




 本文介绍了机器学习的概念,包括语音识别、图像识别和围棋等应用场景。探讨了为何需要深度学习,特别是在计算机视觉领域的卓越表现。回顾了机器学习的历史,从早期的电子脑到深度学习的崛起,如SVM、随机森林,再到深度学习的复兴,如AlexNet、VGGNet和ResNet。文章最后讨论了计算机视觉的应用,如分类、定位和物体检测,并强调了深度学习在自动特征提取和避免手工特征工程方面的优势。
本文介绍了机器学习的概念,包括语音识别、图像识别和围棋等应用场景。探讨了为何需要深度学习,特别是在计算机视觉领域的卓越表现。回顾了机器学习的历史,从早期的电子脑到深度学习的崛起,如SVM、随机森林,再到深度学习的复兴,如AlexNet、VGGNet和ResNet。文章最后讨论了计算机视觉的应用,如分类、定位和物体检测,并强调了深度学习在自动特征提取和避免手工特征工程方面的优势。
机器学习
1、什么是机器学习?
机器学习等价于构造一个函数。举个例子,
语音识别
f(语音)=>语音
图像识别
f(图像)=>图像类别
围棋
f(围棋)=> 下一步落子位置
对话系统
机器学习:通过算法使得机器能从大量历史数据中学习规律从而对新的样本做预测。
