




 文章描述了一个在Kubernetes环境中,通过创建一个nginxPod并关闭其所在的Node来模拟故障的实验。当Node失效时,Kubernetes会保持对失效Node的跟踪,但不会立即迁移Pod,而是在检测到Pod失效后约5分钟内在其他Node上重新部署。此过程展示了Kubernetes在处理节点故障时的延迟和恢复策略。
文章描述了一个在Kubernetes环境中,通过创建一个nginxPod并关闭其所在的Node来模拟故障的实验。当Node失效时,Kubernetes会保持对失效Node的跟踪,但不会立即迁移Pod,而是在检测到Pod失效后约5分钟内在其他Node上重新部署。此过程展示了Kubernetes在处理节点故障时的延迟和恢复策略。
在《研发工程师玩转Kubernetes——多Worker Node部署》中,我们创建了Master Node: UbunutA,以及四个Worker Node:UbunutB、UbunutC、UbunutD和UbunutE。本节我们将使用Deployment创建只含有一个nginx的Pod,然后关掉它所在的主机以模拟Node失效,观察kubernetes在这种情况下的表现。
创建Node
我们登录到UbuntuA机器,通过下面的清单文件维持只有一个副本的Pod。
# nginx_deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx-container
image: nginx
ports:
- containerPort: 80
然后执行
kubectl create -f nginx_deployment.yaml
deployment.apps/nginx-deployment created
通过下面的指令,我们可以看到这个Pod所在的Node——在UbuntuE上。
kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-8f788645b-n7s6d 1/1 Running 0 3m51s 10.1.226.1 ubuntue <none> <none>
在关闭UbuntuE之前,我们新开两个终端,分别监视Pod和Node的变化
kubectl get pod --watch -o wide
kubectl get node --watch -o wide
关闭Pod所在主机
登录到UbuntuE上,执行
sudo poweroff
查看
等待一段时间,kubernetes察觉到UbuntuE服务器(Node)失效了
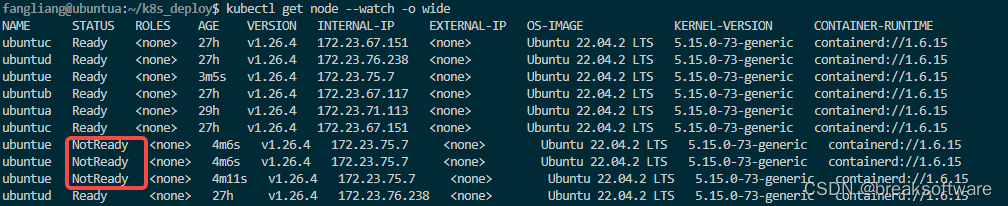
但是Pod的状态并没有立即改变,进而也没立即迁移该Pod。

Kubernetes 会一直保存着失效节点对应的对象,并持续检查该节点是否已经变得健康。
kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
ubuntuc Ready <none> 24h v1.26.4 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=ubuntuc,kubernetes.io/os=linux,microk8s.io/cluster=true,node.kubernetes.io/microk8s-worker=microk8s-worker
ubuntue NotReady <none> 17h v1.26.4 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=ubuntue,kubernetes.io/os=linux,microk8s.io/cluster=true,node.kubernetes.io/microk8s-worker=microk8s-worker
ubuntub Ready <none> 24h v1.26.4 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=ubuntub,kubernetes.io/os=linux,microk8s.io/cluster=true,node.kubernetes.io/microk8s-worker=microk8s-worker
ubuntua Ready <none> 26h v1.26.4 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=ubuntua,kubernetes.io/os=linux,microk8s.io/cluster=true,node.kubernetes.io/microk8s-controlplane=microk8s-controlplane
ubuntud Ready <none> 24h v1.26.4 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=ubuntud,kubernetes.io/os=linux,microk8s.io/cluster=true,node.kubernetes.io/microk8s-worker=microk8s-worker
我们可以手工删除这个失效的Node,这样对应的Pod对象也会被删除,进而触发Deployment新增一个Pod。
kubectl delete nodes ubuntue
node “ubuntue” deleted
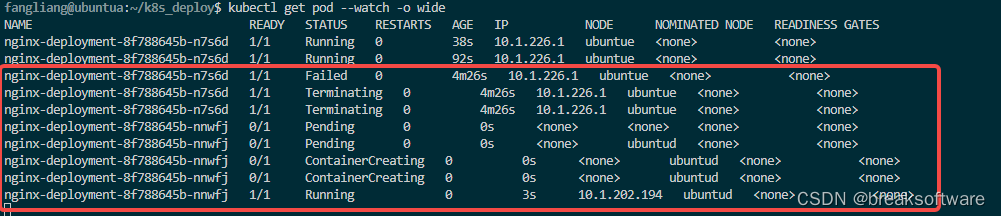
我们再做一次实验,将新Pod所在的Node也关闭,继续查看Pod的变化过程。
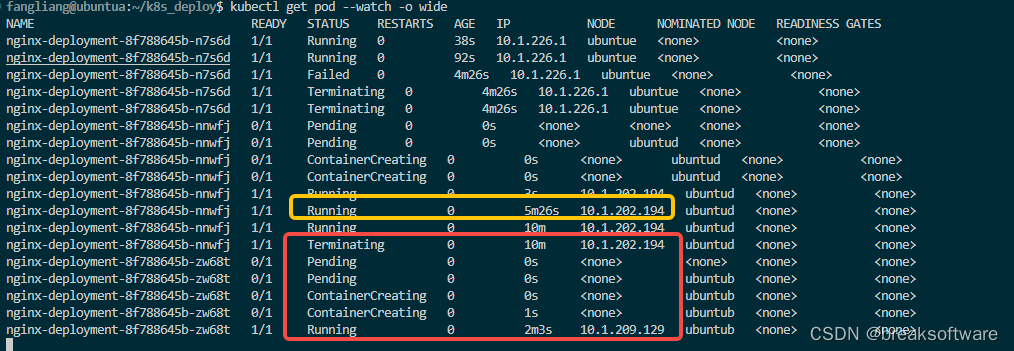
可以看到等待了大于5分钟,kubernetes终于发现Pod失效了。这样在其维持着失效的Node UbuntuD情况下,也会发现Pod无效,进而在可用的Node上部署新的Pod。
kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-8f788645b-nnwfj 1/1 Terminating 0 37m 10.1.202.194 ubuntud <none> <none>
nginx-deployment-8f788645b-zw68t 1/1 Running 0 27m 10.1.209.129 ubuntub <none> <none>
总体而言,Node失效后,Kubernetes会相对快速的发现其失效,但是会一直维持着这个Node对象,且持续检查它的状态。但是Kubernetes并不会快速发现部署于失效Node上的Pod也失效了,大概要等待5分钟左右才会在其他可用的Node上部署Pod,而原来的Pod将一直处于Terminating状态。


















 1351
1351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











