






EXPLORING COMPLEMENTARY FEATURES IN MULTI-MODAL SPEECH EMOTION RECOGNITION
第一章 语音增强之《探索多模态语音情感识别中的互补特征》
文章目录
前言
语音新手入门,学习读懂论文。
本文作者机构是

一、做了什么
作者提出了一种新的模态敏感的多模态语音情感识别框架。
具体来讲,作者首先利用并行单模态编码器从每个模态的预训练特征中提炼情感相关信息。为了更好地融合多模态特征,我们开发了一组可学习的情感查询标记,利用转换器解码器中的交叉注意机制,从精炼的声学和语言特征中收集情感信息。针对多模态方法中存在的模态偏差问题,引入随机模态掩蔽训练策略,最大限度地利用各模态中的情感信息,缓解多模态偏差问题。
二、动机
很少有研究关注各自情态的预训练特征中隐含的互补情感信息。在实践中,我们发现多模态方法倾向于主要依靠语言信息而忽略音频信号来进行情绪分类。一种假设是,情感信息存在于预先训练的语言特征中,而存在于音频特征的深层空间中;因此,网络可能会迅速向文本方向收敛。然而,音频信息至少应该和文本一样重要,甚至更重要。
三、挑战
1.如何有效地提取各自模态的预训练特征中隐含的互补情感信息。
2.倾向于主要使用文本中的情感特征来识别情感。
四、方法
1.模型框架图
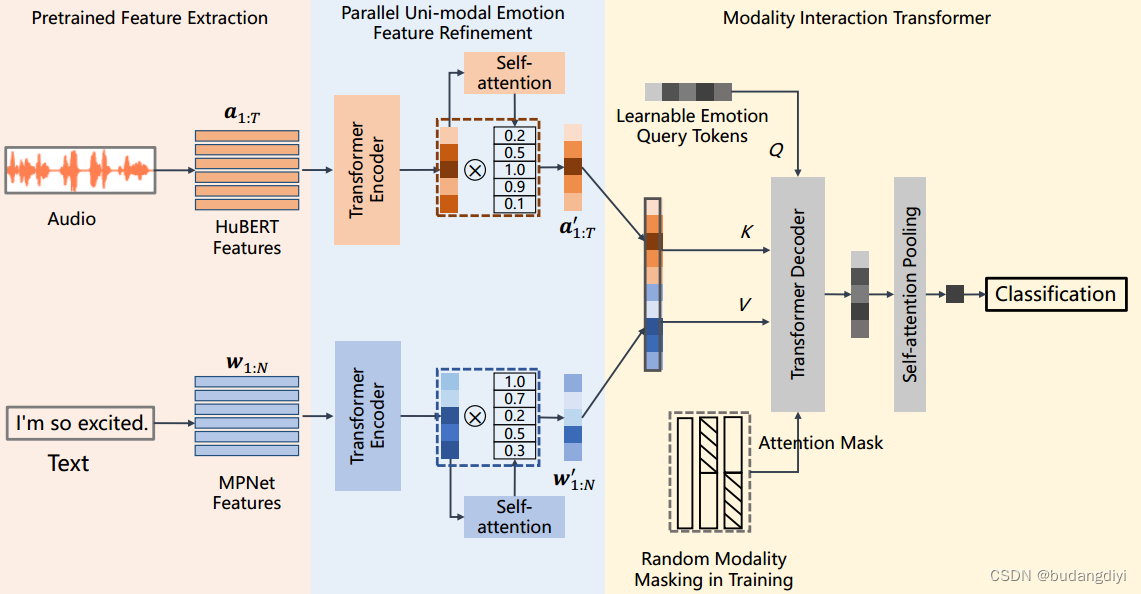
模态敏感多模式语音情感识别框架(MSMSER)
作者利用预训练的HuBERT和MPNet分别提取声学和语言特征。为了提炼预训练嵌入中的情绪信息,作者开发了两个并行的单模态情绪特征提炼编码器,然后是自注意模块。然后,作者提出了一种情态交互转换器,通过可学习的情感查询标记来整合两种情态的情感特征。此外,作者设计了一种随机模态掩蔽训练策略,通过在训练中随机掩蔽音频或文本嵌入,迫使模型充分感知每种模态的情感信息。
2.Uni-modal Emotion Feature Refinement(单模态情感特征细化)
由于HuBERT和MPNet都没有经过情绪识别的预训练,作者引入了两个并行的单模态变压器编码器来利用自监督特征中的情绪信息。得到编码后的情感相关特征。利用自注意模块对编码特征进行进一步细化,突出各自模态中的典型情绪框架。自注意模块由一个双层多层感知器(MLP)和一个Sigmoid组成。
3.Modality Interaction Transformer(模态交互Transformer)
查询标记用作变换器解码器中的查询(Q),而组合的多模态特征则用作键(K)和值(V),L是查询标记的数量。经过交叉注意力后,输出的L个情感查询标记包含互补的情感特征。然后,我们使用自注意池化层将L个标记合并为一个,并将其发送到一个2层的MLP进行分类。