2.为什么我们需要深度学习?
- 在几乎所有的计算机视觉任务的比赛中夺冠(分类识别, 目标检测, 图像分隔等等)
- 可以用于不同的领域(语言识别, 下围棋, 玩游戏, 预测比赛结果, 计算机视觉等等)
- 在特定数据集特定任务上面超过普通人类的能力活跃的社区, 大量的资源计算机
- 活跃的社区, 大量的资源
- 硬件软件技术的进步提供了技术能力支撑
3.机器学习历史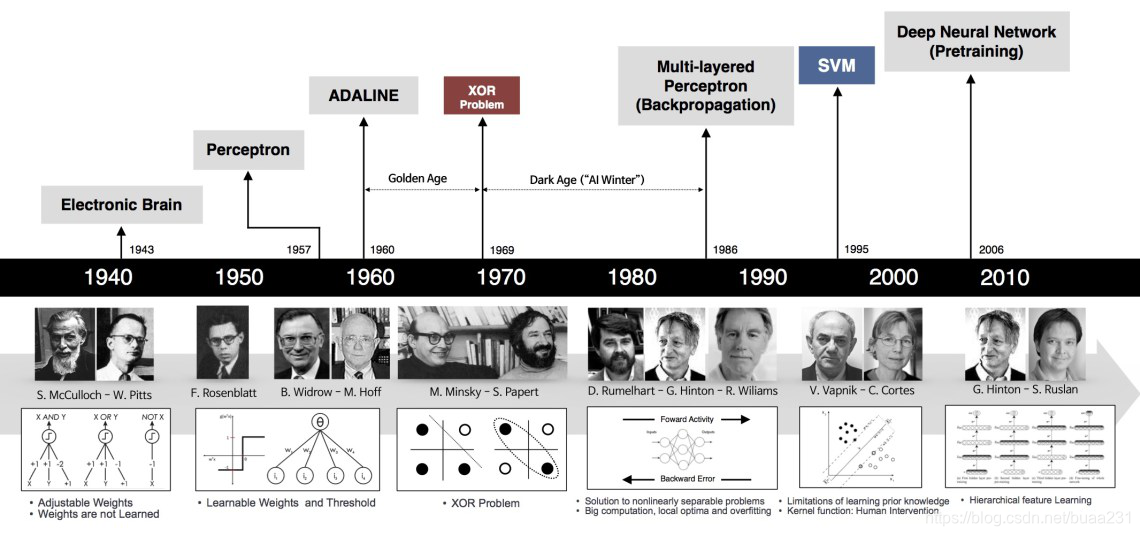
1940年提出Electronic Brain“电子脑”的概念,用电阻和电容等器件,模拟人类大脑,即神经元的工作方式。其过程为,预先设定好权值,输入电流,输出电压大于某个阈值则输出为真(激活),否则为假(抑制)。
1957年提出perceptron(感知机)。在电子脑的基础上,改进权值赋予方式,权值可以学习。
以上两种方式,有个致命的缺陷就是无法处理异或(XOR)的问题,即输入是(0,0)或(1,1)输出为0,输入是(0,1)或(1,0)输出为1。感知机只能模拟线性函数,对非线性函数一筹莫展。让世人对机器学习颇感失望,机器学习进入第一次寒冬。
