






DBNet: A Dual-branch Network Architecture Processing on Spectrum and Waveform for Single-channel Speech Enhancement
第一章 语音增强之《DBNet:一种基于频谱和波形的双分支网络架构,用于单通道语音增强》
文章目录
前言
语音新手入门,学习读懂论文。
本文作者机构是

一、做了什么
在本文中,提出了一种新的实时框架,称为DBNet,它是一种具有交替互连的双分支结构。每个分支都包含一个具有跳过连接的编码器/解码器架构,并包含跳跃连接。这两个分支分别负责频谱和波形建模。采用桥接层在两个分支之间交换信息。
二、动机
在真实声环境中,提高受背景噪声和混响干扰的语音质量和清晰度是一项艰巨的任务。在过去的几年里,深度学习在语音增强方面显示出了巨大的潜力。
三、挑战
1.现实中噪声类型的多样性
2.窄带式噪声与语音耦合在一起,很难通过基于时域的增强方法解耦。
3.冲击式噪声难以通过基于频域的语音增强方法消除。
四、方法
1.模型图
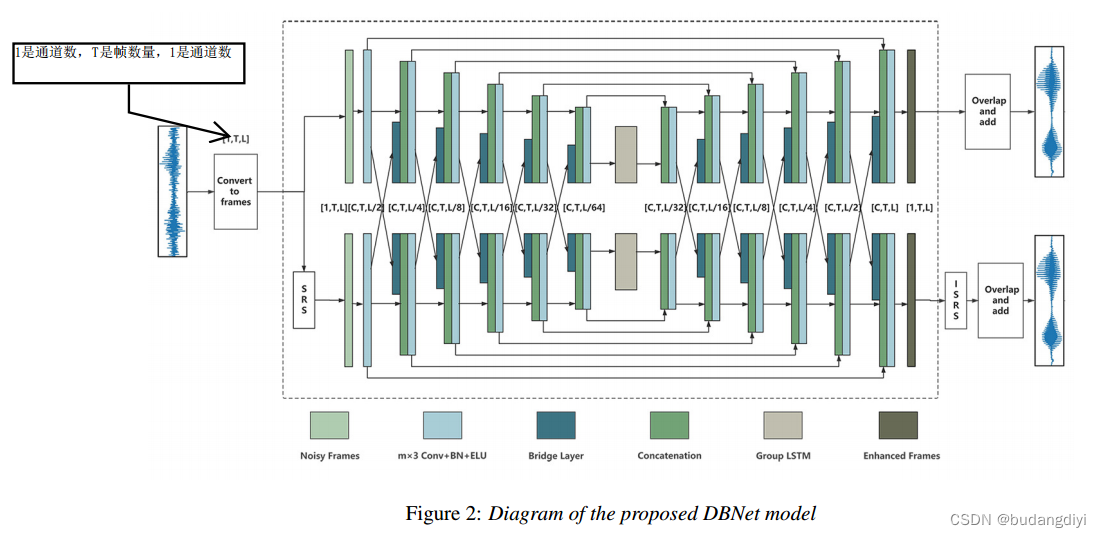
2. SRS模块
首先,SRS考虑了相位信息,提高了语音的可懂度和质量。其次,SRS是实数域内的一种频谱表示方法,而不是复数域,输入的所有元素都是实数。因此,它降低了建模的难度,并为我们模型的信息交互模块提供了便利。基于以上两个优点,本文采用了SRS作为我们的频域输入。
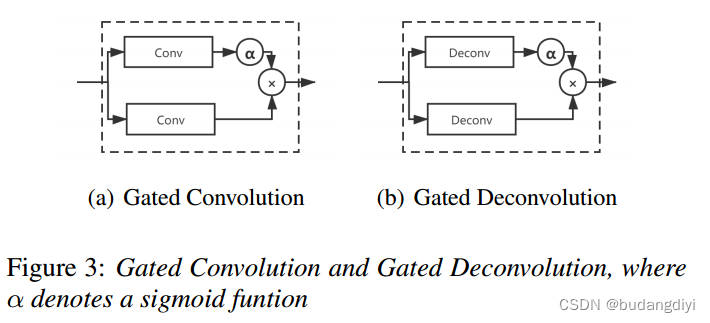
3. Gated Convolution and Group LSTM(门控卷积和组GLSTM)
Dauphin等改进了图像卷积建模中的掩模卷积,提出了门控卷积(GCNN),描述为:
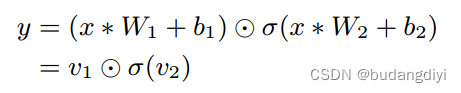
其中,W和b分别表示卷积核和偏置。∗和 分别表示卷积操作和逐元素乘法。σ表示非线性激活函数。GCNN可以通过为梯度提供线性路径来减少深度结构的梯度消失问题,因此用它代替了原始crn中的卷积。门控卷积的示意图如图3所示。
分别表示卷积操作和逐元素乘法。σ表示非线性激活函数。GCNN可以通过为梯度提供线性路径来减少深度结构的梯度消失问题,因此用它代替了原始crn中的卷积。门控卷积的示意图如图3所示。
Gao等[11]提出了一种分组递归神经网络(RNN)策略,在保证模型性能的同时降低了模型的复杂性。组RNN的处理过程如图4所示。
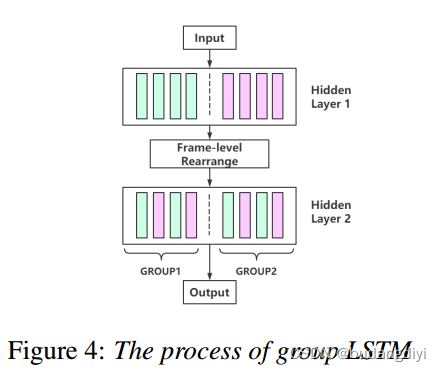
组LSTM包含两层RNN,每层有两个LSTM来学习每一组内的特征。在两层之间,采用帧级重排的方式建立特征的组间关系,在一定程度上保证了组间相关性的利用。
4. 桥接层
