0],X_2[:,1],c=y,cmap=plt.cm.cool)
plt.title("MinMaxScaler")
plt.show()
运行结果如下:
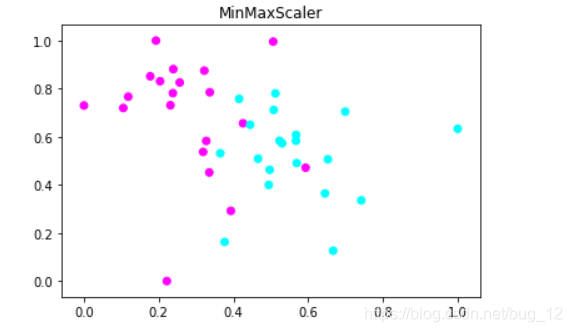
图中可以清楚的看到特征值1和2的数值的范围都被缩放到了0到1之间。
1.3 RobustScaler
RobustScaler方法的工作原理和StandardScaler类似,只不多不是用均值和方差,而是用中位数和四分数。简单的理解就可以将之叫为“粗暴缩放”,直接将一些异常值踢出去,有点类似于评委打分时说的“去掉一个最高分,去掉一个最低分”的情况。
使用方法如下:
from sklearn.preprocessing import RobustScaler
X_3 = RobustScaler().fit_transform(X)
plt.scatter(X_3[:,0],X_3[:,1],c=y,cmap=plt.cm.cool)
plt.title("RobustScaler")
plt.show()
运行结果如下:
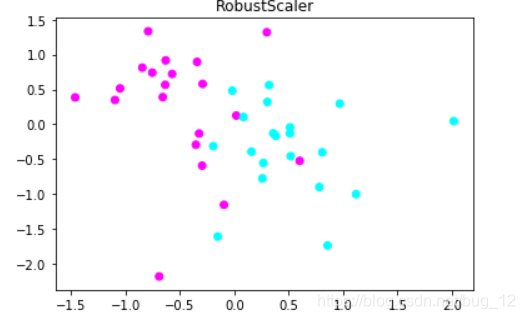
从图中可以看到,RobustScaler将数据的特征1控制到了-1.5到2之间,而特征2控制在了-2到1.5之间,和StandardScaler非常类似。
1.4 Normalizer
Normalizer主要就是在只想保留数据特征向量的方向,而忽略其数值的时候使用的。它将所有样本的特征向量转化为欧几里得距离为1,也就是说将数据的分布变为一个半径为1的圆或是一个球。
使用方法如下:
from sklearn.preprocessing import Normalizer
X_4 = Normalizer().fit_transform(X)
plt.scatter(X_4[:,0],X_4[:,1],c=y,cmap=plt.cm.cool)
plt.title("Normalizer")
plt.show()
运行结果如下:
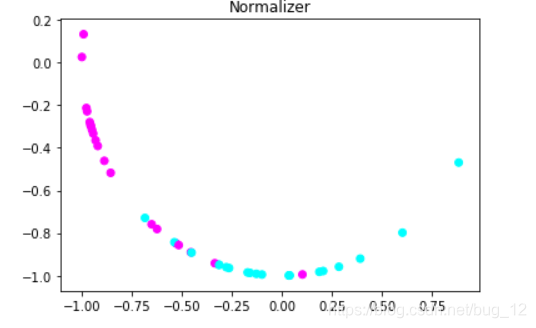
从图中可以看到基本数据变化很大,变成了一个弧形。
2 预处理实战
下面通过对一个进行酒的数据集进行预处理,看是否能够提高模型的准确率。
在没有进行预处理的数据集,其训练的模型得分如下:
from sklearn.datasets import load_wine
from sklearn.preprocessing import MinMaxScaler
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
#获取数据
wine = load_wine()
#建立测试集、训练集
X,y = wine.data,wine.target
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=60)
mlp = MLPClassifier(solver='lbfgs',hidden_layer_sizes=[100,100],max_iter=400,random_state=60)
mlp.fit(X_train,y_train)
#测试模型得分
print("==========================")
print("模型得分为:{:.2f}".format(mlp.score(X_test,y_test)))
print("==========================")

可以看到使用MLP算法对于为预处理的数据集进行训练,准确率只有很小的0.31.
使用MinMaxScaler对数据集进行预处理后的数据集如下:
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
mlp = MLPClassifier(solver='lbfgs',hidden_layer_sizes=[100,100],max_iter=400,random_state=60)
mlp.fit(X_train_scaled,y_train)
#测试模型得分
print("==========================")
print("模型得分为:{:.2f}".format(mlp.score(X_test_scaled,y_test)))
print("==========================")
得分如下:

可以看到进行预处理之后,模型的准确率相对没有处理前的0.31提高到了0.96,可以说是飞一般的提升了。

















 3787
3787

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