直到80年代,有人提出Multi-layered Perceptron(多层感知机),一个神经元可以与多个神经元相连,形成复杂的网络。在此基础上,提出了非线性激活函数,作为分类器来说,可以产生非线性边界。当时还提出了BP算法、CNN网络。但是碍于当时软硬件技术的落后,多层感知机太耗费资源,效率很低,在当时并未得到很好发展。所以形成了第二次寒冬。
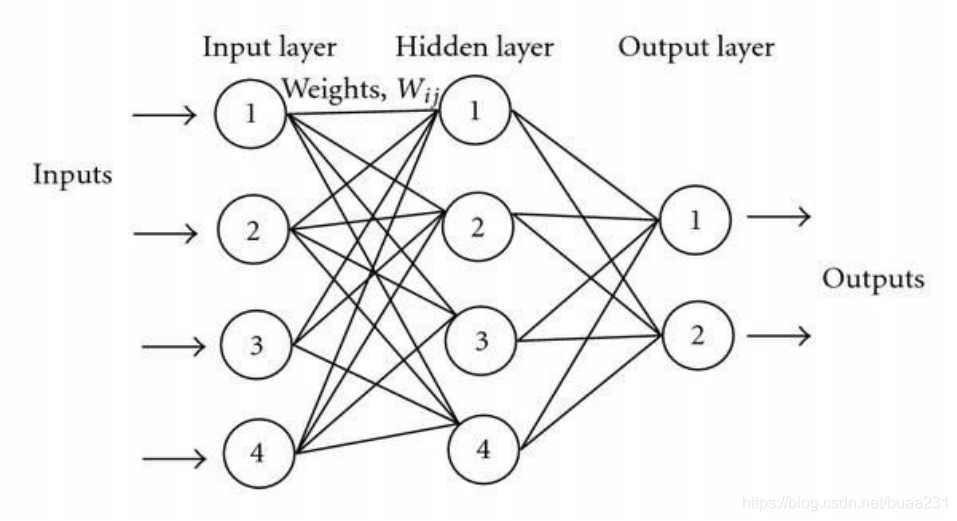
BP算法误差向后传递,使用梯度下降法进行优化,可以自动训练多层网络。
CNN网络训练参数大大减少,且更易于训练。
Yann Lecun 1989年利用CNN开发的手写体识别仅用了30次迭代,准确率达到92%。

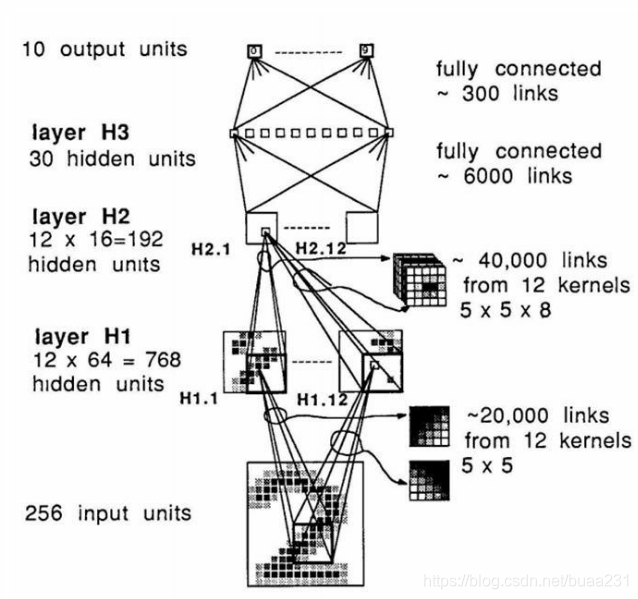
90年代,最火的算法是SVM(支持向量机)和Random Forrest(随机森林),因为这些不需要大量的资源。
2010年后,随着计算能力和软硬件技术的发展,深度学习再次回到热点。
2011 年深度学习引爆
更好的初始化新的激活函数ReLU更多的训练数据 (千万级别的ImageNet)更好的计算机硬件
深度学习是一个综合技术
