







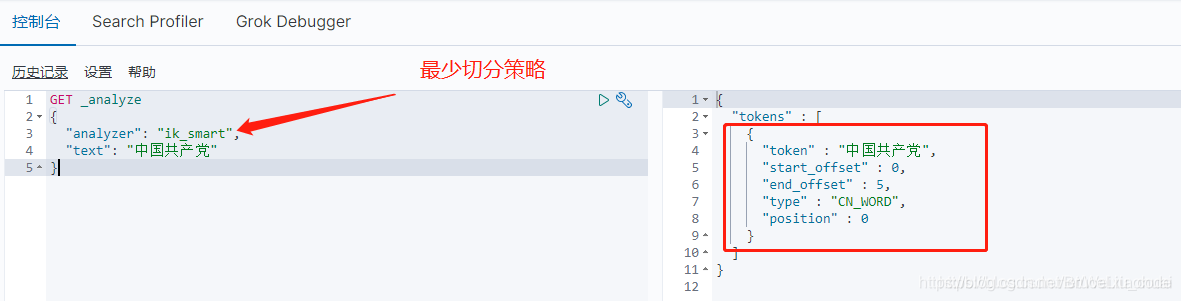
我们首先测试一下IK分词器的ik_smart最少切分策略。
GET _analyze
{
"analyzer": "ik_smart",
"text": "中国共产党"
}
可以看到,使用ik_smart最少切分策略时,kibana只帮我们分词为一个"中国共产党"一个词。
下面我们修改成ik_max_word最细粒度划分策略看看效果如何:
GET _analyze
{
"analyzer": "ik_max_word",
"text": "中国共产党"
}
如下就是IK分词器使用ik_max_word分词后的结果:
{
"tokens" : [
{
"token" : "中国共产党",
"start_offset" : 0,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "中国",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "国共",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "共产党",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "共产",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "党",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 5
}
]
}
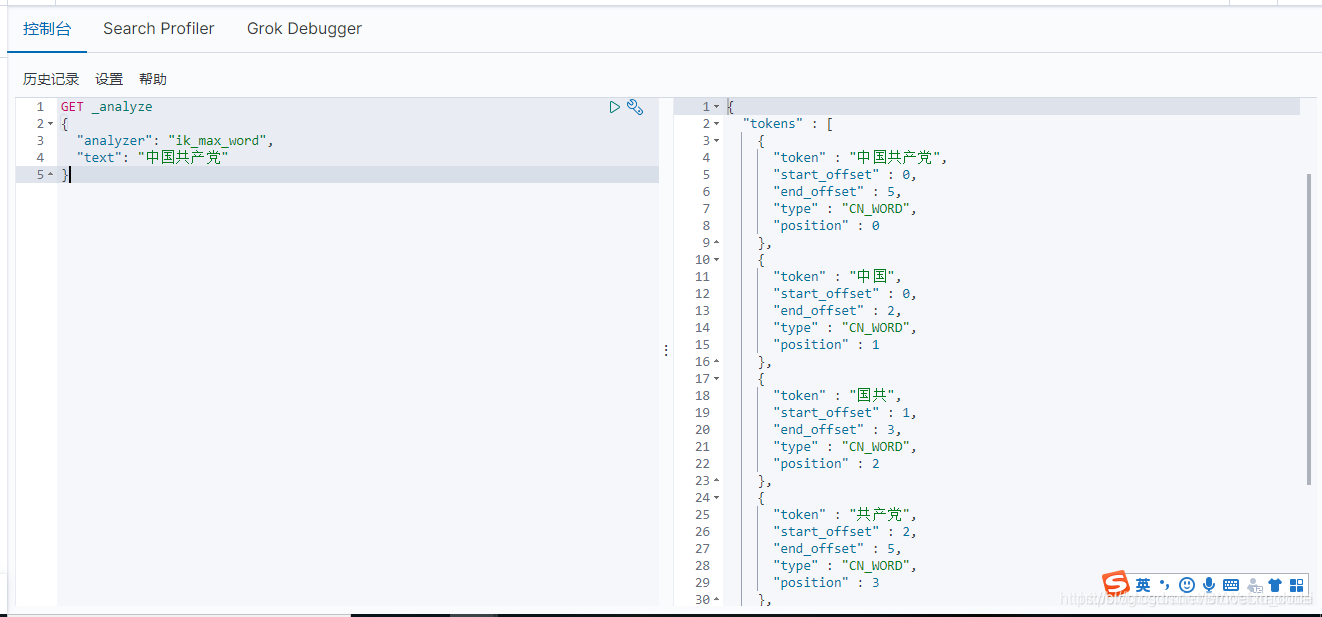
可以看到,IK分词器穷尽词库的可能,切分成了几个词。
下面我们再次修改一下分词的text:
GET _analyze
{
"analyzer": "ik_max_word",
"text": "我喜欢迪丽热巴"
}
分词结果如下:
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "喜欢",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "迪",
"start_offset" : 3,
"end_offset" : 4,
"type" : "CN_CHAR",
"position" : 2
},
{
"token" : "丽",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "热",
"start_offset" : 5,
"end_offset" : 6,
"type" : "CN_CHAR",
"position" : 4
},
{
"token" : "巴",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 5
}
]
}
由上面的分词结果可以发现,"迪丽热巴"是一个明星的名字,有时候,我们在分词的时候并不想拆分他们,只想"迪丽热巴"作为一个关键字进行搜索。
解决方法:将不希望进行分词的词,需要我们自己加入到分词器的字典中。
首先进入到es目录的插件目录下,找到config目录里面的IKAnalyzer.cfg.xml配置文件,往里面添加我们自己的词即可。
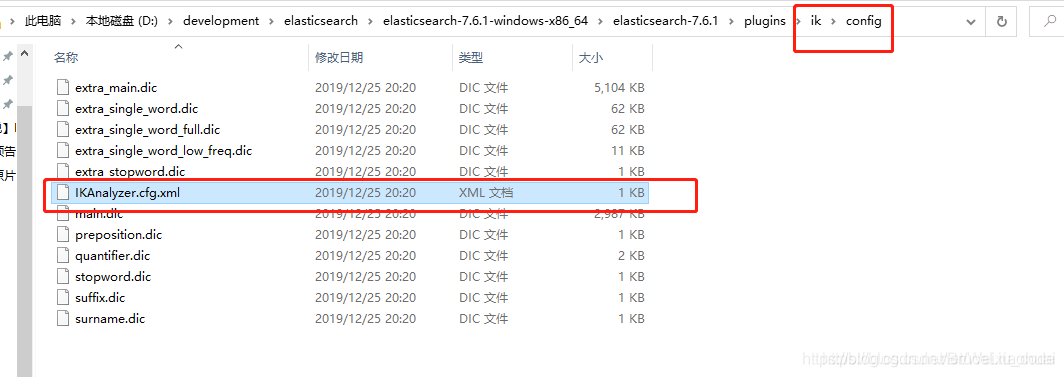
新建dilireba.dic文件,在里面加入"迪丽热巴",如下图:

保存之后,需要将我们的配置文件配置在IKAnalyzer.cfg.xml中:
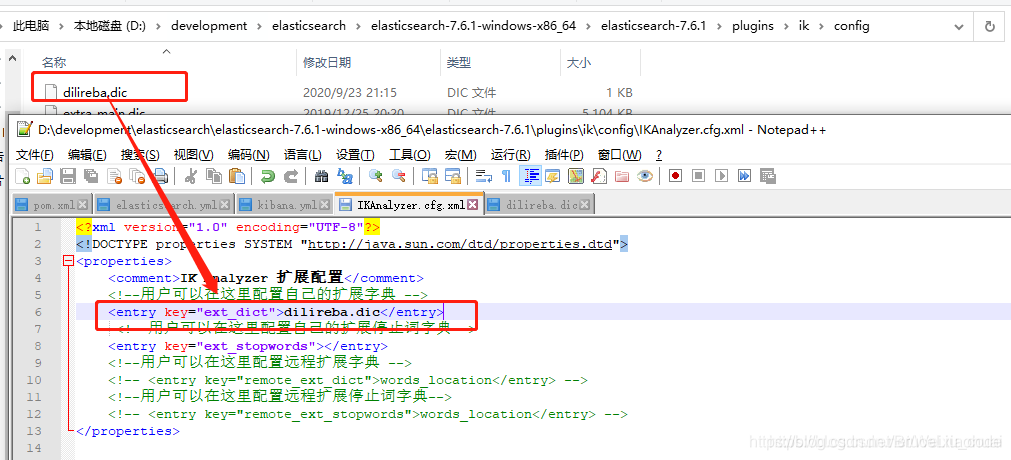
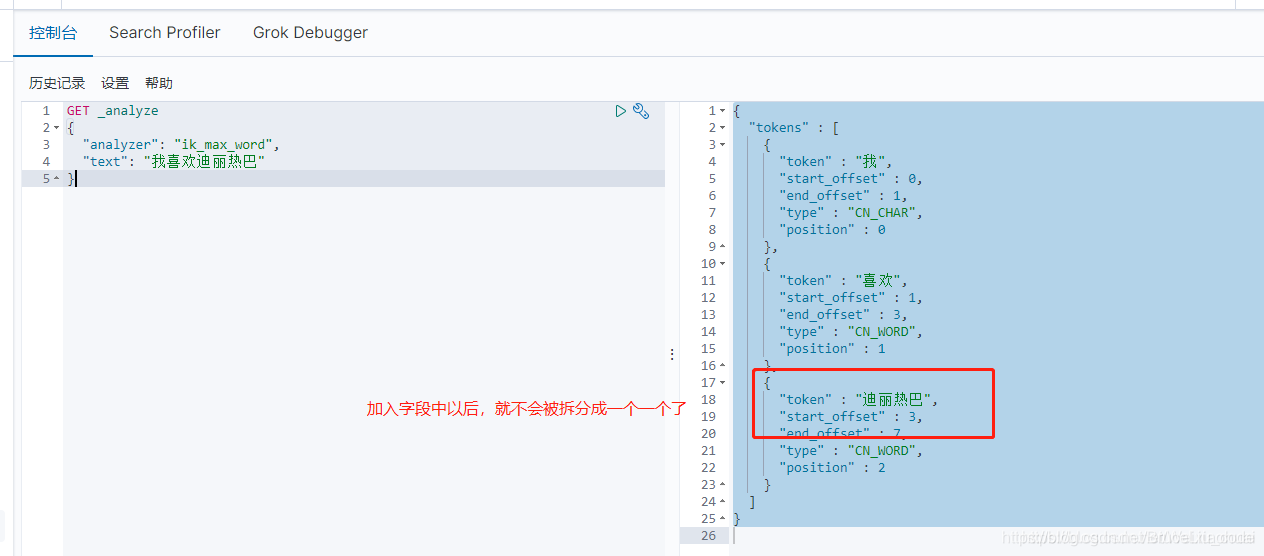
从es的启动日志中可以看到我们自己定义的dilireba.dic字段已经被加载,重启完成后,重新测试"我爱迪丽热巴"进行分词:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