桥接层是一个线性单元,负责将信息从一个分支转换到另一个分支。桥接层由两个与帧长度相同的独立向量组成。这两个向量分别负责信息从时域到频域的转换及其逆过程。我们取快速傅里叶变换(FFT)变量的实部作为这些可训练向量的初始化参数,以适应使用SRS作为频域表示的情况。
五、实验评价
1.实验条件
2.损失函数
早期的实验中,使用了基于STFT幅度的损失函数。
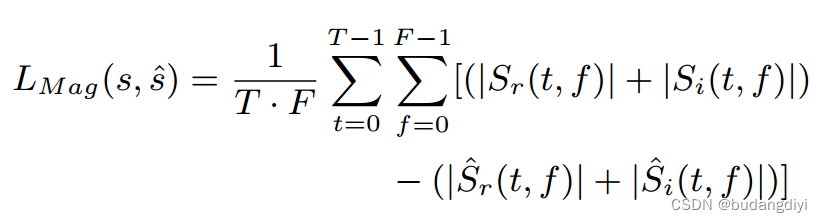
T和F分别表示时间帧数和频率维数,S和S分别表示S和S的stft。Sr和S^i分别表示S的实部和虚部。
网络的输出包含两个增强的话语,一个来自时间分支,另一个来自频率分支,它们是独立优化的。因此,总损失定义为:
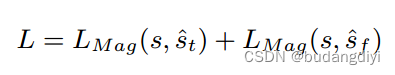
然而,我们发现量级损失引入了大量未知的工件。虽然不影响客观评价分数,但会带来可怕的听觉感受。因此,在DNS Challenge中,将幅度损失替换为相位约束幅度损失(the phase constrained magnitude loss),并在竞赛中取得了较好的主观评价分数。
3.数据集
在本研究中,我们在WSJ0 SI-84数据集[7]上评估了我们提出的模型的性能,该数据集包括来自83位说话者(42位男性和41位女性)的7138个话语。我们使用77位说话者的话语进行训练,其余的用于测试。我们使用了音效库中的10000个非语音声音(可在www.sound-ideas.com上获得)[13],并在{-5dB、-4dB、-3dB、-2dB、-1dB、 -0dB}均匀采样的信噪比下分别生成了320000和3000个语音,用于训练和验证。对于测试集,使用Auditec CD(可在http://www.auditec.com上获得)中的两种噪声(咿呀学语和自助餐厅)来生成300种混合,每种信噪比分别为-5dB, 0dB和5dB。
4.基线
在本研究中,我们将所提出的双分支网络与另外3个基线CRN、GCRN和AECNN进行了比较,结果如下:
CRN:它是一个在T-F域的随机卷积循环网络。该网络使用5个卷积层作为编码器,5个反卷积层作为解码器。
两个LSTM层用于序列建模。这个网络接收幅度作为输入。通道数减少,参数数为4.5M。
GCRN:它是一种用于复杂频谱映射的因果门控卷积循环网络。GCRN的结构与CRN相似,不同之处在于GCRN有两个解码器分别对实数和虚数进行建模。网络的输入是复数谱。我们保留了GCRN中的最佳配置,参数个数为9.76M。
AECNN:它是一个基于自编码器的时域全卷积神经网络。原始波形被分割成具有大时间帧大小(1.024秒)的帧。我们保留了AECNN的最佳配置。参数个数为18M。
DBNet:两个分支结构相同。编码器和解码器分别设置6个(解码)卷积块。每层通道数为64个。时间轴和频率轴分别设置内核大小(1,3)和步幅(1,2)。输入分别为时间支路的时间帧和频率支路的SRS。参数个数为2.9M。
5.评价指标