卷积Conv-, 池化Pool- 和全连接层 Fully-Connected LayersReLU 激活函数更深的网络层次, 更多的参数新的网络层(DWConv, SPConv, Group Convolution)和结构(Skip Connection, Dense Connection)新的防止过拟合和技术(DropOut, Image Augmentation)更大的训练数据和计算基础设施 (千万级别的数据, GPU分布式计算)
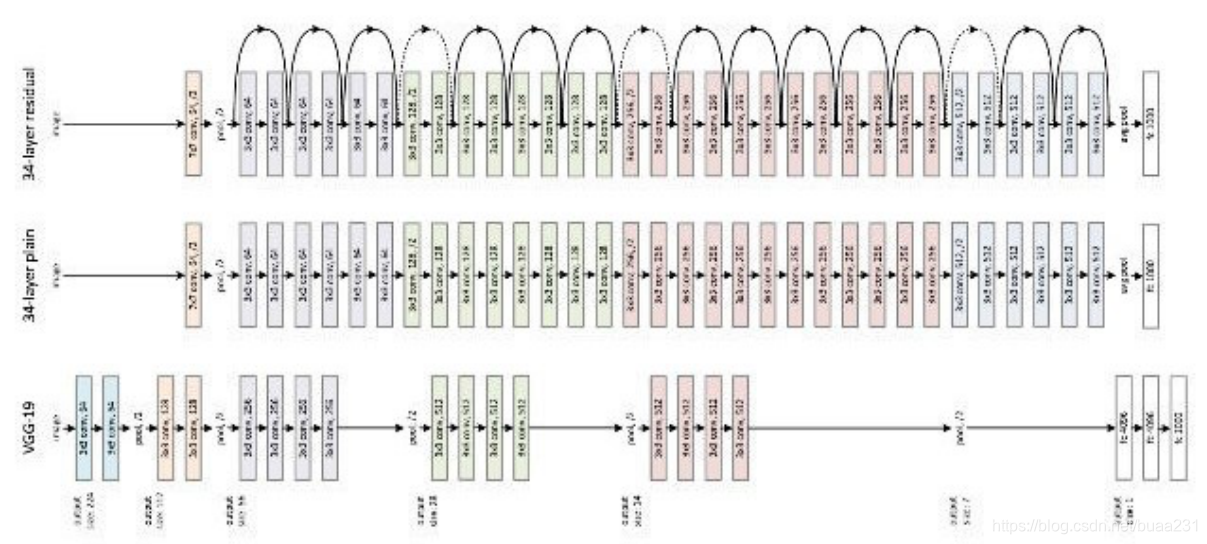
2012年AlexNet 62.378.344 个权值 (250MB),24 层
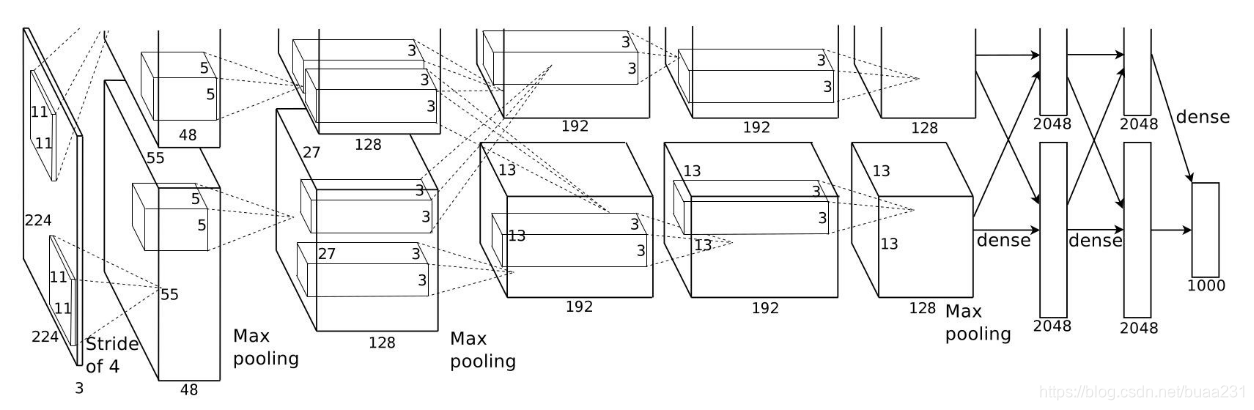
2013年 VGGNet 102.908.520 个权值 (412MB)23 层
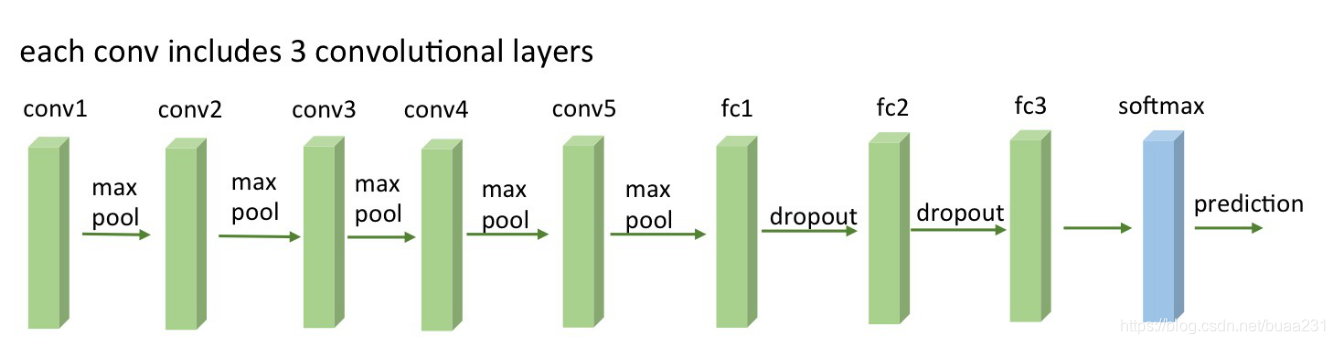
2014年GoogleNet 6.998.552 个权值 (28MB)143 层
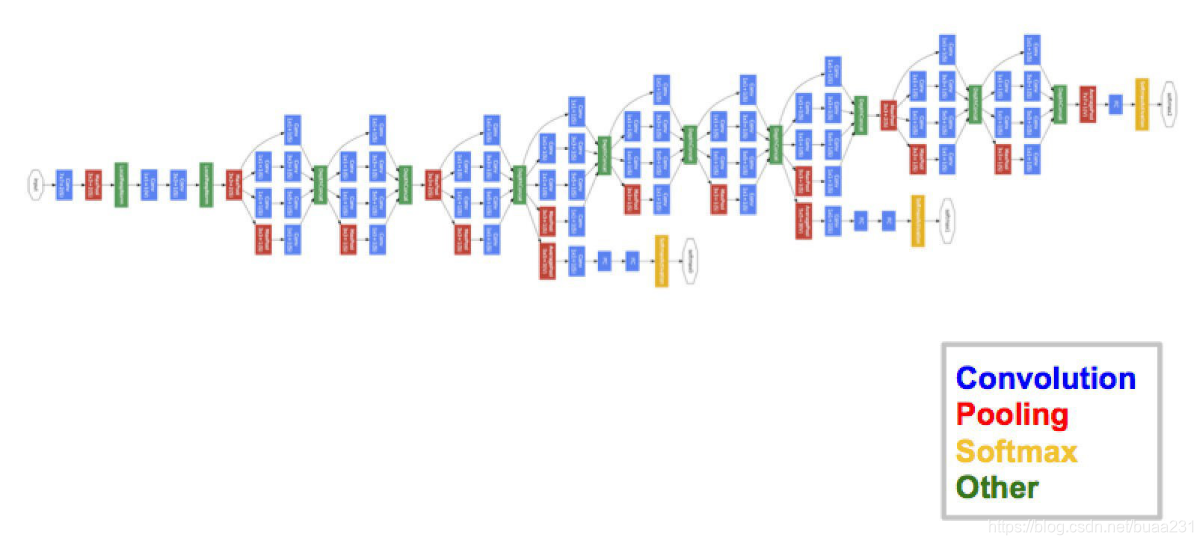
2015年ResNet 152层
计算机视觉中的应用
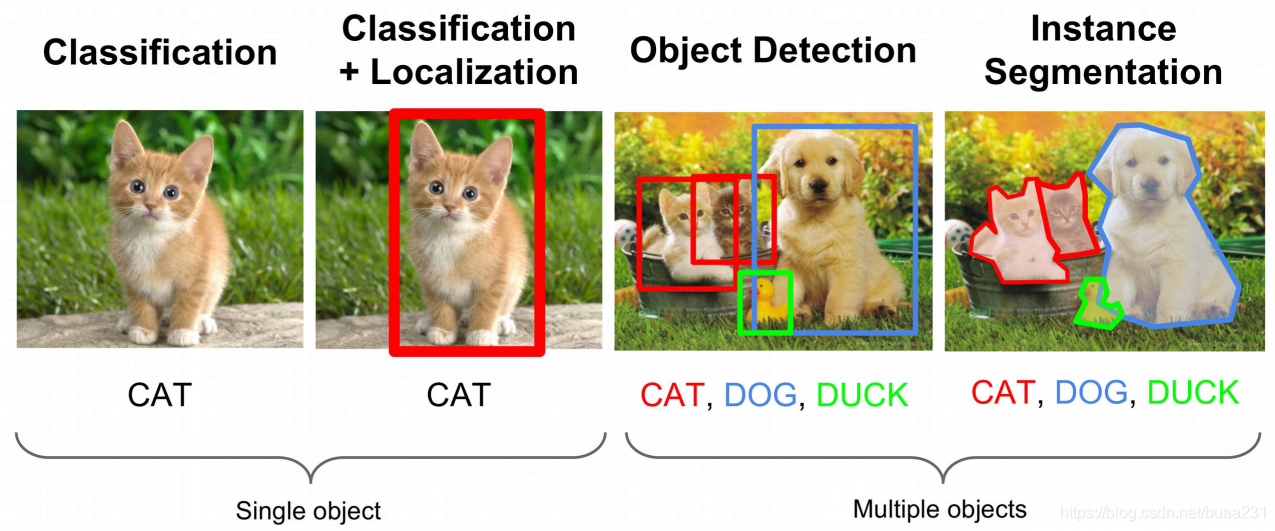
