




 本文介绍了强化学习中的PolicyGradient方法,包括Reinforce算法和Actor-Critic算法,强调其避免传统强化学习方法的挑战,如价值函数的准确性问题和连续状态空间的难解性。PolicyGradient通过梯度下降直接优化期望回报,而Reinforce算法是其一例,使用蒙特卡罗方法进行策略更新,尽管存在高方差问题,但可以通过引入基准函数来缓解。文章还提供了Reinforce算法的伪代码实现,展示了如何构建和训练策略网络。
本文介绍了强化学习中的PolicyGradient方法,包括Reinforce算法和Actor-Critic算法,强调其避免传统强化学习方法的挑战,如价值函数的准确性问题和连续状态空间的难解性。PolicyGradient通过梯度下降直接优化期望回报,而Reinforce算法是其一例,使用蒙特卡罗方法进行策略更新,尽管存在高方差问题,但可以通过引入基准函数来缓解。文章还提供了Reinforce算法的伪代码实现,展示了如何构建和训练策略网络。
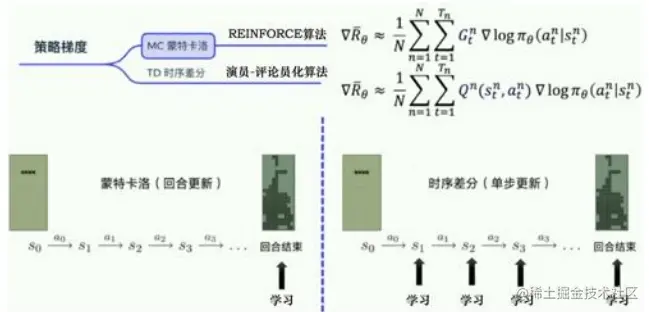
Q-learning和DQN算法都是强化学习中的Value-based的方法,它们都是先经过Q值来选择动作。强化学习中还有另一大类是策略梯度方法(Policy Gradient Methods)。Policy Gradient 是一类直接针对期望回报(Expected Return)通过梯度下降(Gradient Descent)进行策略优化的强化学习方法。这一类方法避免了其他传统强化学习方法所面临的一些困难,比如,没有一个准确的价值函数,或者由于连续的状态和动作空间,以及状态信息的不确定性而导致的难解性(Intractability)。其中最著名的就是Policy Gradient,Policy Gradient算法又可以根据更新方式分为两大类:
蒙特卡罗更新方法:Reinfoce算法(回合更新)
时序差分更新方法:Actor-Critic算法(单步更新)
回顾蒙特卡罗方法和时序差分方法
蒙特卡罗方法可以理解为算法完成一个回合之后,再利用这个回合的数据去学习,做一次更新。因为我们已经获得了整个回合的数据,所以也能够获得每一个步骤的奖励,我们可以很方便地计算每个步骤的未来总奖励,��Gt。��Gt是未来总奖励,代表从这个步骤开始,我们能获得的奖励之和。�1G1代表我们从第一步开始,往后能够获得的总奖励。�2G2代表从第二步开始,往后能够获得的总奖励。
相比蒙特卡罗方法一个回合更新一次,时序差分方法是每个步骤更新一次,即每走一步,更新一次, 时序差分方法的更新频率更高。时序差分方法使用Q函数来近似地表示未来总奖励��Gt。
Reinfoce算法原理
Reinfoce使用蒙特卡罗方法估计每个状态下采取动作所获得的奖励期望值,然后用这些估计值计算策略梯度并更新策略参数。因为Reinfoce算法是一种无模型算法,它不需要对环境建立模型,也不需要预测值函数等中间步骤,相比其他强化学习算法更加简单和直接。
Reinfoce算法在策略的参数空间中直观地通过梯度上升的方法逐步提高策略的性能。
▽�(�)=��∼��[∑�′=0∞▽������(��′∣��′)��′∑�=�′∞��−�′��]▽J(θ)=Eτ∼πθ[t′=0∑∞▽θl
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2302
2302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











