




 本文深入解析了Pipeline Recovery机制,一种确保数据流在Hadoop分布式文件系统中即使遇到DataNode故障也能持续运行的关键策略。文章详细介绍了流水线在不同阶段可能遭遇的三种失败情况及其应对措施,包括架设阶段、数据传输阶段和关闭阶段的失败恢复流程。
本文深入解析了Pipeline Recovery机制,一种确保数据流在Hadoop分布式文件系统中即使遇到DataNode故障也能持续运行的关键策略。文章详细介绍了流水线在不同阶段可能遭遇的三种失败情况及其应对措施,包括架设阶段、数据传输阶段和关闭阶段的失败恢复流程。
Pipeline Recovery
流水线是由DataNode串联而成的,就像一条水管,数据(Packets)从一端流进去,依次经过流水线上的各个DataNode,当最后一个DataNode收到数据,将会发出ACK(Acknowledge)给前一个
DataNode,前一个DataNode收到ACK后又会向前一个DataNode发送ACK。回复(ACK)相反地从尾端流回执行写操作的客户端。那么,只要是流水线上一个DataNode宕机了,都会导致整个PipeLine的DataStream无法正常运转。就像自行车链条,一个关节坏了,整个链条就转不起来。
所以,我们需要PipeLine Recovery机制,保证DataStream继续运作。
基本流程如下图:
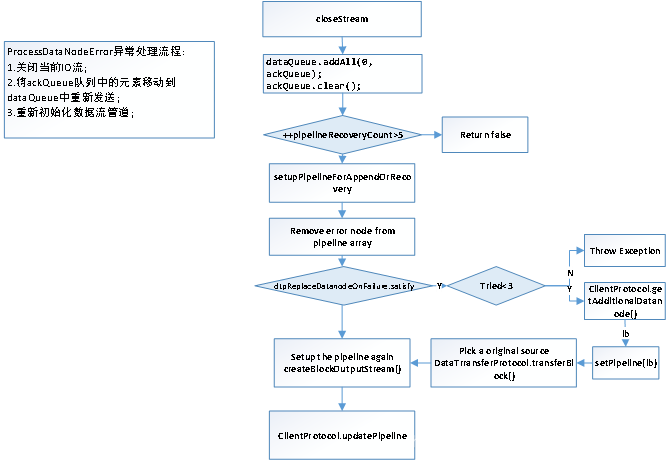
流水线恢复按阶段不同分为3种:
1.架设流水线阶段失败
2.流水线传输数据阶段失败
3.流水线关闭阶段失败
A. 架设阶段失败:
分情况:
1.流水线是用来创建新的Block的:客户端放弃掉(Abandon)新建的Block,重新向NameNode申请一块Block并且将重新架构流水线。
2.流水线是用来对已有文件写入数据的:客户端重新架构流水线,并且把Block的BGS+1
B. 传输数据阶段失败:
1.客户端排除掉出错的DataNode(称之为BadNode),BadNode会通过断开与客户端的TCP连接的方式将自己隔离出流水线,并且尽可能地将已经确认(收到ACK)的数据写入磁盘,最后关闭文件。
2.客户端检测到流水线上发送回来的ACK不对数,少了某个DataNode,会停止发送Packet
3.客户端将重新架设流水线,并且根据 fs.client.block.write.replace-datanode-on-failure.policy/enable 的设置决定是否寻找新的节点代替BadNode,客户端向NameNode申请新的BGS,这个BGS将在重新架设流水线成功后,成为Replica和Block的BGS。这样BadNode的Rplica的BGS就和还健在的DataNode,以及NameNode那边Block的BGS相差1,如果以后BadNode重启,加入流水线,那么因为Replica的版本(BGS是Replica的版本标识)过老,而被要求删除(或许能够恢复,如果客户端也挂了)
4.客户端重新发送数据,从哪里开始发送呢?假如客户端最后收到ACK的数据Packet是P,那么重新从P后开始发送数据。
5.DataNode如果接收到4中发来的Packet时,发现自己已经有这部分数据了,就会简单的把这个Packet发给下游。
C. 关闭阶段失败:
1.客户端尝试新建流水线,用来告知DataNode应该把Replica给FINALIZE掉
2.DataNode等待客户端发送endBlock包,这个包是用来告诉DataNode,Block传输完成的,当DataNode收到这个包,将把Replica设置成FINALIZED。
3.DataNode在关闭网络连接前,会向客户端发送endBlock包的确认包

















 812
812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