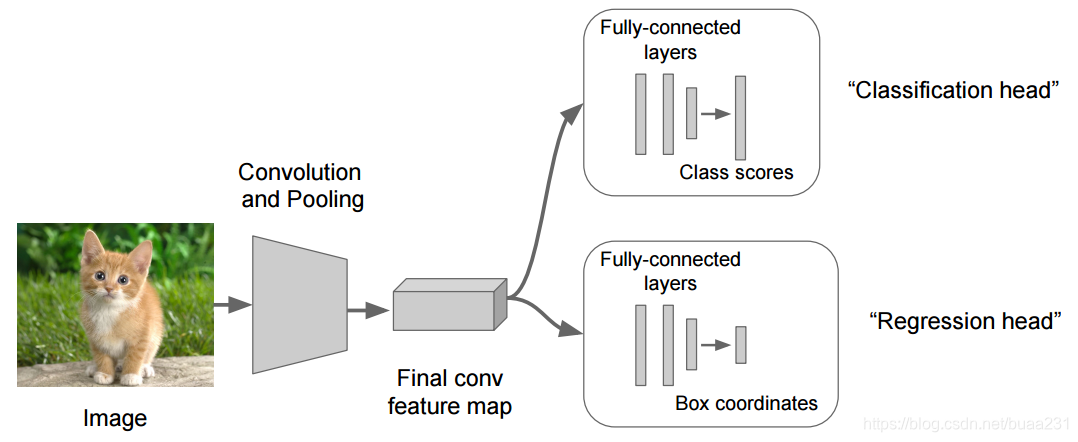
分类识别

定位
物体检测
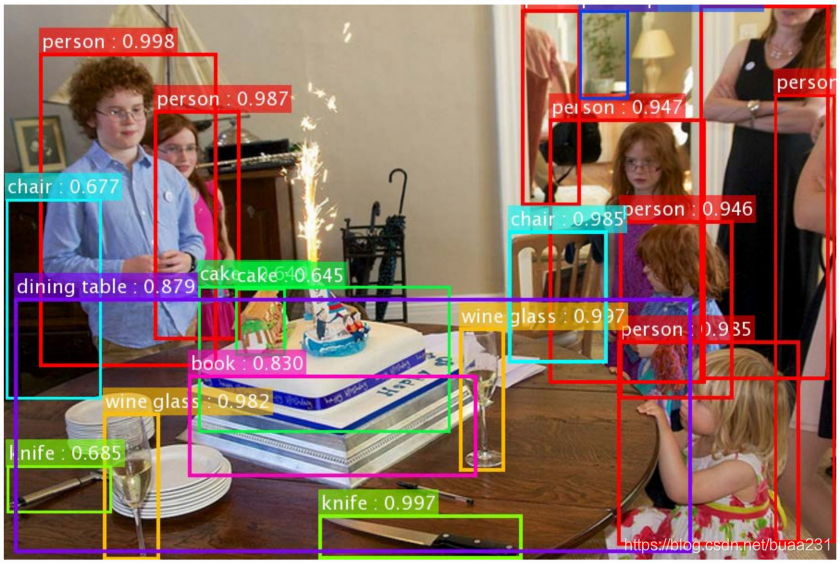
一幅图包含多个物体, 物体属于多种类别R-CNN, Faster R-CNN, Faster R-CNNYOLO SSD
更多应用:
- 压缩Auto-encoders,Self-organizing maps
- 生成图像描述 Image Captioning
- 结合递归神经网络NLP
- 图像风格化转移Image Stylization
- 基于内容的图像Image Retrieval
结论:
- 更强大,
- 自动从数据学习特征,
- 无需手工提取特征节约时间,
- 而且更好 (自动提取了空间和图像结合的特征, 人脑无法想象)
- 更深的网络具有较好的能力
- 需要防止过拟合
- 更大的数据量
- 数据质量
- 数据标注

















 5804
5804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









