




Miao Fan, Yeqi Bai, Mingming Sun, Ping Li
Cognitive Computing Lab
Baidu Research
No.10 Xibeiwang East Road, Beijing, 10085, China
10900 NE 8th St, Bellevue, WA 98004, USA
{fanmiao,v_baiyeqi,sunmingming01,liping11}@baidu.com
我们可以首先采用现成的软件(例如,斯坦福 CoreNLP [10])来发现感兴趣的实体,
它通常被制定为识别出现在自由文本句子中的两个感兴趣实体之间的关系的任务。
RC 的有前途的性能仅仅是在公共关系上获得的。
明茨等人。 [11] 提出了远程监督范式,通过一些启发式对齐规则 1 用现有知识库中的关系自动标记自由文本句子以构建训练数据。然而,它自然会遇到不正确注释的问题。
少数样本 RC 模型有望获得相当大的准确性,由长尾关系注释的极少数实例支持,而无需从头开始学习。
在这里我们可以利用一个少样本 RC 模型 M 来判断查询实例/句子是否提到了支持集给出的 5 个关系中的任何类型(每个关系 1 个样本/实例)。小样本 RC 的独特之处在于模型 M 是由其他关系标记的实例训练的,其中不包括 5 个关系。
对于每个句子,都预先标明了头部实体(蓝色)和尾部实体(红色)。
给定一个查询实例,少样本 RC 模型负责根据支持集选择实例表达的正确关系(从 R1 到 R5)。
在本文中,我们分别从细粒度特征生成和大边界学习的角度对原始的基于 CNN 的 [23] ProtoNet 进行了两次更新,旨在提高小样本 RC 模型在识别长距离上的泛化能力。 -尾关系。
但是,我们认为可以通过特定于任务的功能和高级学习目标来进一步改进框架
一个直观但直接的规则
 Figure 1: LM-ProtoNet (FGF)的框架,由两部分组成:(左边) fine-grained features for instance embedding ;(右边) triplet loss for ProtoNet 。在这种情况下,LM-ProtoNet 正在处理一个 3-way(类:A, B, C) -3-shot 的关系分类问题其中 Ac 是A类的中心。
Figure 1: LM-ProtoNet (FGF)的框架,由两部分组成:(左边) fine-grained features for instance embedding ;(右边) triplet loss for ProtoNet 。在这种情况下,LM-ProtoNet 正在处理一个 3-way(类:A, B, C) -3-shot 的关系分类问题其中 Ac 是A类的中心。
2.2 Triplet Loss for Large Margin ProtoNet
RC的原型网络的性能很大程度上取决于句子嵌入的空间分布。因此,我们增加了一个辅助损失函数,迫使 sentence network 和 phrase network 扩大类间距离,缩短类内距离。