性能用两个客观指标来评估:短时客观可理解性(STOI)和语音质量的感知评价(PESQ)
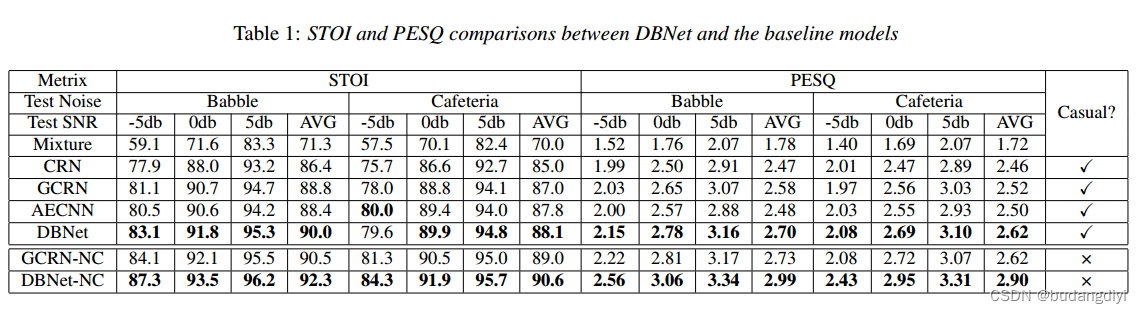
结果如表1所示,最好的结果用粗体标出。对于STOI, DBNet在除AECNN外的所有信噪比和噪声下都优于所有基线。然而,AECNN是一个基于大帧大小的模型,因此不适合实时场景。与GCRN相比,babble和自助餐厅的平均质量分别提高了1.20%和1.10%。对于PESQ, GCRN是最好的基线,对babble和cefeteria的平均改善分别为0.12和0.10。对于非因果系统,DBNetNC优于GCRN-NC, STOI平均提高1.7,PESQ平均提高0.27。
六、结论
在本研究中,我们提出了一种新的单通道语音增强系统,该系统由时域和频域两个去噪分支组成。结果表明,该模型在客观可理解性和质量分数方面优于其他先进模型。我们的工作表现优异是因为两个网络分支有不同的学习重点,从不同领域学习的特征可以相互补充。根据STFT的原理,时域的卷积相当于频域的直积。时域的运算更倾向于关注局部信息,而频域的运算更关注帧与帧之间的关系。两者的合理结合可以达到更好的性能。该模型参数较少,表明双支路结构提高了参数利用率。
七、知识小结
音频超分辨率:是指通过算法和技术,将低质量或低分辨率的音频信号恢复到高质量或高分辨率的过程。通过音频超分辨率技术,可以使得音频文件更加真实、逼真,并提供更好的听觉体验。
SRS(Shift Real Spectra)是一种时频表示方法。与传统的STFT相比,SRS在两个方面具有优势。首先,SRS考虑了相位信息。相位在语音信号中承载了重要的语义和听觉信息,因此将相位纳入考虑可以提高语音的可懂度和质量。其次,SRS是在实数域内进行频谱表示的方法,而不是复数域。这意味着SRS的输入是实数而非复数,减少了建模的难度,并且为模型的信息交互模块提供了便利。
门控卷积(Gated Convolution,GCNN)是一种卷积操作的变体,它引入了门控机制来调节卷积的输出。GCNN常用于处理序列数据,如文本和语音。门控卷积具有以下优势:
1.可以学习到输入序列中的长期依赖关系,有利于捕捉上下文信息。
2.门控机制可以选择性地过滤或强调不同位置的特征,提高模型的灵活性和表达能力。
3.相较于传统的卷积操作,门控卷积在处理序列数据中能够更好地保持输入序列的时序性。
“Overlap and add”(重叠相加)是一种数字信号处理中常用的方法,用于将重叠的信号片段进行相加以合成完整的信号。
Adam(Adaptive Moment Estimation)优化器是一种常用的梯度下降优化算法,用于在深度学习模型中更新参数以最小化损失函数。


















 2463
2463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