4.Random Modality Masking(随机模态掩蔽)
作者在训练模型时引入了随机模态掩蔽策略(RMM)。在训练的早期阶段,作者通过随机屏蔽音频或文本嵌入来使作者的模型更加关注单模态特征。在后期,该模型的重点是获取互补的多模态情感特征。作者引入了一个超参数p,它表示模型在每个训练样本中应用RMM的概率。RMM屏蔽文本特征的概率为0.6,屏蔽音频特征的概率为0.4。在作者的实验中,p从0.8开始,随着训练的继续衰减到0。
五、实验评价
1.数据集
IEMOCAP数据集,该数据集包含五个会话,每个会话都记录在一名男性和一名女性演讲者之间的对话中。作者考虑了5531种情绪的声学话语,分别是中性、快乐(高兴和兴奋)、悲伤和愤怒。作者使用常用的加权准确率(WA)和非加权准确率(UA)作为评估指标。
2.结果
作者的方法在UA和WA方面分别比最先进的方法高出1.1%和0.9%
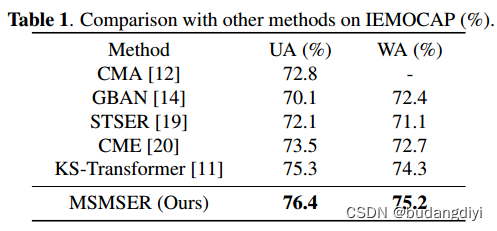
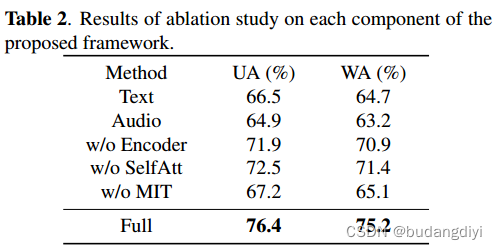
3.消融实验
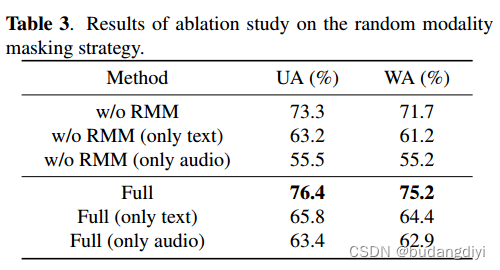
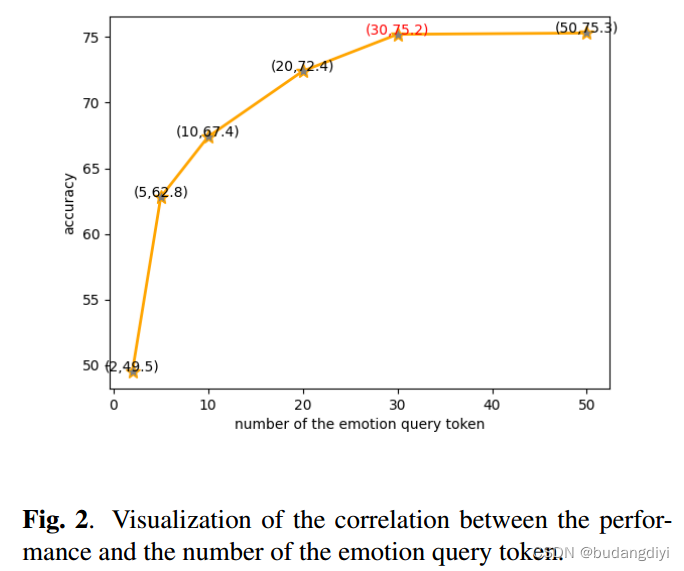
4.情感查询标记
对查询标记进行训练,以感知每种情态中的情感信息。在作者的实验中,将查询令牌的编号L设置为2、5、10、20、30和50。性能随着L的增加而增加。作者在最终模型中选择L = 30进行权衡。
六、结论
该方法为有效融合多模态特征提供了新的视角。在广泛使用的IEMOCAP数据集上进行的大量实验证明了该框架的优越性。我们计划在未来的工作中结合更多的方式来提高SER的性能。
源码
https://github.com/facebookresearch/fairseq
七、知识小结
MPNet,它既继承了BERT和XLNet的优点,又避免了它们的局限性。《MPNet: Masked and Permuted Pre-training for Language Understanding》
HuBERT,一种语音表示学习方法,它依赖于预测连续输入屏蔽段的K-means聚类分配。《HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units》



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