where N is the total number of training episodes,训练时N怎么体现的
在这里三元组的anchor是类原型
3.2 Experimental Settings
我们通过观察模型在验证集上的准确性,对框架模型LM-ProtoNet (FGF)的超参数进行微调,并在测试集上评估最佳模型的性能。
3.3 Result Analysis
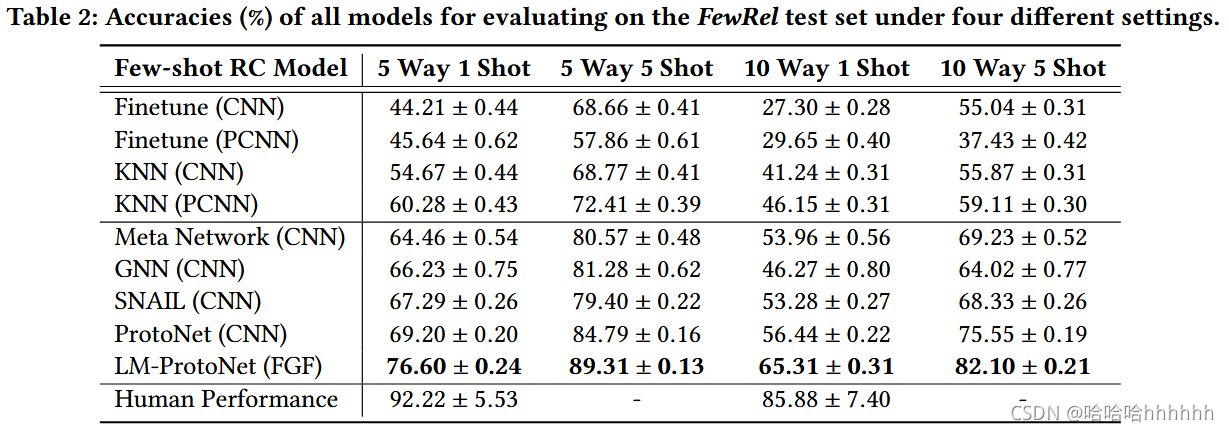
结果表明,CNN [23] 和 PCNN [22] 的性能显着下降,因为对于每种新型关系我们只有 1 或 5 个实例来微调这些深度神经网络,这远不足以进行泛化。 【微调?】
非参数 KNN 在少数场景中可以比深度模型更好地泛化,并且在准确性上有了很大的飞跃。【KNN是非参数?】
4 ABLATION STUDIES
在本节中,我们将探讨我们提出的每个更新的有效性。 鉴于访问FewRel的测试集的限制,我们将原始验证集分为两部分,留下8个关系作为消融研究的测试集。【消融实验用验证集?】
4.1 Fine-grained Features v.s. CNN-basedEmbedding
使用细粒度特征 (FGF) 而不是基于 CNN 的嵌入的直觉是,我们可以通过额外的判别性证据(例如感兴趣的实体和它们周围的上下文)来测量两个实例之间的距离。【这个想法可以,有了一个好的表征】
4.2 Triplet Loss v.s. Softmax Cross-entropy
使用三元组损失作为 ProtoNet 的新学习目标的本质是为训练集中没有出现的长尾关系保持更大的边距。【为未出现的长尾关系保持更大的边距?】
我们相信它可以提高我们的少样本 RC 模型的泛化能力。 在 t-SNE [9] 的帮助下,我们将 7-way-40-shot 场景中的实例嵌入映射到 2D 度量空间。 如图 2 所示,LM-ProtoNet 通过在度量空间中留出足够的空间来为实例获取更多判别性的特征表示。
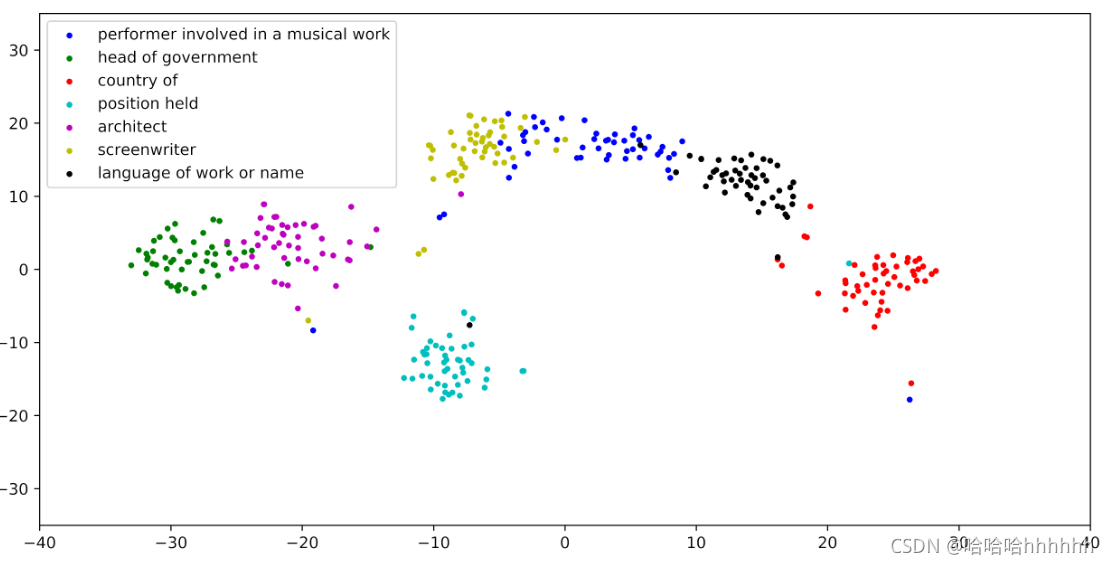
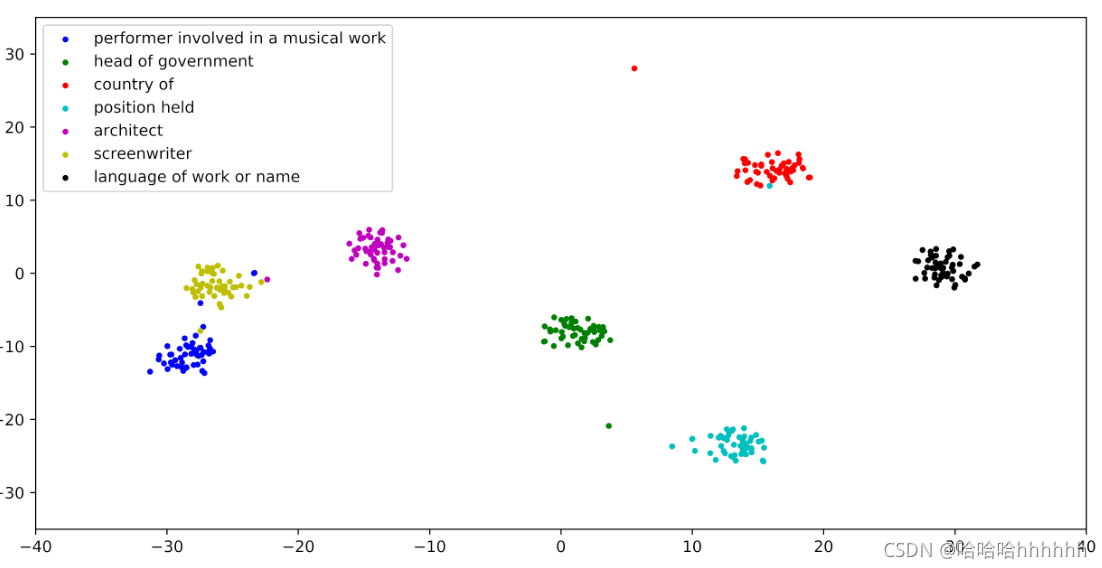
Figure 2: 一个7路40镜头的RC场景,其中支持集实例的嵌入由顶部的Pro- toNet和底部的LM-ProtoNet (FGF)获取。通过使用t-SNE技术将嵌入映射到相同的二维度量空间。

















 2125
2125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









